ragnav 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- ragnav-0.1.0/LICENSE +21 -0
- ragnav-0.1.0/PKG-INFO +365 -0
- ragnav-0.1.0/README.md +325 -0
- ragnav-0.1.0/pyproject.toml +72 -0
- ragnav-0.1.0/ragnav/__init__.py +23 -0
- ragnav-0.1.0/ragnav/__main__.py +4 -0
- ragnav-0.1.0/ragnav/answering/__init__.py +14 -0
- ragnav-0.1.0/ragnav/answering/inline_citations.py +126 -0
- ragnav-0.1.0/ragnav/cache/__init__.py +4 -0
- ragnav-0.1.0/ragnav/cache/sqlite_cache.py +110 -0
- ragnav-0.1.0/ragnav/cli.py +242 -0
- ragnav-0.1.0/ragnav/env.py +16 -0
- ragnav-0.1.0/ragnav/eval/__init__.py +10 -0
- ragnav-0.1.0/ragnav/eval/cases.py +31 -0
- ragnav-0.1.0/ragnav/eval/metrics.py +78 -0
- ragnav-0.1.0/ragnav/graph.py +97 -0
- ragnav-0.1.0/ragnav/graphrag/__init__.py +16 -0
- ragnav-0.1.0/ragnav/graphrag/entities.py +43 -0
- ragnav-0.1.0/ragnav/graphrag/extract.py +235 -0
- ragnav-0.1.0/ragnav/graphrag/graph.py +45 -0
- ragnav-0.1.0/ragnav/graphrag/lexicon.py +85 -0
- ragnav-0.1.0/ragnav/graphrag/retriever.py +101 -0
- ragnav-0.1.0/ragnav/index/__init__.py +5 -0
- ragnav-0.1.0/ragnav/index/bm25.py +47 -0
- ragnav-0.1.0/ragnav/index/vectors.py +51 -0
- ragnav-0.1.0/ragnav/ingest/__init__.py +33 -0
- ragnav-0.1.0/ragnav/ingest/chat.py +97 -0
- ragnav-0.1.0/ragnav/ingest/email.py +111 -0
- ragnav-0.1.0/ragnav/ingest/html.py +94 -0
- ragnav-0.1.0/ragnav/ingest/markdown.py +123 -0
- ragnav-0.1.0/ragnav/ingest/pdf.py +374 -0
- ragnav-0.1.0/ragnav/json_utils.py +51 -0
- ragnav-0.1.0/ragnav/llm/__init__.py +5 -0
- ragnav-0.1.0/ragnav/llm/base.py +25 -0
- ragnav-0.1.0/ragnav/llm/fake.py +44 -0
- ragnav-0.1.0/ragnav/llm/instrumented.py +43 -0
- ragnav-0.1.0/ragnav/llm/mistral.py +68 -0
- ragnav-0.1.0/ragnav/models.py +44 -0
- ragnav-0.1.0/ragnav/net.py +36 -0
- ragnav-0.1.0/ragnav/observability.py +43 -0
- ragnav-0.1.0/ragnav/papers/__init__.py +7 -0
- ragnav-0.1.0/ragnav/papers/pdf_heuristics.py +86 -0
- ragnav-0.1.0/ragnav/papers/rag.py +165 -0
- ragnav-0.1.0/ragnav/pipelines/__init__.py +19 -0
- ragnav-0.1.0/ragnav/pipelines/agentic.py +87 -0
- ragnav-0.1.0/ragnav/pipelines/agentic_pdf.py +54 -0
- ragnav-0.1.0/ragnav/pipelines/hybrid.py +92 -0
- ragnav-0.1.0/ragnav/pipelines/vectorless.py +88 -0
- ragnav-0.1.0/ragnav/retrieval.py +1030 -0
- ragnav-0.1.0/ragnav/security/__init__.py +8 -0
- ragnav-0.1.0/ragnav/security/policy.py +98 -0
- ragnav-0.1.0/ragnav/utils.py +52 -0
- ragnav-0.1.0/ragnav.egg-info/PKG-INFO +365 -0
- ragnav-0.1.0/ragnav.egg-info/SOURCES.txt +57 -0
- ragnav-0.1.0/ragnav.egg-info/dependency_links.txt +1 -0
- ragnav-0.1.0/ragnav.egg-info/entry_points.txt +2 -0
- ragnav-0.1.0/ragnav.egg-info/requires.txt +19 -0
- ragnav-0.1.0/ragnav.egg-info/top_level.txt +1 -0
- ragnav-0.1.0/setup.cfg +4 -0
ragnav-0.1.0/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026 Irfan Ali
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
ragnav-0.1.0/PKG-INFO
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: ragnav
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: Hybrid structure-aware retrieval (BM25 + embeddings + structure graph expansion), Mistral-first.
|
|
5
|
+
Author: RAGNav Contributors
|
|
6
|
+
License-Expression: MIT
|
|
7
|
+
Project-URL: Homepage, https://github.com/irfanalidv/RAGNav
|
|
8
|
+
Project-URL: Repository, https://github.com/irfanalidv/RAGNav
|
|
9
|
+
Keywords: rag,retrieval,pdf,papers,graphrag,bm25
|
|
10
|
+
Classifier: Development Status :: 3 - Alpha
|
|
11
|
+
Classifier: Intended Audience :: Developers
|
|
12
|
+
Classifier: Intended Audience :: Science/Research
|
|
13
|
+
Classifier: Programming Language :: Python :: 3
|
|
14
|
+
Classifier: Programming Language :: Python :: 3 :: Only
|
|
15
|
+
Classifier: Programming Language :: Python :: 3.9
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.10
|
|
17
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
18
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
19
|
+
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
|
|
20
|
+
Classifier: Topic :: Text Processing :: Indexing
|
|
21
|
+
Requires-Python: >=3.9
|
|
22
|
+
Description-Content-Type: text/markdown
|
|
23
|
+
License-File: LICENSE
|
|
24
|
+
Requires-Dist: numpy>=1.26.0
|
|
25
|
+
Requires-Dist: rank-bm25>=0.2.2
|
|
26
|
+
Provides-Extra: mistral
|
|
27
|
+
Requires-Dist: mistralai>=1.9.0; extra == "mistral"
|
|
28
|
+
Requires-Dist: python-dotenv>=1.0.1; extra == "mistral"
|
|
29
|
+
Provides-Extra: pdf
|
|
30
|
+
Requires-Dist: pymupdf>=1.26.0; extra == "pdf"
|
|
31
|
+
Requires-Dist: requests>=2.31.0; extra == "pdf"
|
|
32
|
+
Provides-Extra: messy
|
|
33
|
+
Requires-Dist: beautifulsoup4>=4.12.0; extra == "messy"
|
|
34
|
+
Provides-Extra: dev
|
|
35
|
+
Requires-Dist: black>=24.0.0; extra == "dev"
|
|
36
|
+
Requires-Dist: ruff>=0.6.0; extra == "dev"
|
|
37
|
+
Requires-Dist: build>=1.2.0; extra == "dev"
|
|
38
|
+
Requires-Dist: twine>=5.0.0; extra == "dev"
|
|
39
|
+
Dynamic: license-file
|
|
40
|
+
|
|
41
|
+
# RAGNav
|
|
42
|
+
|
|
43
|
+
[](https://pypi.org/project/ragnav/)
|
|
44
|
+
[](https://pypi.org/project/ragnav/)
|
|
45
|
+
[](https://pypi.org/project/ragnav/)
|
|
46
|
+
[](https://github.com/psf/black)
|
|
47
|
+
[](https://pypi.org/project/ragnav/)
|
|
48
|
+
|
|
49
|
+
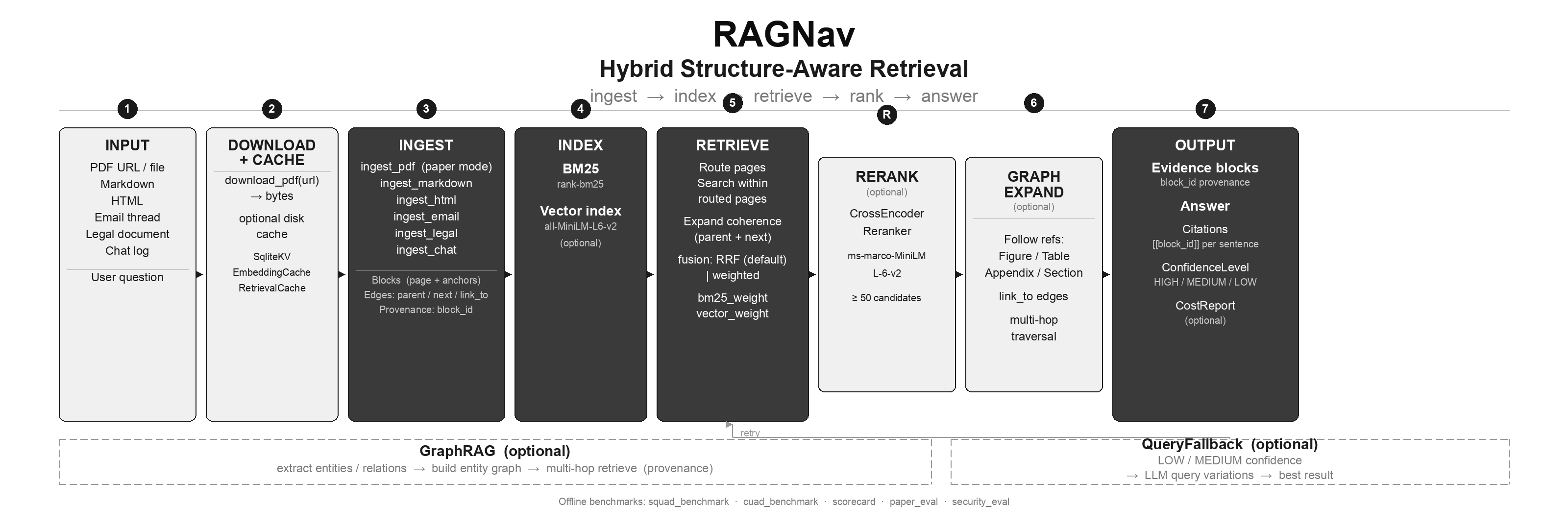
|
|
50
|
+
|
|
51
|
+
**RAGNav** is **paper-native, navigation-first RAG** for long documents (especially **PDF research papers**).
|
|
52
|
+
|
|
53
|
+
Instead of “embed query → retrieve chunks”, it answers:
|
|
54
|
+
**Where in this document should we look first?** (pages/sections/refs), then retrieves evidence.
|
|
55
|
+
|
|
56
|
+
## The problem (why long-document QA fails)
|
|
57
|
+
|
|
58
|
+
LLMs have finite context windows and degrade on long inputs (“lost in the middle” effects). In long PDFs (papers, reports, manuals), naive retrieval often returns *plausible* text but misses the *right* place.
|
|
59
|
+
|
|
60
|
+
## Why classic vector + chunk RAG fails (in PDFs)
|
|
61
|
+
|
|
62
|
+
1. **Intent mismatch**: the query expresses intent; the most similar text isn’t always the most relevant.
|
|
63
|
+
2. **Hard chunking breaks meaning**: chunks cut across sections/tables/captions, losing provenance and coherence.
|
|
64
|
+
3. **Similarity ≠ relevance**: many sections look semantically similar (especially in technical documents).
|
|
65
|
+
4. **Cross-references**: “see Figure 3 / Table 2 / Appendix A / Section 4.1” rarely matches the referenced content.
|
|
66
|
+
5. **No navigation**: users don’t want “top-k chunks”; they want *where the answer lives* + traceable evidence.
|
|
67
|
+
|
|
68
|
+
## RAGNav’s approach (navigation-first retrieval loop)
|
|
69
|
+
|
|
70
|
+
RAGNav is built around a simple loop:
|
|
71
|
+
|
|
72
|
+
1. **Ingest (paper mode)**: PDF → blocks with `anchors={"page": N}` + edges (`parent`, `next`, `link_to`).
|
|
73
|
+
2. **Route**: query → rank likely **pages**.
|
|
74
|
+
3. **Retrieve**: search **within routed pages** (hybrid BM25 + embeddings).
|
|
75
|
+
4. **Expand**: add coherence (section headers + adjacent “next” blocks).
|
|
76
|
+
5. **Follow refs** (optional): traverse `link_to` edges (Figure/Table/Appendix/Section).
|
|
77
|
+
6. **Answer**: generate from retrieved evidence (optionally with inline citations).
|
|
78
|
+
|
|
79
|
+
## The “index” (what the model navigates)
|
|
80
|
+
|
|
81
|
+
RAGNav normalizes everything into a small graph:
|
|
82
|
+
|
|
83
|
+
```text
|
|
84
|
+
Block {
|
|
85
|
+
block_id: "pdf:paper.pdf#b19"
|
|
86
|
+
doc_id: "pdf:paper.pdf"
|
|
87
|
+
text: "..."
|
|
88
|
+
anchors: { page: 5, line_start: 12, line_end: 20 }
|
|
89
|
+
}
|
|
90
|
+
|
|
91
|
+
Edge {
|
|
92
|
+
type: "parent" | "next" | "link_to" | ...
|
|
93
|
+
src: block_id
|
|
94
|
+
dst: block_id
|
|
95
|
+
}
|
|
96
|
+
```
|
|
97
|
+
|
|
98
|
+
This is the practical equivalent of PageIndex’s “in-context index”, but optimized for **papers**:
|
|
99
|
+
pages + headings + cross-references + provenance.
|
|
100
|
+
|
|
101
|
+
## Vector RAG vs RAGNav (paper-mode)
|
|
102
|
+
|
|
103
|
+
| Problem | Vector + chunks | RAGNav (navigation-first) |
|
|
104
|
+
| --- | --- | --- |
|
|
105
|
+
| Find “where” in a paper | Not explicit | Routes pages + sections |
|
|
106
|
+
| Cross-references (“see Appendix”) | Usually missed | Follows `link_to` edges |
|
|
107
|
+
| Provenance | Weak (chunk ids) | Page + block ids + anchors |
|
|
108
|
+
| Coherence | Fragmented | Deterministic expansion (`parent`/`next`) |
|
|
109
|
+
| Evaluation | Ad-hoc | Built-in offline suites + scorecard |
|
|
110
|
+
|
|
111
|
+
## Use cases
|
|
112
|
+
|
|
113
|
+
- **Research papers (PDF)**: page routing + cross-ref following.
|
|
114
|
+
- **Reports / manuals / specs**: structure-aware retrieval (coherent evidence, not fragments).
|
|
115
|
+
- **Grounded answers**: inline citations `[[block_id]]` per sentence (optional).
|
|
116
|
+
- **Security baseline**: drop prompt-injection blocks and redact obvious secrets (optional).
|
|
117
|
+
- **GraphRAG**: entity graph + multi-hop traversal with provenance (optional).
|
|
118
|
+
|
|
119
|
+
## Acknowledgements & prior art
|
|
120
|
+
|
|
121
|
+
RAGNav is an independent project, but it stands on strong prior work:
|
|
122
|
+
|
|
123
|
+
- **PageIndex**: RAGNav builds on the core insight popularized by **PageIndex** — *document structure is a first-class retrieval signal* ([repo](https://github.com/VectifyAI/PageIndex), [article](https://pageindex.ai/blog/pageindex-intro)).
|
|
124
|
+
- **PyMuPDF**: PDF text extraction is powered by `pymupdf` (optional dependency).
|
|
125
|
+
- **BM25 / classic IR**: Lexical retrieval uses BM25-style scoring (a long-established baseline).
|
|
126
|
+
- **Mistral**: The reference LLM/embedding client targets Mistral (optional dependency).
|
|
127
|
+
|
|
128
|
+
RAGNav is **not affiliated with** these projects/organizations. If you notice missing or incorrect attribution, please open an issue.
|
|
129
|
+
|
|
130
|
+
---
|
|
131
|
+
|
|
132
|
+
## Install
|
|
133
|
+
|
|
134
|
+
Create a virtualenv, then install RAGNav:
|
|
135
|
+
|
|
136
|
+
```bash
|
|
137
|
+
pip install -e .
|
|
138
|
+
```
|
|
139
|
+
|
|
140
|
+
To enable **PDF ingestion**:
|
|
141
|
+
|
|
142
|
+
```bash
|
|
143
|
+
pip install -e ".[pdf]"
|
|
144
|
+
```
|
|
145
|
+
|
|
146
|
+
To enable **Mistral-backed** chat + embeddings:
|
|
147
|
+
|
|
148
|
+
```bash
|
|
149
|
+
pip install -e ".[mistral]"
|
|
150
|
+
```
|
|
151
|
+
|
|
152
|
+
## Setup (Mistral)
|
|
153
|
+
|
|
154
|
+
Do **not** hardcode or commit keys. Use env vars:
|
|
155
|
+
|
|
156
|
+
```bash
|
|
157
|
+
export MISTRAL_API_KEY="your_key_here"
|
|
158
|
+
```
|
|
159
|
+
|
|
160
|
+
---
|
|
161
|
+
|
|
162
|
+
## Quickstart (CLI): run on an arXiv PDF URL
|
|
163
|
+
|
|
164
|
+
Install:
|
|
165
|
+
|
|
166
|
+
```bash
|
|
167
|
+
pip install -e ".[mistral,pdf]"
|
|
168
|
+
export MISTRAL_API_KEY="..."
|
|
169
|
+
```
|
|
170
|
+
|
|
171
|
+
Run (recommended: paper-mode navigation):
|
|
172
|
+
|
|
173
|
+
```bash
|
|
174
|
+
ragnav paper-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
175
|
+
```
|
|
176
|
+
|
|
177
|
+
### Jupyter notebook quickstart
|
|
178
|
+
|
|
179
|
+
Open:
|
|
180
|
+
- `cookbook/ragnav_paper_quickstart.ipynb`
|
|
181
|
+
|
|
182
|
+
Other modes (optional):
|
|
183
|
+
|
|
184
|
+
- Hybrid (BM25 + embeddings, generic PDF blocks):
|
|
185
|
+
|
|
186
|
+
```bash
|
|
187
|
+
ragnav hybrid-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
188
|
+
```
|
|
189
|
+
|
|
190
|
+
- Vectorless (BM25-only, generic PDF blocks):
|
|
191
|
+
|
|
192
|
+
```bash
|
|
193
|
+
ragnav vectorless-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
194
|
+
```
|
|
195
|
+
|
|
196
|
+
- Agentic retrieval loop:
|
|
197
|
+
|
|
198
|
+
```bash
|
|
199
|
+
ragnav agentic-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "Summarize the paper's main contribution."
|
|
200
|
+
```
|
|
201
|
+
|
|
202
|
+
### Real example output (paper-mode navigation)
|
|
203
|
+
|
|
204
|
+
This repo includes a paper-mode demo that downloads an arXiv PDF and runs **page routing + retrieval**:
|
|
205
|
+
|
|
206
|
+
```bash
|
|
207
|
+
python3 examples/papers/ragnav_paper_rag_pdf.py \
|
|
208
|
+
--pdf-url "https://arxiv.org/pdf/2507.13334.pdf" \
|
|
209
|
+
--pdf-name "2507.13334.pdf" \
|
|
210
|
+
--max-pages 25
|
|
211
|
+
```
|
|
212
|
+
|
|
213
|
+
Output (real, trimmed):
|
|
214
|
+
|
|
215
|
+
```text
|
|
216
|
+
## Routed pages
|
|
217
|
+
- doc_id=pdf:2507.13334.pdf page=4 score=0.5423 N=3
|
|
218
|
+
- doc_id=pdf:2507.13334.pdf page=14 score=0.5298 N=7
|
|
219
|
+
- doc_id=pdf:2507.13334.pdf page=9 score=0.4662 N=4
|
|
220
|
+
- doc_id=pdf:2507.13334.pdf page=5 score=0.4597 N=3
|
|
221
|
+
|
|
222
|
+
## Retrieved evidence blocks (first 10)
|
|
223
|
+
- page=14 title=Sr-Nle [1130] id=pdf:2507.13334.pdf#b106
|
|
224
|
+
- page=2 title=Related Work id=pdf:2507.13334.pdf#b11
|
|
225
|
+
...
|
|
226
|
+
```
|
|
227
|
+
|
|
228
|
+
---
|
|
229
|
+
|
|
230
|
+
## Quickstart (Python): papers (recommended)
|
|
231
|
+
|
|
232
|
+
### PaperRAG (page routing + cross-ref following)
|
|
233
|
+
|
|
234
|
+
```python
|
|
235
|
+
from ragnav import PaperRAG, PaperRAGConfig
|
|
236
|
+
from ragnav.llm.mistral import MistralClient
|
|
237
|
+
from ragnav import download_pdf
|
|
238
|
+
|
|
239
|
+
llm = MistralClient()
|
|
240
|
+
cfg = PaperRAGConfig(max_pages=25, top_pages=4, follow_refs=True)
|
|
241
|
+
|
|
242
|
+
pdf_bytes = download_pdf("https://arxiv.org/pdf/2507.13334.pdf")
|
|
243
|
+
paper = PaperRAG.from_pdf_bytes(pdf_bytes, llm=llm, pdf_name="paper.pdf", cfg=cfg)
|
|
244
|
+
print(paper.answer("What experiments were conducted?", cfg=cfg))
|
|
245
|
+
```
|
|
246
|
+
|
|
247
|
+
### Grounded answering (inline citations per sentence)
|
|
248
|
+
|
|
249
|
+
```python
|
|
250
|
+
print(paper.answer_cited("What does Figure 1 show?", cfg=cfg))
|
|
251
|
+
```
|
|
252
|
+
|
|
253
|
+
Output format:
|
|
254
|
+
|
|
255
|
+
```text
|
|
256
|
+
Sentence one [[pdf:paper.pdf#b12]].
|
|
257
|
+
Sentence two [[pdf:paper.pdf#b47]] [[pdf:paper.pdf#b48]].
|
|
258
|
+
```
|
|
259
|
+
|
|
260
|
+
---
|
|
261
|
+
|
|
262
|
+
## Quickstart: GraphRAG (entity multi-hop with provenance)
|
|
263
|
+
|
|
264
|
+
```python
|
|
265
|
+
from ragnav.graphrag import build_entity_graph, EntityGraphRetriever
|
|
266
|
+
|
|
267
|
+
eg = build_entity_graph(blocks) # blocks are RAGNav Block objects
|
|
268
|
+
egr = EntityGraphRetriever(graph=eg, blocks_by_id={b.block_id: b for b in blocks})
|
|
269
|
+
|
|
270
|
+
out = egr.retrieve("Which dataset was BERT evaluated on?")
|
|
271
|
+
for b in out["blocks"][:3]:
|
|
272
|
+
print(b.block_id, b.anchors.get("page"))
|
|
273
|
+
```
|
|
274
|
+
|
|
275
|
+
Networked PDF demo:
|
|
276
|
+
|
|
277
|
+
```bash
|
|
278
|
+
pip install -e ".[mistral,pdf]"
|
|
279
|
+
export MISTRAL_API_KEY="..."
|
|
280
|
+
python3 examples/graphs/ragnav_entity_graphrag_pdf.py
|
|
281
|
+
```
|
|
282
|
+
|
|
283
|
+
---
|
|
284
|
+
|
|
285
|
+
## Benchmarks
|
|
286
|
+
|
|
287
|
+
### One-command scorecard (offline)
|
|
288
|
+
|
|
289
|
+
```bash
|
|
290
|
+
python3 -m benchmarks.scorecard
|
|
291
|
+
```
|
|
292
|
+
|
|
293
|
+
Example output (real):
|
|
294
|
+
|
|
295
|
+
```json
|
|
296
|
+
{
|
|
297
|
+
"ok": true,
|
|
298
|
+
"suites": [
|
|
299
|
+
{ "name": "offline_smoke", "ok": true },
|
|
300
|
+
{ "name": "paper_eval", "ok": true, "json": { "suite": "paper_crossref_v1", "follow_refs_true": { "block_hit_rate": 1.0 } } },
|
|
301
|
+
{ "name": "entity_eval_excerpt", "ok": true, "json": { "suite": "entity_excerpt_v1" } },
|
|
302
|
+
{ "name": "security_eval", "ok": true }
|
|
303
|
+
]
|
|
304
|
+
}
|
|
305
|
+
```
|
|
306
|
+
|
|
307
|
+
---
|
|
308
|
+
|
|
309
|
+
## Local PDFs + golden manifest (optional)
|
|
310
|
+
|
|
311
|
+
If you add local PDFs under `data/papers/`, you can run a suite against **your own papers**:
|
|
312
|
+
|
|
313
|
+
```bash
|
|
314
|
+
mkdir -p data/papers
|
|
315
|
+
# copy some PDFs into data/papers/
|
|
316
|
+
python3 -m benchmarks.paper_pdf_suite
|
|
317
|
+
```
|
|
318
|
+
|
|
319
|
+
Optional: add `data/papers/manifest.json` to define *expected outcomes* per PDF (queries + expected pages/substrings).
|
|
320
|
+
|
|
321
|
+
Example manifest:
|
|
322
|
+
|
|
323
|
+
```json
|
|
324
|
+
{
|
|
325
|
+
"papers": [
|
|
326
|
+
{
|
|
327
|
+
"file": "my_paper.pdf",
|
|
328
|
+
"cases": [
|
|
329
|
+
{
|
|
330
|
+
"case_id": "datasets",
|
|
331
|
+
"query": "Which datasets are mentioned?",
|
|
332
|
+
"expected_pages": [2, 3],
|
|
333
|
+
"expected_text_substrings": ["SQuAD", "GLUE"],
|
|
334
|
+
"tags": ["datasets"]
|
|
335
|
+
}
|
|
336
|
+
]
|
|
337
|
+
}
|
|
338
|
+
]
|
|
339
|
+
}
|
|
340
|
+
```
|
|
341
|
+
|
|
342
|
+
---
|
|
343
|
+
|
|
344
|
+
## Repo layout
|
|
345
|
+
|
|
346
|
+
- `ragnav/`: the Python package (hybrid retrieval engine)
|
|
347
|
+
- `benchmarks/`: accuracy + latency/cost harness (PageIndex-style baseline + RAGNav hybrid)
|
|
348
|
+
- `examples/`: runnable end-to-end demos
|
|
349
|
+
|
|
350
|
+
---
|
|
351
|
+
|
|
352
|
+
## More examples
|
|
353
|
+
|
|
354
|
+
```bash
|
|
355
|
+
export MISTRAL_API_KEY="..."
|
|
356
|
+
python3 examples/multidoc/ragnav_doc_search_semantics.py
|
|
357
|
+
```
|
|
358
|
+
|
|
359
|
+
Other entrypoints:
|
|
360
|
+
- `examples/multidoc/ragnav_doc_search_description.py`
|
|
361
|
+
- `examples/multidoc/ragnav_doc_search_metadata.py`
|
|
362
|
+
- `examples/agentic/ragnav_agentic_retrieval.py`
|
|
363
|
+
- `examples/agentic/ragnav_agentic_retrieval_pdf.py`
|
|
364
|
+
- `examples/papers/ragnav_vectorless_rag_pdf.py`
|
|
365
|
+
- `examples/graphs/ragnav_chat_graph_retrieval.py`
|
ragnav-0.1.0/README.md
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
1
|
+
# RAGNav
|
|
2
|
+
|
|
3
|
+
[](https://pypi.org/project/ragnav/)
|
|
4
|
+
[](https://pypi.org/project/ragnav/)
|
|
5
|
+
[](https://pypi.org/project/ragnav/)
|
|
6
|
+
[](https://github.com/psf/black)
|
|
7
|
+
[](https://pypi.org/project/ragnav/)
|
|
8
|
+
|
|
9
|
+

|
|
10
|
+
|
|
11
|
+
**RAGNav** is **paper-native, navigation-first RAG** for long documents (especially **PDF research papers**).
|
|
12
|
+
|
|
13
|
+
Instead of “embed query → retrieve chunks”, it answers:
|
|
14
|
+
**Where in this document should we look first?** (pages/sections/refs), then retrieves evidence.
|
|
15
|
+
|
|
16
|
+
## The problem (why long-document QA fails)
|
|
17
|
+
|
|
18
|
+
LLMs have finite context windows and degrade on long inputs (“lost in the middle” effects). In long PDFs (papers, reports, manuals), naive retrieval often returns *plausible* text but misses the *right* place.
|
|
19
|
+
|
|
20
|
+
## Why classic vector + chunk RAG fails (in PDFs)
|
|
21
|
+
|
|
22
|
+
1. **Intent mismatch**: the query expresses intent; the most similar text isn’t always the most relevant.
|
|
23
|
+
2. **Hard chunking breaks meaning**: chunks cut across sections/tables/captions, losing provenance and coherence.
|
|
24
|
+
3. **Similarity ≠ relevance**: many sections look semantically similar (especially in technical documents).
|
|
25
|
+
4. **Cross-references**: “see Figure 3 / Table 2 / Appendix A / Section 4.1” rarely matches the referenced content.
|
|
26
|
+
5. **No navigation**: users don’t want “top-k chunks”; they want *where the answer lives* + traceable evidence.
|
|
27
|
+
|
|
28
|
+
## RAGNav’s approach (navigation-first retrieval loop)
|
|
29
|
+
|
|
30
|
+
RAGNav is built around a simple loop:
|
|
31
|
+
|
|
32
|
+
1. **Ingest (paper mode)**: PDF → blocks with `anchors={"page": N}` + edges (`parent`, `next`, `link_to`).
|
|
33
|
+
2. **Route**: query → rank likely **pages**.
|
|
34
|
+
3. **Retrieve**: search **within routed pages** (hybrid BM25 + embeddings).
|
|
35
|
+
4. **Expand**: add coherence (section headers + adjacent “next” blocks).
|
|
36
|
+
5. **Follow refs** (optional): traverse `link_to` edges (Figure/Table/Appendix/Section).
|
|
37
|
+
6. **Answer**: generate from retrieved evidence (optionally with inline citations).
|
|
38
|
+
|
|
39
|
+
## The “index” (what the model navigates)
|
|
40
|
+
|
|
41
|
+
RAGNav normalizes everything into a small graph:
|
|
42
|
+
|
|
43
|
+
```text
|
|
44
|
+
Block {
|
|
45
|
+
block_id: "pdf:paper.pdf#b19"
|
|
46
|
+
doc_id: "pdf:paper.pdf"
|
|
47
|
+
text: "..."
|
|
48
|
+
anchors: { page: 5, line_start: 12, line_end: 20 }
|
|
49
|
+
}
|
|
50
|
+
|
|
51
|
+
Edge {
|
|
52
|
+
type: "parent" | "next" | "link_to" | ...
|
|
53
|
+
src: block_id
|
|
54
|
+
dst: block_id
|
|
55
|
+
}
|
|
56
|
+
```
|
|
57
|
+
|
|
58
|
+
This is the practical equivalent of PageIndex’s “in-context index”, but optimized for **papers**:
|
|
59
|
+
pages + headings + cross-references + provenance.
|
|
60
|
+
|
|
61
|
+
## Vector RAG vs RAGNav (paper-mode)
|
|
62
|
+
|
|
63
|
+
| Problem | Vector + chunks | RAGNav (navigation-first) |
|
|
64
|
+
| --- | --- | --- |
|
|
65
|
+
| Find “where” in a paper | Not explicit | Routes pages + sections |
|
|
66
|
+
| Cross-references (“see Appendix”) | Usually missed | Follows `link_to` edges |
|
|
67
|
+
| Provenance | Weak (chunk ids) | Page + block ids + anchors |
|
|
68
|
+
| Coherence | Fragmented | Deterministic expansion (`parent`/`next`) |
|
|
69
|
+
| Evaluation | Ad-hoc | Built-in offline suites + scorecard |
|
|
70
|
+
|
|
71
|
+
## Use cases
|
|
72
|
+
|
|
73
|
+
- **Research papers (PDF)**: page routing + cross-ref following.
|
|
74
|
+
- **Reports / manuals / specs**: structure-aware retrieval (coherent evidence, not fragments).
|
|
75
|
+
- **Grounded answers**: inline citations `[[block_id]]` per sentence (optional).
|
|
76
|
+
- **Security baseline**: drop prompt-injection blocks and redact obvious secrets (optional).
|
|
77
|
+
- **GraphRAG**: entity graph + multi-hop traversal with provenance (optional).
|
|
78
|
+
|
|
79
|
+
## Acknowledgements & prior art
|
|
80
|
+
|
|
81
|
+
RAGNav is an independent project, but it stands on strong prior work:
|
|
82
|
+
|
|
83
|
+
- **PageIndex**: RAGNav builds on the core insight popularized by **PageIndex** — *document structure is a first-class retrieval signal* ([repo](https://github.com/VectifyAI/PageIndex), [article](https://pageindex.ai/blog/pageindex-intro)).
|
|
84
|
+
- **PyMuPDF**: PDF text extraction is powered by `pymupdf` (optional dependency).
|
|
85
|
+
- **BM25 / classic IR**: Lexical retrieval uses BM25-style scoring (a long-established baseline).
|
|
86
|
+
- **Mistral**: The reference LLM/embedding client targets Mistral (optional dependency).
|
|
87
|
+
|
|
88
|
+
RAGNav is **not affiliated with** these projects/organizations. If you notice missing or incorrect attribution, please open an issue.
|
|
89
|
+
|
|
90
|
+
---
|
|
91
|
+
|
|
92
|
+
## Install
|
|
93
|
+
|
|
94
|
+
Create a virtualenv, then install RAGNav:
|
|
95
|
+
|
|
96
|
+
```bash
|
|
97
|
+
pip install -e .
|
|
98
|
+
```
|
|
99
|
+
|
|
100
|
+
To enable **PDF ingestion**:
|
|
101
|
+
|
|
102
|
+
```bash
|
|
103
|
+
pip install -e ".[pdf]"
|
|
104
|
+
```
|
|
105
|
+
|
|
106
|
+
To enable **Mistral-backed** chat + embeddings:
|
|
107
|
+
|
|
108
|
+
```bash
|
|
109
|
+
pip install -e ".[mistral]"
|
|
110
|
+
```
|
|
111
|
+
|
|
112
|
+
## Setup (Mistral)
|
|
113
|
+
|
|
114
|
+
Do **not** hardcode or commit keys. Use env vars:
|
|
115
|
+
|
|
116
|
+
```bash
|
|
117
|
+
export MISTRAL_API_KEY="your_key_here"
|
|
118
|
+
```
|
|
119
|
+
|
|
120
|
+
---
|
|
121
|
+
|
|
122
|
+
## Quickstart (CLI): run on an arXiv PDF URL
|
|
123
|
+
|
|
124
|
+
Install:
|
|
125
|
+
|
|
126
|
+
```bash
|
|
127
|
+
pip install -e ".[mistral,pdf]"
|
|
128
|
+
export MISTRAL_API_KEY="..."
|
|
129
|
+
```
|
|
130
|
+
|
|
131
|
+
Run (recommended: paper-mode navigation):
|
|
132
|
+
|
|
133
|
+
```bash
|
|
134
|
+
ragnav paper-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
135
|
+
```
|
|
136
|
+
|
|
137
|
+
### Jupyter notebook quickstart
|
|
138
|
+
|
|
139
|
+
Open:
|
|
140
|
+
- `cookbook/ragnav_paper_quickstart.ipynb`
|
|
141
|
+
|
|
142
|
+
Other modes (optional):
|
|
143
|
+
|
|
144
|
+
- Hybrid (BM25 + embeddings, generic PDF blocks):
|
|
145
|
+
|
|
146
|
+
```bash
|
|
147
|
+
ragnav hybrid-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
148
|
+
```
|
|
149
|
+
|
|
150
|
+
- Vectorless (BM25-only, generic PDF blocks):
|
|
151
|
+
|
|
152
|
+
```bash
|
|
153
|
+
ragnav vectorless-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
|
|
154
|
+
```
|
|
155
|
+
|
|
156
|
+
- Agentic retrieval loop:
|
|
157
|
+
|
|
158
|
+
```bash
|
|
159
|
+
ragnav agentic-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "Summarize the paper's main contribution."
|
|
160
|
+
```
|
|
161
|
+
|
|
162
|
+
### Real example output (paper-mode navigation)
|
|
163
|
+
|
|
164
|
+
This repo includes a paper-mode demo that downloads an arXiv PDF and runs **page routing + retrieval**:
|
|
165
|
+
|
|
166
|
+
```bash
|
|
167
|
+
python3 examples/papers/ragnav_paper_rag_pdf.py \
|
|
168
|
+
--pdf-url "https://arxiv.org/pdf/2507.13334.pdf" \
|
|
169
|
+
--pdf-name "2507.13334.pdf" \
|
|
170
|
+
--max-pages 25
|
|
171
|
+
```
|
|
172
|
+
|
|
173
|
+
Output (real, trimmed):
|
|
174
|
+
|
|
175
|
+
```text
|
|
176
|
+
## Routed pages
|
|
177
|
+
- doc_id=pdf:2507.13334.pdf page=4 score=0.5423 N=3
|
|
178
|
+
- doc_id=pdf:2507.13334.pdf page=14 score=0.5298 N=7
|
|
179
|
+
- doc_id=pdf:2507.13334.pdf page=9 score=0.4662 N=4
|
|
180
|
+
- doc_id=pdf:2507.13334.pdf page=5 score=0.4597 N=3
|
|
181
|
+
|
|
182
|
+
## Retrieved evidence blocks (first 10)
|
|
183
|
+
- page=14 title=Sr-Nle [1130] id=pdf:2507.13334.pdf#b106
|
|
184
|
+
- page=2 title=Related Work id=pdf:2507.13334.pdf#b11
|
|
185
|
+
...
|
|
186
|
+
```
|
|
187
|
+
|
|
188
|
+
---
|
|
189
|
+
|
|
190
|
+
## Quickstart (Python): papers (recommended)
|
|
191
|
+
|
|
192
|
+
### PaperRAG (page routing + cross-ref following)
|
|
193
|
+
|
|
194
|
+
```python
|
|
195
|
+
from ragnav import PaperRAG, PaperRAGConfig
|
|
196
|
+
from ragnav.llm.mistral import MistralClient
|
|
197
|
+
from ragnav import download_pdf
|
|
198
|
+
|
|
199
|
+
llm = MistralClient()
|
|
200
|
+
cfg = PaperRAGConfig(max_pages=25, top_pages=4, follow_refs=True)
|
|
201
|
+
|
|
202
|
+
pdf_bytes = download_pdf("https://arxiv.org/pdf/2507.13334.pdf")
|
|
203
|
+
paper = PaperRAG.from_pdf_bytes(pdf_bytes, llm=llm, pdf_name="paper.pdf", cfg=cfg)
|
|
204
|
+
print(paper.answer("What experiments were conducted?", cfg=cfg))
|
|
205
|
+
```
|
|
206
|
+
|
|
207
|
+
### Grounded answering (inline citations per sentence)
|
|
208
|
+
|
|
209
|
+
```python
|
|
210
|
+
print(paper.answer_cited("What does Figure 1 show?", cfg=cfg))
|
|
211
|
+
```
|
|
212
|
+
|
|
213
|
+
Output format:
|
|
214
|
+
|
|
215
|
+
```text
|
|
216
|
+
Sentence one [[pdf:paper.pdf#b12]].
|
|
217
|
+
Sentence two [[pdf:paper.pdf#b47]] [[pdf:paper.pdf#b48]].
|
|
218
|
+
```
|
|
219
|
+
|
|
220
|
+
---
|
|
221
|
+
|
|
222
|
+
## Quickstart: GraphRAG (entity multi-hop with provenance)
|
|
223
|
+
|
|
224
|
+
```python
|
|
225
|
+
from ragnav.graphrag import build_entity_graph, EntityGraphRetriever
|
|
226
|
+
|
|
227
|
+
eg = build_entity_graph(blocks) # blocks are RAGNav Block objects
|
|
228
|
+
egr = EntityGraphRetriever(graph=eg, blocks_by_id={b.block_id: b for b in blocks})
|
|
229
|
+
|
|
230
|
+
out = egr.retrieve("Which dataset was BERT evaluated on?")
|
|
231
|
+
for b in out["blocks"][:3]:
|
|
232
|
+
print(b.block_id, b.anchors.get("page"))
|
|
233
|
+
```
|
|
234
|
+
|
|
235
|
+
Networked PDF demo:
|
|
236
|
+
|
|
237
|
+
```bash
|
|
238
|
+
pip install -e ".[mistral,pdf]"
|
|
239
|
+
export MISTRAL_API_KEY="..."
|
|
240
|
+
python3 examples/graphs/ragnav_entity_graphrag_pdf.py
|
|
241
|
+
```
|
|
242
|
+
|
|
243
|
+
---
|
|
244
|
+
|
|
245
|
+
## Benchmarks
|
|
246
|
+
|
|
247
|
+
### One-command scorecard (offline)
|
|
248
|
+
|
|
249
|
+
```bash
|
|
250
|
+
python3 -m benchmarks.scorecard
|
|
251
|
+
```
|
|
252
|
+
|
|
253
|
+
Example output (real):
|
|
254
|
+
|
|
255
|
+
```json
|
|
256
|
+
{
|
|
257
|
+
"ok": true,
|
|
258
|
+
"suites": [
|
|
259
|
+
{ "name": "offline_smoke", "ok": true },
|
|
260
|
+
{ "name": "paper_eval", "ok": true, "json": { "suite": "paper_crossref_v1", "follow_refs_true": { "block_hit_rate": 1.0 } } },
|
|
261
|
+
{ "name": "entity_eval_excerpt", "ok": true, "json": { "suite": "entity_excerpt_v1" } },
|
|
262
|
+
{ "name": "security_eval", "ok": true }
|
|
263
|
+
]
|
|
264
|
+
}
|
|
265
|
+
```
|
|
266
|
+
|
|
267
|
+
---
|
|
268
|
+
|
|
269
|
+
## Local PDFs + golden manifest (optional)
|
|
270
|
+
|
|
271
|
+
If you add local PDFs under `data/papers/`, you can run a suite against **your own papers**:
|
|
272
|
+
|
|
273
|
+
```bash
|
|
274
|
+
mkdir -p data/papers
|
|
275
|
+
# copy some PDFs into data/papers/
|
|
276
|
+
python3 -m benchmarks.paper_pdf_suite
|
|
277
|
+
```
|
|
278
|
+
|
|
279
|
+
Optional: add `data/papers/manifest.json` to define *expected outcomes* per PDF (queries + expected pages/substrings).
|
|
280
|
+
|
|
281
|
+
Example manifest:
|
|
282
|
+
|
|
283
|
+
```json
|
|
284
|
+
{
|
|
285
|
+
"papers": [
|
|
286
|
+
{
|
|
287
|
+
"file": "my_paper.pdf",
|
|
288
|
+
"cases": [
|
|
289
|
+
{
|
|
290
|
+
"case_id": "datasets",
|
|
291
|
+
"query": "Which datasets are mentioned?",
|
|
292
|
+
"expected_pages": [2, 3],
|
|
293
|
+
"expected_text_substrings": ["SQuAD", "GLUE"],
|
|
294
|
+
"tags": ["datasets"]
|
|
295
|
+
}
|
|
296
|
+
]
|
|
297
|
+
}
|
|
298
|
+
]
|
|
299
|
+
}
|
|
300
|
+
```
|
|
301
|
+
|
|
302
|
+
---
|
|
303
|
+
|
|
304
|
+
## Repo layout
|
|
305
|
+
|
|
306
|
+
- `ragnav/`: the Python package (hybrid retrieval engine)
|
|
307
|
+
- `benchmarks/`: accuracy + latency/cost harness (PageIndex-style baseline + RAGNav hybrid)
|
|
308
|
+
- `examples/`: runnable end-to-end demos
|
|
309
|
+
|
|
310
|
+
---
|
|
311
|
+
|
|
312
|
+
## More examples
|
|
313
|
+
|
|
314
|
+
```bash
|
|
315
|
+
export MISTRAL_API_KEY="..."
|
|
316
|
+
python3 examples/multidoc/ragnav_doc_search_semantics.py
|
|
317
|
+
```
|
|
318
|
+
|
|
319
|
+
Other entrypoints:
|
|
320
|
+
- `examples/multidoc/ragnav_doc_search_description.py`
|
|
321
|
+
- `examples/multidoc/ragnav_doc_search_metadata.py`
|
|
322
|
+
- `examples/agentic/ragnav_agentic_retrieval.py`
|
|
323
|
+
- `examples/agentic/ragnav_agentic_retrieval_pdf.py`
|
|
324
|
+
- `examples/papers/ragnav_vectorless_rag_pdf.py`
|
|
325
|
+
- `examples/graphs/ragnav_chat_graph_retrieval.py`
|