samplesheet-parser 0.2.0__tar.gz → 0.3.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/.github/workflows/ci.yml +2 -2
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/PKG-INFO +154 -9
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/README.md +149 -5
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/parse_examples.py +31 -13
- samplesheet_parser-0.3.0/examples/sample_sheets/README.md +195 -0
- samplesheet_parser-0.3.0/examples/sample_sheets/v1_with_lab_qc_settings.csv +35 -0
- samplesheet_parser-0.3.0/examples/sample_sheets/v1_with_manifests.csv +32 -0
- samplesheet_parser-0.3.0/examples/sample_sheets/v2_with_cloud_settings.csv +32 -0
- samplesheet_parser-0.3.0/examples/sample_sheets/v2_with_pipeline_settings.csv +32 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/pyproject.toml +10 -7
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/__init__.py +3 -0
- samplesheet_parser-0.3.0/samplesheet_parser/cli.py +427 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/enums.py +5 -5
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/factory.py +2 -1
- samplesheet_parser-0.3.0/samplesheet_parser/merger.py +683 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/parsers/v1.py +188 -56
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/parsers/v2.py +130 -7
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/validators.py +10 -9
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/conftest.py +243 -1
- samplesheet_parser-0.3.0/tests/test_cli.py +631 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_converter.py +47 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_diff.py +35 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_factory.py +11 -0
- samplesheet_parser-0.3.0/tests/test_merger.py +1271 -0
- samplesheet_parser-0.3.0/tests/test_parsers/test_v1.py +530 -0
- samplesheet_parser-0.3.0/tests/test_parsers/test_v2.py +578 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_validators/test_validators.py +34 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_writer.py +110 -0
- samplesheet_parser-0.2.0/examples/sample_sheets/README.md +0 -92
- samplesheet_parser-0.2.0/tests/test_parsers/test_v1.py +0 -296
- samplesheet_parser-0.2.0/tests/test_parsers/test_v2.py +0 -270
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/.github/workflows/copilot-instructions.md +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/.gitignore +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/CHANGELOG.md +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/CONTRIBUTING.md +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/LICENSE +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v1_dual_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v1_multi_lane.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v1_single_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v2_nextseq_single_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v2_novaseq_x_dual_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v2_with_index_umi.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/examples/sample_sheets/v2_with_read_umi.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/images/samplesheet_parser_overview.png +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/converter.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/diff.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/parsers/__init__.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/samplesheet_parser/writer.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/scripts/demo_converter.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/scripts/demo_diff.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/scripts/demo_writer.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/__init__.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/fixtures/SampleSheet_v1_dual_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/fixtures/SampleSheet_v2_dual_index.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/fixtures/SampleSheet_v2_modified.csv +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_parsers/__init__.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_validators/__init__.py +0 -0
- {samplesheet_parser-0.2.0 → samplesheet_parser-0.3.0}/tests/test_validators/test_hamming.py +0 -0
|
@@ -13,7 +13,7 @@ jobs:
|
|
|
13
13
|
runs-on: ubuntu-latest
|
|
14
14
|
strategy:
|
|
15
15
|
matrix:
|
|
16
|
-
python-version: ["3.
|
|
16
|
+
python-version: ["3.12"]
|
|
17
17
|
|
|
18
18
|
steps:
|
|
19
19
|
- uses: actions/checkout@v4
|
|
@@ -24,7 +24,7 @@ jobs:
|
|
|
24
24
|
python-version: ${{ matrix.python-version }}
|
|
25
25
|
|
|
26
26
|
- name: Install dependencies
|
|
27
|
-
run: pip install -e ".[dev]"
|
|
27
|
+
run: pip install -e ".[dev,cli]"
|
|
28
28
|
|
|
29
29
|
- name: Lint with ruff
|
|
30
30
|
run: ruff check samplesheet_parser/
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: samplesheet-parser
|
|
3
|
-
Version: 0.
|
|
3
|
+
Version: 0.3.0
|
|
4
4
|
Summary: Format-agnostic parser for Illumina SampleSheet.csv files — supports IEM V1 and BCLConvert V2
|
|
5
5
|
Project-URL: Homepage, https://github.com/chaitanyakasaraneni/samplesheet-parser
|
|
6
6
|
Project-URL: Documentation, https://illumina-samplesheet.readthedocs.io
|
|
@@ -33,26 +33,27 @@ Classifier: Intended Audience :: Developers
|
|
|
33
33
|
Classifier: Intended Audience :: Science/Research
|
|
34
34
|
Classifier: License :: OSI Approved :: Apache Software License
|
|
35
35
|
Classifier: Programming Language :: Python :: 3
|
|
36
|
-
Classifier: Programming Language :: Python :: 3.10
|
|
37
|
-
Classifier: Programming Language :: Python :: 3.11
|
|
38
36
|
Classifier: Programming Language :: Python :: 3.12
|
|
39
37
|
Classifier: Topic :: Scientific/Engineering :: Bio-Informatics
|
|
40
38
|
Classifier: Typing :: Typed
|
|
41
|
-
Requires-Python: >=3.
|
|
39
|
+
Requires-Python: >=3.12
|
|
42
40
|
Requires-Dist: loguru>=0.7
|
|
41
|
+
Provides-Extra: cli
|
|
42
|
+
Requires-Dist: typer>=0.9; extra == 'cli'
|
|
43
43
|
Provides-Extra: dev
|
|
44
44
|
Requires-Dist: black>=24.0; extra == 'dev'
|
|
45
45
|
Requires-Dist: mypy>=1.8; extra == 'dev'
|
|
46
46
|
Requires-Dist: pytest-cov>=4.1; extra == 'dev'
|
|
47
47
|
Requires-Dist: pytest>=7.4; extra == 'dev'
|
|
48
48
|
Requires-Dist: ruff>=0.3; extra == 'dev'
|
|
49
|
+
Requires-Dist: typer>=0.9; extra == 'dev'
|
|
49
50
|
Description-Content-Type: text/markdown
|
|
50
51
|
|
|
51
52
|
# samplesheet-parser
|
|
52
53
|
|
|
53
54
|
**Format-agnostic parser for Illumina SampleSheet.csv files.**
|
|
54
55
|
|
|
55
|
-
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, diff comparison,
|
|
56
|
+
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, diff comparison, multi-sheet merging, programmatic sheet creation, and a full-featured CLI.
|
|
56
57
|
|
|
57
58
|
[](https://pypi.org/project/samplesheet-parser/)
|
|
58
59
|
[](https://www.python.org/downloads/)
|
|
@@ -62,7 +63,7 @@ Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConver
|
|
|
62
63
|
|
|
63
64
|
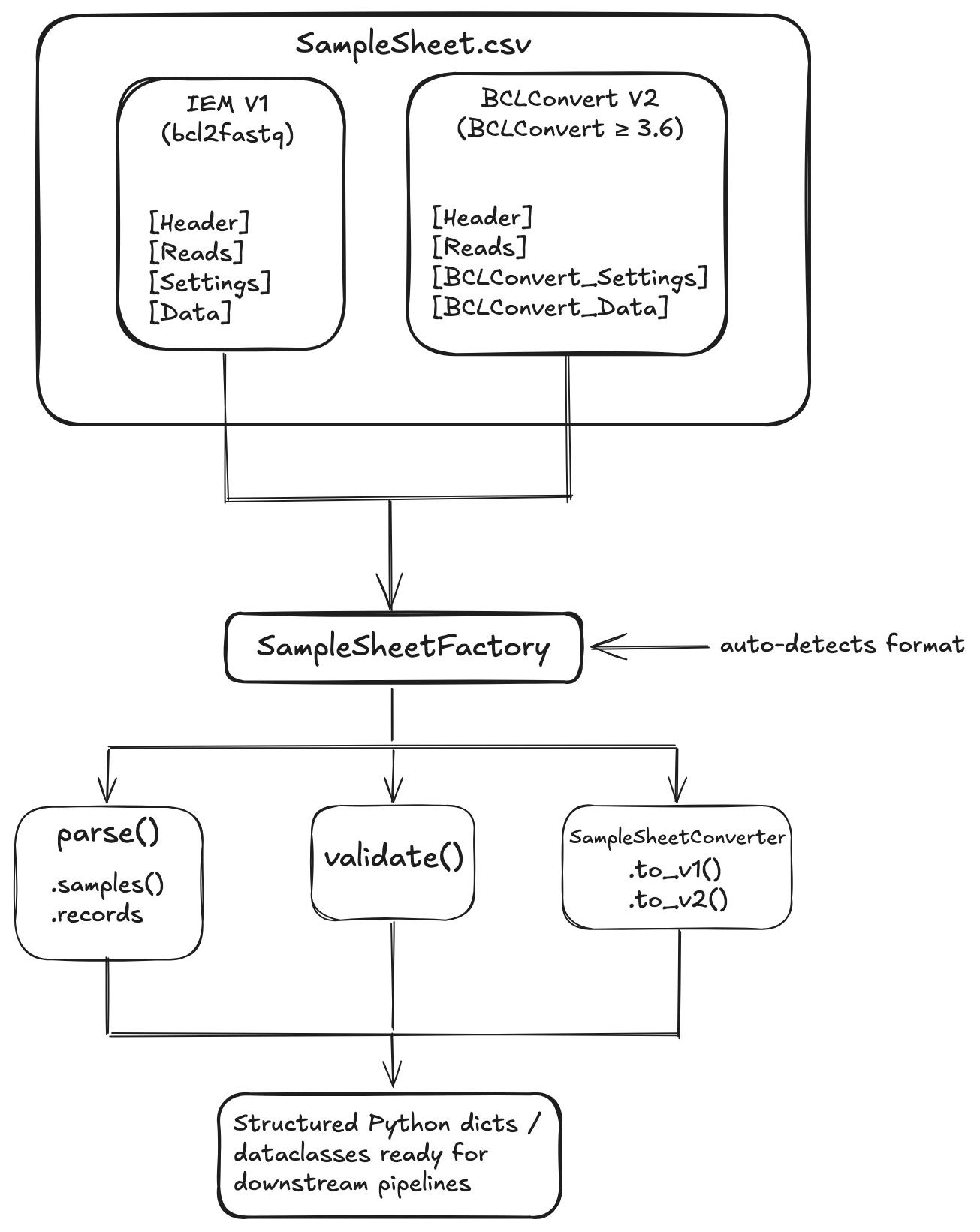
|
|
64
65
|
|
|
65
|
-
*`SampleSheetFactory` auto-detects the format and routes to the correct parser. Both formats share a common interface — `SampleSheetConverter` handles bidirectional conversion, `SampleSheetValidator` catches index and adapter issues, `SampleSheetDiff` compares two sheets across any combination of V1/V2 formats, and `SampleSheetWriter` builds or edits sheets programmatically.*
|
|
66
|
+
*`SampleSheetFactory` auto-detects the format and routes to the correct parser. Both formats share a common interface — `SampleSheetConverter` handles bidirectional conversion, `SampleSheetValidator` catches index and adapter issues, `SampleSheetDiff` compares two sheets across any combination of V1/V2 formats, `SampleSheetMerger` combines multiple per-project sheets into one, and `SampleSheetWriter` builds or edits sheets programmatically. The `samplesheet` CLI exposes all of this from the shell.*
|
|
66
67
|
|
|
67
68
|
---
|
|
68
69
|
|
|
@@ -77,10 +78,14 @@ Existing tools either hard-code one format or require the caller to know which f
|
|
|
77
78
|
## Installation
|
|
78
79
|
|
|
79
80
|
```bash
|
|
81
|
+
# Core library only
|
|
80
82
|
pip install samplesheet-parser
|
|
83
|
+
|
|
84
|
+
# With the CLI (adds typer)
|
|
85
|
+
pip install "samplesheet-parser[cli]"
|
|
81
86
|
```
|
|
82
87
|
|
|
83
|
-
Requires Python 3.10+. No mandatory dependencies beyond `loguru`.
|
|
88
|
+
Requires Python 3.10+. No mandatory runtime dependencies beyond `loguru`.
|
|
84
89
|
|
|
85
90
|
---
|
|
86
91
|
|
|
@@ -227,6 +232,106 @@ converts format while editing.
|
|
|
227
232
|
|
|
228
233
|
---
|
|
229
234
|
|
|
235
|
+
|
|
236
|
+
### Merge multiple sheets
|
|
237
|
+
|
|
238
|
+
Combine per-project sheets from a single run into one merged sheet.
|
|
239
|
+
Conflicts (index collisions, read-length mismatches, adapter disagreements)
|
|
240
|
+
are surfaced as structured results rather than silent failures.
|
|
241
|
+
|
|
242
|
+
```python
|
|
243
|
+
from samplesheet_parser import SampleSheetMerger
|
|
244
|
+
from samplesheet_parser.enums import SampleSheetVersion
|
|
245
|
+
|
|
246
|
+
result = (
|
|
247
|
+
SampleSheetMerger(target_version=SampleSheetVersion.V2)
|
|
248
|
+
.add("ProjectA.csv")
|
|
249
|
+
.add("ProjectB.csv")
|
|
250
|
+
.add("ProjectC.csv")
|
|
251
|
+
.merge("SampleSheet_combined.csv")
|
|
252
|
+
)
|
|
253
|
+
|
|
254
|
+
print(result.summary())
|
|
255
|
+
# Merged 3 sheet(s) → SampleSheet_combined.csv (12 samples) — 0 conflict(s), 0 warning(s)
|
|
256
|
+
|
|
257
|
+
if result.has_conflicts:
|
|
258
|
+
for c in result.conflicts:
|
|
259
|
+
print(c)
|
|
260
|
+
# [CONFLICT] INDEX_COLLISION: Index 'ATTACTCG+TATAGCCT' in lane 1
|
|
261
|
+
# appears in both ProjectA.csv and ProjectB.csv
|
|
262
|
+
|
|
263
|
+
for w in result.warnings:
|
|
264
|
+
print(w)
|
|
265
|
+
# [WARNING] MIXED_FORMAT: Input sheets are a mix of V1 and V2 formats.
|
|
266
|
+
# All will be converted to V2 for output.
|
|
267
|
+
```
|
|
268
|
+
|
|
269
|
+
Mixed V1/V2 inputs are automatically converted to the target format.
|
|
270
|
+
Pass `abort_on_conflicts=False` to write output even when conflicts exist.
|
|
271
|
+
|
|
272
|
+
---
|
|
273
|
+
|
|
274
|
+
## CLI
|
|
275
|
+
|
|
276
|
+
Install the CLI extra and use the `samplesheet` command directly from the shell:
|
|
277
|
+
|
|
278
|
+
```bash
|
|
279
|
+
pip install "samplesheet-parser[cli]"
|
|
280
|
+
```
|
|
281
|
+
|
|
282
|
+
### validate
|
|
283
|
+
|
|
284
|
+
```bash
|
|
285
|
+
# Text output — exit 0 if clean, exit 1 if errors
|
|
286
|
+
samplesheet validate SampleSheet.csv
|
|
287
|
+
|
|
288
|
+
# JSON output for CI pipelines
|
|
289
|
+
samplesheet validate SampleSheet.csv --format json
|
|
290
|
+
```
|
|
291
|
+
|
|
292
|
+
### convert
|
|
293
|
+
|
|
294
|
+
```bash
|
|
295
|
+
samplesheet convert SampleSheet_v1.csv --to v2 --output SampleSheet_v2.csv
|
|
296
|
+
samplesheet convert SampleSheet_v2.csv --to v1 --output SampleSheet_v1.csv
|
|
297
|
+
```
|
|
298
|
+
|
|
299
|
+
### diff
|
|
300
|
+
|
|
301
|
+
```bash
|
|
302
|
+
# Exit 0 if identical, exit 1 if any differences detected
|
|
303
|
+
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv
|
|
304
|
+
|
|
305
|
+
# JSON output for scripting
|
|
306
|
+
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv --format json
|
|
307
|
+
```
|
|
308
|
+
|
|
309
|
+
### merge
|
|
310
|
+
|
|
311
|
+
```bash
|
|
312
|
+
# Clean merge — exit 0
|
|
313
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv
|
|
314
|
+
|
|
315
|
+
# Merge three sheets to V1 format
|
|
316
|
+
samplesheet merge ProjectA.csv ProjectB.csv ProjectC.csv --to v1 --output combined.csv
|
|
317
|
+
|
|
318
|
+
# Write output even if conflicts are found
|
|
319
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --force
|
|
320
|
+
|
|
321
|
+
# JSON output
|
|
322
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --format json
|
|
323
|
+
```
|
|
324
|
+
|
|
325
|
+
**Exit codes** (all commands):
|
|
326
|
+
|
|
327
|
+
| Code | Meaning |
|
|
328
|
+
|---|---|
|
|
329
|
+
| `0` | Success / no issues |
|
|
330
|
+
| `1` | Errors found (invalid sheet, conflicts, differences detected) |
|
|
331
|
+
| `2` | Usage error (missing file, bad argument) |
|
|
332
|
+
|
|
333
|
+
---
|
|
334
|
+
|
|
230
335
|
## Format detection logic
|
|
231
336
|
|
|
232
337
|
The factory uses a three-step detection strategy — no format hints required from the caller:
|
|
@@ -274,6 +379,22 @@ result = ValidationResult()
|
|
|
274
379
|
SampleSheetValidator()._check_index_distances(samples, result, min_distance=4)
|
|
275
380
|
```
|
|
276
381
|
|
|
382
|
+
---
|
|
383
|
+
|
|
384
|
+
## Merger conflict and warning codes
|
|
385
|
+
|
|
386
|
+
| Code | Level | Description |
|
|
387
|
+
|---|---|---|
|
|
388
|
+
| `PARSE_ERROR` | conflict | An input sheet could not be parsed |
|
|
389
|
+
| `INDEX_COLLISION` | conflict | The same index appears in the same lane across two sheets |
|
|
390
|
+
| `READ_LENGTH_CONFLICT` | conflict | Sheets specify different read lengths or cycle counts |
|
|
391
|
+
| `MERGE_VALIDATION_ERROR` | conflict | Post-merge validation of the combined sheet failed |
|
|
392
|
+
| `MIXED_FORMAT` | warning | Input sheets are a mix of V1 and V2 formats |
|
|
393
|
+
| `INDEX_DISTANCE_TOO_LOW` | warning | Cross-sheet index pair has Hamming distance below threshold |
|
|
394
|
+
| `ADAPTER_CONFLICT` | warning | Adapter sequences differ between sheets (primary sheet adapters are used) |
|
|
395
|
+
| `INCOMPLETE_SAMPLE_RECORD` | warning | A sample row is missing `Sample_ID` or index and was skipped |
|
|
396
|
+
|
|
397
|
+
|
|
277
398
|
---
|
|
278
399
|
|
|
279
400
|
## Diff
|
|
@@ -411,12 +532,36 @@ sheet.get_read_structure() # → ReadStructure dataclass
|
|
|
411
532
|
|
|
412
533
|
---
|
|
413
534
|
|
|
535
|
+
---
|
|
536
|
+
|
|
537
|
+
### `SampleSheetMerger`
|
|
538
|
+
|
|
539
|
+
| Method / attribute | Returns | Description |
|
|
540
|
+
|---|---|---|
|
|
541
|
+
| `SampleSheetMerger(target_version=)` | — | Instantiate; default target is `SampleSheetVersion.V2` |
|
|
542
|
+
| `add(path)` | `self` | Register an input sheet path (fluent) |
|
|
543
|
+
| `merge(output_path, *, validate=True, abort_on_conflicts=True)` | `MergeResult` | Run the merge and write output |
|
|
544
|
+
|
|
545
|
+
### `MergeResult`
|
|
546
|
+
|
|
547
|
+
| Attribute / method | Type | Description |
|
|
548
|
+
|---|---|---|
|
|
549
|
+
| `has_conflicts` | `bool` | `True` if any conflict was recorded |
|
|
550
|
+
| `sample_count` | `int` | Number of samples in the merged output |
|
|
551
|
+
| `output_path` | `Path \| None` | Path written; `None` if write was aborted |
|
|
552
|
+
| `source_versions` | `dict[str, str]` | Per-input-file detected format version |
|
|
553
|
+
| `conflicts` | `list[MergeConflict]` | Structured conflict records |
|
|
554
|
+
| `warnings` | `list[MergeConflict]` | Structured warning records |
|
|
555
|
+
| `summary()` | `str` | Human-readable one-line summary |
|
|
556
|
+
|
|
557
|
+
---
|
|
558
|
+
|
|
414
559
|
## Contributing
|
|
415
560
|
|
|
416
561
|
```bash
|
|
417
562
|
git clone https://github.com/chaitanyakasaraneni/samplesheet-parser
|
|
418
563
|
cd samplesheet-parser
|
|
419
|
-
pip install -e ".[dev]"
|
|
564
|
+
pip install -e ".[dev,cli]"
|
|
420
565
|
|
|
421
566
|
# Run tests
|
|
422
567
|
pytest tests/ -v
|
|
@@ -439,7 +584,7 @@ See [CONTRIBUTING.md](CONTRIBUTING.md) for the full local testing guide and PR c
|
|
|
439
584
|
title = {samplesheet-parser: Format-agnostic parser for Illumina SampleSheet.csv},
|
|
440
585
|
year = {2026},
|
|
441
586
|
url = {https://github.com/chaitanyakasaraneni/samplesheet-parser},
|
|
442
|
-
version = {0.
|
|
587
|
+
version = {0.3.0}
|
|
443
588
|
}
|
|
444
589
|
```
|
|
445
590
|
|
|
@@ -2,7 +2,7 @@
|
|
|
2
2
|
|
|
3
3
|
**Format-agnostic parser for Illumina SampleSheet.csv files.**
|
|
4
4
|
|
|
5
|
-
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, diff comparison,
|
|
5
|
+
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, diff comparison, multi-sheet merging, programmatic sheet creation, and a full-featured CLI.
|
|
6
6
|
|
|
7
7
|
[](https://pypi.org/project/samplesheet-parser/)
|
|
8
8
|
[](https://www.python.org/downloads/)
|
|
@@ -12,7 +12,7 @@ Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConver
|
|
|
12
12
|
|
|
13
13
|

|
|
14
14
|
|
|
15
|
-
*`SampleSheetFactory` auto-detects the format and routes to the correct parser. Both formats share a common interface — `SampleSheetConverter` handles bidirectional conversion, `SampleSheetValidator` catches index and adapter issues, `SampleSheetDiff` compares two sheets across any combination of V1/V2 formats, and `SampleSheetWriter` builds or edits sheets programmatically.*
|
|
15
|
+
*`SampleSheetFactory` auto-detects the format and routes to the correct parser. Both formats share a common interface — `SampleSheetConverter` handles bidirectional conversion, `SampleSheetValidator` catches index and adapter issues, `SampleSheetDiff` compares two sheets across any combination of V1/V2 formats, `SampleSheetMerger` combines multiple per-project sheets into one, and `SampleSheetWriter` builds or edits sheets programmatically. The `samplesheet` CLI exposes all of this from the shell.*
|
|
16
16
|
|
|
17
17
|
---
|
|
18
18
|
|
|
@@ -27,10 +27,14 @@ Existing tools either hard-code one format or require the caller to know which f
|
|
|
27
27
|
## Installation
|
|
28
28
|
|
|
29
29
|
```bash
|
|
30
|
+
# Core library only
|
|
30
31
|
pip install samplesheet-parser
|
|
32
|
+
|
|
33
|
+
# With the CLI (adds typer)
|
|
34
|
+
pip install "samplesheet-parser[cli]"
|
|
31
35
|
```
|
|
32
36
|
|
|
33
|
-
Requires Python 3.10+. No mandatory dependencies beyond `loguru`.
|
|
37
|
+
Requires Python 3.10+. No mandatory runtime dependencies beyond `loguru`.
|
|
34
38
|
|
|
35
39
|
---
|
|
36
40
|
|
|
@@ -177,6 +181,106 @@ converts format while editing.
|
|
|
177
181
|
|
|
178
182
|
---
|
|
179
183
|
|
|
184
|
+
|
|
185
|
+
### Merge multiple sheets
|
|
186
|
+
|
|
187
|
+
Combine per-project sheets from a single run into one merged sheet.
|
|
188
|
+
Conflicts (index collisions, read-length mismatches, adapter disagreements)
|
|
189
|
+
are surfaced as structured results rather than silent failures.
|
|
190
|
+
|
|
191
|
+
```python
|
|
192
|
+
from samplesheet_parser import SampleSheetMerger
|
|
193
|
+
from samplesheet_parser.enums import SampleSheetVersion
|
|
194
|
+
|
|
195
|
+
result = (
|
|
196
|
+
SampleSheetMerger(target_version=SampleSheetVersion.V2)
|
|
197
|
+
.add("ProjectA.csv")
|
|
198
|
+
.add("ProjectB.csv")
|
|
199
|
+
.add("ProjectC.csv")
|
|
200
|
+
.merge("SampleSheet_combined.csv")
|
|
201
|
+
)
|
|
202
|
+
|
|
203
|
+
print(result.summary())
|
|
204
|
+
# Merged 3 sheet(s) → SampleSheet_combined.csv (12 samples) — 0 conflict(s), 0 warning(s)
|
|
205
|
+
|
|
206
|
+
if result.has_conflicts:
|
|
207
|
+
for c in result.conflicts:
|
|
208
|
+
print(c)
|
|
209
|
+
# [CONFLICT] INDEX_COLLISION: Index 'ATTACTCG+TATAGCCT' in lane 1
|
|
210
|
+
# appears in both ProjectA.csv and ProjectB.csv
|
|
211
|
+
|
|
212
|
+
for w in result.warnings:
|
|
213
|
+
print(w)
|
|
214
|
+
# [WARNING] MIXED_FORMAT: Input sheets are a mix of V1 and V2 formats.
|
|
215
|
+
# All will be converted to V2 for output.
|
|
216
|
+
```
|
|
217
|
+
|
|
218
|
+
Mixed V1/V2 inputs are automatically converted to the target format.
|
|
219
|
+
Pass `abort_on_conflicts=False` to write output even when conflicts exist.
|
|
220
|
+
|
|
221
|
+
---
|
|
222
|
+
|
|
223
|
+
## CLI
|
|
224
|
+
|
|
225
|
+
Install the CLI extra and use the `samplesheet` command directly from the shell:
|
|
226
|
+
|
|
227
|
+
```bash
|
|
228
|
+
pip install "samplesheet-parser[cli]"
|
|
229
|
+
```
|
|
230
|
+
|
|
231
|
+
### validate
|
|
232
|
+
|
|
233
|
+
```bash
|
|
234
|
+
# Text output — exit 0 if clean, exit 1 if errors
|
|
235
|
+
samplesheet validate SampleSheet.csv
|
|
236
|
+
|
|
237
|
+
# JSON output for CI pipelines
|
|
238
|
+
samplesheet validate SampleSheet.csv --format json
|
|
239
|
+
```
|
|
240
|
+
|
|
241
|
+
### convert
|
|
242
|
+
|
|
243
|
+
```bash
|
|
244
|
+
samplesheet convert SampleSheet_v1.csv --to v2 --output SampleSheet_v2.csv
|
|
245
|
+
samplesheet convert SampleSheet_v2.csv --to v1 --output SampleSheet_v1.csv
|
|
246
|
+
```
|
|
247
|
+
|
|
248
|
+
### diff
|
|
249
|
+
|
|
250
|
+
```bash
|
|
251
|
+
# Exit 0 if identical, exit 1 if any differences detected
|
|
252
|
+
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv
|
|
253
|
+
|
|
254
|
+
# JSON output for scripting
|
|
255
|
+
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv --format json
|
|
256
|
+
```
|
|
257
|
+
|
|
258
|
+
### merge
|
|
259
|
+
|
|
260
|
+
```bash
|
|
261
|
+
# Clean merge — exit 0
|
|
262
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv
|
|
263
|
+
|
|
264
|
+
# Merge three sheets to V1 format
|
|
265
|
+
samplesheet merge ProjectA.csv ProjectB.csv ProjectC.csv --to v1 --output combined.csv
|
|
266
|
+
|
|
267
|
+
# Write output even if conflicts are found
|
|
268
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --force
|
|
269
|
+
|
|
270
|
+
# JSON output
|
|
271
|
+
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --format json
|
|
272
|
+
```
|
|
273
|
+
|
|
274
|
+
**Exit codes** (all commands):
|
|
275
|
+
|
|
276
|
+
| Code | Meaning |
|
|
277
|
+
|---|---|
|
|
278
|
+
| `0` | Success / no issues |
|
|
279
|
+
| `1` | Errors found (invalid sheet, conflicts, differences detected) |
|
|
280
|
+
| `2` | Usage error (missing file, bad argument) |
|
|
281
|
+
|
|
282
|
+
---
|
|
283
|
+
|
|
180
284
|
## Format detection logic
|
|
181
285
|
|
|
182
286
|
The factory uses a three-step detection strategy — no format hints required from the caller:
|
|
@@ -224,6 +328,22 @@ result = ValidationResult()
|
|
|
224
328
|
SampleSheetValidator()._check_index_distances(samples, result, min_distance=4)
|
|
225
329
|
```
|
|
226
330
|
|
|
331
|
+
---
|
|
332
|
+
|
|
333
|
+
## Merger conflict and warning codes
|
|
334
|
+
|
|
335
|
+
| Code | Level | Description |
|
|
336
|
+
|---|---|---|
|
|
337
|
+
| `PARSE_ERROR` | conflict | An input sheet could not be parsed |
|
|
338
|
+
| `INDEX_COLLISION` | conflict | The same index appears in the same lane across two sheets |
|
|
339
|
+
| `READ_LENGTH_CONFLICT` | conflict | Sheets specify different read lengths or cycle counts |
|
|
340
|
+
| `MERGE_VALIDATION_ERROR` | conflict | Post-merge validation of the combined sheet failed |
|
|
341
|
+
| `MIXED_FORMAT` | warning | Input sheets are a mix of V1 and V2 formats |
|
|
342
|
+
| `INDEX_DISTANCE_TOO_LOW` | warning | Cross-sheet index pair has Hamming distance below threshold |
|
|
343
|
+
| `ADAPTER_CONFLICT` | warning | Adapter sequences differ between sheets (primary sheet adapters are used) |
|
|
344
|
+
| `INCOMPLETE_SAMPLE_RECORD` | warning | A sample row is missing `Sample_ID` or index and was skipped |
|
|
345
|
+
|
|
346
|
+
|
|
227
347
|
---
|
|
228
348
|
|
|
229
349
|
## Diff
|
|
@@ -361,12 +481,36 @@ sheet.get_read_structure() # → ReadStructure dataclass
|
|
|
361
481
|
|
|
362
482
|
---
|
|
363
483
|
|
|
484
|
+
---
|
|
485
|
+
|
|
486
|
+
### `SampleSheetMerger`
|
|
487
|
+
|
|
488
|
+
| Method / attribute | Returns | Description |
|
|
489
|
+
|---|---|---|
|
|
490
|
+
| `SampleSheetMerger(target_version=)` | — | Instantiate; default target is `SampleSheetVersion.V2` |
|
|
491
|
+
| `add(path)` | `self` | Register an input sheet path (fluent) |
|
|
492
|
+
| `merge(output_path, *, validate=True, abort_on_conflicts=True)` | `MergeResult` | Run the merge and write output |
|
|
493
|
+
|
|
494
|
+
### `MergeResult`
|
|
495
|
+
|
|
496
|
+
| Attribute / method | Type | Description |
|
|
497
|
+
|---|---|---|
|
|
498
|
+
| `has_conflicts` | `bool` | `True` if any conflict was recorded |
|
|
499
|
+
| `sample_count` | `int` | Number of samples in the merged output |
|
|
500
|
+
| `output_path` | `Path \| None` | Path written; `None` if write was aborted |
|
|
501
|
+
| `source_versions` | `dict[str, str]` | Per-input-file detected format version |
|
|
502
|
+
| `conflicts` | `list[MergeConflict]` | Structured conflict records |
|
|
503
|
+
| `warnings` | `list[MergeConflict]` | Structured warning records |
|
|
504
|
+
| `summary()` | `str` | Human-readable one-line summary |
|
|
505
|
+
|
|
506
|
+
---
|
|
507
|
+
|
|
364
508
|
## Contributing
|
|
365
509
|
|
|
366
510
|
```bash
|
|
367
511
|
git clone https://github.com/chaitanyakasaraneni/samplesheet-parser
|
|
368
512
|
cd samplesheet-parser
|
|
369
|
-
pip install -e ".[dev]"
|
|
513
|
+
pip install -e ".[dev,cli]"
|
|
370
514
|
|
|
371
515
|
# Run tests
|
|
372
516
|
pytest tests/ -v
|
|
@@ -389,7 +533,7 @@ See [CONTRIBUTING.md](CONTRIBUTING.md) for the full local testing guide and PR c
|
|
|
389
533
|
title = {samplesheet-parser: Format-agnostic parser for Illumina SampleSheet.csv},
|
|
390
534
|
year = {2026},
|
|
391
535
|
url = {https://github.com/chaitanyakasaraneni/samplesheet-parser},
|
|
392
|
-
version = {0.
|
|
536
|
+
version = {0.3.0}
|
|
393
537
|
}
|
|
394
538
|
```
|
|
395
539
|
|
|
@@ -6,7 +6,8 @@ Run from the repo root:
|
|
|
6
6
|
python examples/parse_examples.py
|
|
7
7
|
|
|
8
8
|
Demonstrates auto-detection, samples(), index_type(), UMI extraction,
|
|
9
|
-
and
|
|
9
|
+
validation, and custom section parsing for every example sheet in
|
|
10
|
+
examples/sample_sheets/.
|
|
10
11
|
"""
|
|
11
12
|
|
|
12
13
|
from __future__ import annotations
|
|
@@ -22,18 +23,23 @@ from samplesheet_parser import SampleSheetFactory, SampleSheetValidator
|
|
|
22
23
|
SHEETS_DIR = Path(__file__).parent / "sample_sheets"
|
|
23
24
|
|
|
24
25
|
# Ordered for readability: V1 first, then V2
|
|
25
|
-
|
|
26
|
-
|
|
27
|
-
"
|
|
28
|
-
"
|
|
29
|
-
"
|
|
30
|
-
"
|
|
31
|
-
"
|
|
32
|
-
"
|
|
26
|
+
# Each entry is (filename, list of custom section names to demo, or [])
|
|
27
|
+
EXAMPLE_FILES: list[tuple[str, list[str]]] = [
|
|
28
|
+
("v1_dual_index.csv", []),
|
|
29
|
+
("v1_single_index.csv", []),
|
|
30
|
+
("v1_multi_lane.csv", []),
|
|
31
|
+
("v1_with_manifests.csv", ["Manifests"]),
|
|
32
|
+
("v1_with_lab_qc_settings.csv", ["Lab_QC_Settings"]),
|
|
33
|
+
("v2_novaseq_x_dual_index.csv", []),
|
|
34
|
+
("v2_with_index_umi.csv", []),
|
|
35
|
+
("v2_with_read_umi.csv", []),
|
|
36
|
+
("v2_nextseq_single_index.csv", []),
|
|
37
|
+
("v2_with_cloud_settings.csv", ["Cloud_Settings"]),
|
|
38
|
+
("v2_with_pipeline_settings.csv", ["Pipeline_Settings"]),
|
|
33
39
|
]
|
|
34
40
|
|
|
35
41
|
|
|
36
|
-
def parse_sheet(path: Path) -> None:
|
|
42
|
+
def parse_sheet(path: Path, custom_sections: list[str]) -> None:
|
|
37
43
|
print(f"\n{'='*60}")
|
|
38
44
|
print(f" {path.name}")
|
|
39
45
|
print(f"{'='*60}")
|
|
@@ -70,6 +76,18 @@ def parse_sheet(path: Path) -> None:
|
|
|
70
76
|
print(f" UMI location : {rs.umi_location}")
|
|
71
77
|
print(f" Read structure : {rs.read_structure}")
|
|
72
78
|
|
|
79
|
+
# Custom sections
|
|
80
|
+
if custom_sections:
|
|
81
|
+
print("\n Custom sections:")
|
|
82
|
+
for section_name in custom_sections:
|
|
83
|
+
data = sheet.parse_custom_section(section_name)
|
|
84
|
+
if data:
|
|
85
|
+
print(f" [{section_name}]")
|
|
86
|
+
for key, value in data.items():
|
|
87
|
+
print(f" {key:<28} {value}")
|
|
88
|
+
else:
|
|
89
|
+
print(f" [{section_name}] — (empty or not present)")
|
|
90
|
+
|
|
73
91
|
# Samples table
|
|
74
92
|
samples = sheet.samples()
|
|
75
93
|
print(f"\n Samples ({len(samples)} total):")
|
|
@@ -97,14 +115,14 @@ def main() -> None:
|
|
|
97
115
|
print("samplesheet-parser — Example Sheet Demo")
|
|
98
116
|
print(f"Parsing {len(EXAMPLE_FILES)} example sheets from {SHEETS_DIR}\n")
|
|
99
117
|
|
|
100
|
-
missing = [f for f in EXAMPLE_FILES if not (SHEETS_DIR / f).exists()]
|
|
118
|
+
missing = [f for f, _ in EXAMPLE_FILES if not (SHEETS_DIR / f).exists()]
|
|
101
119
|
if missing:
|
|
102
120
|
print(f"Warning: missing files: {missing}")
|
|
103
121
|
|
|
104
|
-
for filename in EXAMPLE_FILES:
|
|
122
|
+
for filename, custom_sections in EXAMPLE_FILES:
|
|
105
123
|
path = SHEETS_DIR / filename
|
|
106
124
|
if path.exists():
|
|
107
|
-
parse_sheet(path)
|
|
125
|
+
parse_sheet(path, custom_sections)
|
|
108
126
|
|
|
109
127
|
print(f"\n{'='*60}")
|
|
110
128
|
print("Done.")
|