mongol-norm 0.0.1__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- mongol_norm-0.0.1/PKG-INFO +543 -0
- mongol_norm-0.0.1/README.md +527 -0
- mongol_norm-0.0.1/mongol_norm/__init__.py +7 -0
- mongol_norm-0.0.1/mongol_norm/_data.py +59 -0
- mongol_norm-0.0.1/mongol_norm/data/MCH.json +2484 -0
- mongol_norm-0.0.1/mongol_norm/data/MNG.json +2995 -0
- mongol_norm-0.0.1/mongol_norm/data/MNG.normalize.json +883 -0
- mongol_norm-0.0.1/mongol_norm/data/SIB.json +2312 -0
- mongol_norm-0.0.1/mongol_norm/data/TOD.json +2254 -0
- mongol_norm-0.0.1/mongol_norm/rules.py +863 -0
- mongol_norm-0.0.1/mongol_norm/shaper.py +1748 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/PKG-INFO +543 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/SOURCES.txt +23 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/dependency_links.txt +1 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/entry_points.txt +2 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/requires.txt +6 -0
- mongol_norm-0.0.1/mongol_norm.egg-info/top_level.txt +1 -0
- mongol_norm-0.0.1/pyproject.toml +36 -0
- mongol_norm-0.0.1/setup.cfg +4 -0
- mongol_norm-0.0.1/tests/test_core_hud.py +153 -0
- mongol_norm-0.0.1/tests/test_eac_hud.py +217 -0
- mongol_norm-0.0.1/tests/test_joiners.py +88 -0
- mongol_norm-0.0.1/tests/test_normalize_table.py +108 -0
- mongol_norm-0.0.1/tests/test_round_trip.py +750 -0
- mongol_norm-0.0.1/tests/test_shaper.py +1260 -0
|
@@ -0,0 +1,543 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: mongol-norm
|
|
3
|
+
Version: 0.0.1
|
|
4
|
+
Summary: Shape-aware normalizer for Traditional Mongolian script. Implements the UTN #57 v4 shaping pipeline in pure Python.
|
|
5
|
+
License: OFL-1.1
|
|
6
|
+
Project-URL: Homepage, https://github.com/Satsrag/mongol-norm
|
|
7
|
+
Keywords: mongolian,unicode,shaping,normalization,utn57
|
|
8
|
+
Classifier: Programming Language :: Python :: 3
|
|
9
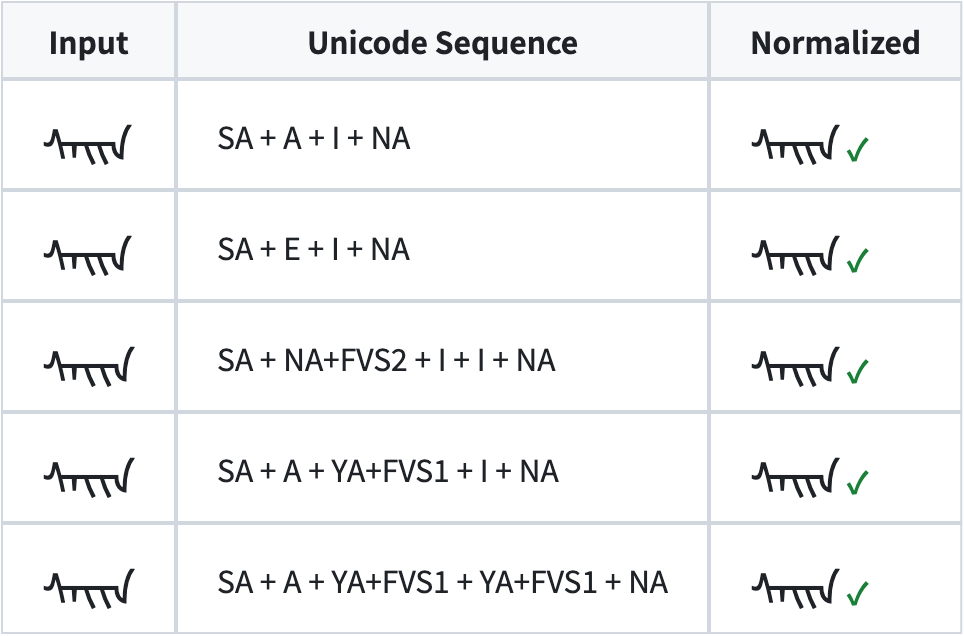
|
+
Classifier: Topic :: Text Processing :: Linguistic
|
|
10
|
+
Requires-Python: >=3.6
|
|
11
|
+
Description-Content-Type: text/markdown
|
|
12
|
+
Provides-Extra: dev
|
|
13
|
+
Requires-Dist: pytest>=7; extra == "dev"
|
|
14
|
+
Provides-Extra: preprocess
|
|
15
|
+
Requires-Dist: mongfontbuilder>=0.10.6; extra == "preprocess"
|
|
16
|
+
|
|
17
|
+
# mongol-norm
|
|
18
|
+
|
|
19
|
+
[](https://github.com/Satsrag/mongol-norm/actions/workflows/test.yml)
|
|
20
|
+
|
|
21
|
+
[English](#english) | [中文](#中文)
|
|
22
|
+
|
|
23
|
+
---
|
|
24
|
+
|
|
25
|
+
<a id="english"></a>
|
|
26
|
+
## English
|
|
27
|
+
|
|
28
|
+
### Status
|
|
29
|
+
|
|
30
|
+
Both halves of the library — shaping and normalization (MNG / Hudum) — are verified against the same upstream corpora. CI runs the full suite on Python 3.9 – 3.13 on every push.
|
|
31
|
+
|
|
32
|
+
#### ✅ Shaping
|
|
33
|
+
|
|
34
|
+
`shape()` and `same_shape()` are cross-validated against two upstream TSV suites:
|
|
35
|
+
|
|
36
|
+
| Suite | Cases | Pass | Notes |
|
|
37
|
+
|---|---|---|---|
|
|
38
|
+
| `mongfontbuilder/core-hud.tsv` | 225 | **100%** | curated regression set |
|
|
39
|
+
| `mongfontbuilder/eac-hud.tsv` (GB/T 25914-2023) | 3513 | **100%** | 5 cases excluded as UTN ↔ EAC xfail, matching mongfontbuilder's own `pytest.mark.xfail` set |
|
|
40
|
+
| Hand-written unit tests | — | **100%** | shape / same_shape / joiner tokens (nirugu, ZWJ) |
|
|
41
|
+
|
|
42
|
+
#### ✅ Normalization — same guarantees, machine-checked
|
|
43
|
+
|
|
44
|
+
`normalize()` / `normalize_text()` are a **pure function of shape** with invariants checked in CI over every corpus encoding:
|
|
45
|
+
|
|
46
|
+
| Property | Result |
|
|
47
|
+
|---|---|
|
|
48
|
+
| Round-trip — `shape(normalize(x)) == shape(x)` | **3757 / 3757** corpus encodings (100%) |
|
|
49
|
+
| Shape-canonicity — same shape ⟹ same Unicode output | **1993 / 1993** shape groups (100%) |
|
|
50
|
+
| Prefix-stability — word and word+suffix share their prefix encoding | **99.87%** of real corpus pairs |
|
|
51
|
+
|
|
52
|
+
Scope note: normalization is implemented for MNG (Hudum) only — Todo / Sibe / Manchu load shaping rules but have no normalizer yet.
|
|
53
|
+
|
|
54
|
+
This project was generated with [Claude Code](https://claude.ai/code) (AI-assisted coding). The tests and key parts of the core code have been **manually reviewed**, and test coverage is extensive (corpus round-trip / shape-canonicity / prefix-stability plus the upstream cross-implementation suites). Treat this as a **preview release** — it should be fine for normal use; if you hit a problem, please open an [issue or PR](https://github.com/Satsrag/mongol-norm/issues). Shaping logic is derived from UTN #57 v4 and mongfontbuilder.
|
|
55
|
+
|
|
56
|
+
---
|
|
57
|
+
|
|
58
|
+
### Why This Project Exists
|
|
59
|
+
|
|
60
|
+
Traditional Mongolian script in Unicode has a fundamental problem: **the same visible word can be encoded in multiple different Unicode sequences**. This happens because:
|
|
61
|
+
|
|
62
|
+
1. **Letters share glyphs** — A and E look identical in medial and final positions; O and U share forms; QA and GA share forms depending on vowel harmony.
|
|
63
|
+
2. **Multiple encoding paths** — The same tooth glyph (I) can be encoded as I, YA+FVS1, or even two separate I characters.
|
|
64
|
+
|
|
65
|
+

|
|
66
|
+
3. **Redundant FVS usage** — Free Variation Selectors (FVS1–FVS4) can create equivalent sequences that render identically.
|
|
67
|
+
|
|
68
|
+
This means:
|
|
69
|
+
- **Search fails**: Searching for "sain" (one encoding) won't find the same word in another encoding, even though they look identical.
|
|
70
|
+
- **Deduplication breaks**: The same word has multiple Unicode representations.
|
|
71
|
+
- **Indexing is unreliable**: Different encodings of the same word produce different keys.
|
|
72
|
+
|
|
73
|
+
### What This Project Does
|
|
74
|
+
|
|
75
|
+
This is a **shaping-aware normalizer** for Traditional Mongolian. It:
|
|
76
|
+
|
|
77
|
+
1. **Shapes** the input using the full UTN #57 v4 shaping process (5-step conditional mapping)
|
|
78
|
+
2. **Compares** glyph sequences to detect identical visual forms
|
|
79
|
+
3. **Normalizes** to a canonical, human-readable, bare Unicode encoding
|
|
80
|
+
|
|
81
|
+
**Example**: All five of these encode the word "sain" (good) and look identical:
|
|
82
|
+
|
|
83
|
+
|
|
84
|
+
|
|
85
|
+
### How It Works
|
|
86
|
+
|
|
87
|
+
The normalizer implements a **lightweight Mongolian shaping engine** — equivalent to what HarfBuzz does with a font file, but using only the rule data from [UTN #57 v4](https://www.unicode.org/notes/tn57/tn57-4.html) and the [mongfontbuilder](https://github.com/Kushim-Jiang/mongfontbuilder) project. No font files needed.
|
|
88
|
+
|
|
89
|
+
#### Shaping Pipeline (UTN #57 v4 Mongolian-Specific Phase)
|
|
90
|
+
|
|
91
|
+
1. **Chachlag** — Suffix forms for A/E after MVS (Mongolian Vowel Separator)
|
|
92
|
+
2. **Syllabic** — Consonant/vowel context: onset, devsger, marked, masculine/feminine harmony, dotless
|
|
93
|
+
3. **Particle** — MVS particle dictionary lookup for specific suffix words
|
|
94
|
+
4. **Devsger** — I after a vowel (vowel_devsger) gets double-tooth form: `I → I+I`
|
|
95
|
+
5. **Post-bowed** — Vowel forms change after bowed consonants (G, B, K, P, F)
|
|
96
|
+
|
|
97
|
+
#### Normalization Strategy
|
|
98
|
+
|
|
99
|
+
`normalize` is a **pure function of shape**: any two encodings that shape identically produce the same Unicode output, and the output always round-trips — `shape(normalize(x)) == shape(x)`. It is also **prefix-stable**. When these goals conflict the priority is **round-trip > prefix-stable > shortest**.
|
|
100
|
+
|
|
101
|
+
Per word:
|
|
102
|
+
|
|
103
|
+
1. **shape** the input into its written-unit sequence. Structural characters — MVS, nirugu, ZWJ — appear verbatim as `mvs` / `nirugu` / `zwj` tokens (nirugu renders a visible stem; all three are the evidence for a neighbour's init/medi/fina form). **Split** the shape at these tokens into *chains*; the tokens themselves are copied through unchanged.
|
|
104
|
+
2. **encode each chain** (right-to-left, so appending a suffix can't disturb what precedes it):
|
|
105
|
+
1. **partition + table lookup** — the primary path. At each position take the single unit if the table has it (preferred — clean output), else the longest available multi-unit entry, and look up `(position, written-unit) → (letter, FVS)` in an FVS-pinned table. Each value renders its unit **regardless of neighbours**, so the result is a deterministic, O(N), prefix-stable function of the shape.
|
|
106
|
+
2. **velar-feminine refinement** — a `G`/`Gx` velar's forward-coupled vowel (`a`/`o`/`u`) is swapped to its feminine partner (`e`/`oe`/`ue`) for clean output.
|
|
107
|
+
3. **verify** — reshape the candidate in full context; accept only if it equals the target chain shape.
|
|
108
|
+
4. **gap chains** — a handful of chains can't be expressed by table entries alone (bowed-consonant + following-vowel forms like `B+A`; `Sh+I` clusters). These fall back to an exhaustive search over letter partitions and FVS combinations (~13 corpus chains). A letter next to a joiner simply looks its unit up at the shifted (joined) position — no wrapping tricks needed.
|
|
109
|
+
3. **post-MVS suffix rule** — a chain directly after MVS takes its **standalone** canonical (drop the MVS, normalize, re-attach), so the spelling never depends on MVS. One exception: chachlag `Aa` after MVS is written the bare letter `a`. (The isolate-`I` → `i+FVS1` spelling is pinned in the table itself — no post-processing pass exists.)
|
|
110
|
+
|
|
111
|
+
**Prefix-stability** means: if word *A* = word *B* + a suffix and their shapes share a prefix, the shared region encodes identically except the single boundary unit whose position changes (final in *B* → medial in *A*). The per-unit table delivers this for free — each unit's encoding depends only on its own position, never on its neighbours.
|
|
112
|
+
|
|
113
|
+
**How the table is built** (the *selection method*): offline, a **context-independence battery** fills each `(position, written-unit)` slot with the `(letter, FVS)` — tried masculine-first, bare-first — that renders *exactly* that unit in *every* probed neighbour context. The result is exported and shipped as JSON; see `MongolianShaper.compute_normalize_tables()`.
|
|
114
|
+
|
|
115
|
+
> Note: output is **FVS-pinned**, not bare — each unit carries the selector that fixes its form independent of context. This is what makes "same shape ⟹ same Unicode" and prefix-stability hold. The per-unit table is exported as language-agnostic JSON (`mongol_norm/data/MNG.normalize.json`); schema + consuming algorithm are in [docs/data-format.md](docs/data-format.md), so ports in other languages can implement `normalize` with just a JSON parser.
|
|
116
|
+
|
|
117
|
+
### Installation
|
|
118
|
+
|
|
119
|
+
`mongol-norm` is a single self-contained package — the shaping/normalize data is bundled, no separate data package or runtime dependency. Not on PyPI yet — install from source:
|
|
120
|
+
|
|
121
|
+
```bash
|
|
122
|
+
git clone https://github.com/Satsrag/mongol-norm.git
|
|
123
|
+
cd mongol-norm
|
|
124
|
+
pip install .
|
|
125
|
+
```
|
|
126
|
+
|
|
127
|
+
### Usage
|
|
128
|
+
|
|
129
|
+
```python
|
|
130
|
+
from mongol_norm import MongolianShaper
|
|
131
|
+
|
|
132
|
+
shaper = MongolianShaper(locale="MNG") # Hudum Traditional Mongolian
|
|
133
|
+
|
|
134
|
+
# Shape: get written-unit sequence
|
|
135
|
+
shaper.shape("ᠰᠠᠢᠨ")
|
|
136
|
+
# → ['S', 'A', 'I', 'I', 'A']
|
|
137
|
+
|
|
138
|
+
# Compare: are two encodings visually identical?
|
|
139
|
+
shaper.same_shape("ᠰᠠᠢᠨ", "ᠰᠡᠢᠨ")
|
|
140
|
+
# → True
|
|
141
|
+
|
|
142
|
+
shaper.same_shape("ᠰᠠᠢᠨ", "ᠨᠠᠢᠮᠠ")
|
|
143
|
+
# → False
|
|
144
|
+
|
|
145
|
+
# Normalize: canonical bare Unicode
|
|
146
|
+
shaper.normalize("ᠰᠡᠢᠨ")
|
|
147
|
+
# → 'ᠰᠠᠢᠨ'
|
|
148
|
+
|
|
149
|
+
shaper.normalize("ᠰᠠᠶ᠋ᠢᠨ")
|
|
150
|
+
# → 'ᠰᠠᠢᠨ'
|
|
151
|
+
|
|
152
|
+
shaper.normalize("ᠰᠠᠶ᠋ᠶ᠋ᠨ")
|
|
153
|
+
# → 'ᠰᠠᠢᠨ'
|
|
154
|
+
```
|
|
155
|
+
|
|
156
|
+
#### Full-text normalization
|
|
157
|
+
|
|
158
|
+
`normalize()` operates on single words. For sentences, paragraphs, or mixed-script text, use `normalize_text()` — it normalizes each Mongolian word independently while preserving spaces, punctuation, and non-Mongolian text verbatim.
|
|
159
|
+
|
|
160
|
+
```python
|
|
161
|
+
# Normalize a sentence (each Mongolian word normalized independently)
|
|
162
|
+
shaper.normalize_text("ᠰᠡᠢᠨ ᠨᠠᠢᠮᠠ")
|
|
163
|
+
# → 'ᠰᠠᠢᠨ ᠨᠠᠢᠮᠠ'
|
|
164
|
+
|
|
165
|
+
# Mixed script: non-Mongolian text preserved as-is
|
|
166
|
+
shaper.normalize_text("Hello ᠰᠡᠢᠨ world")
|
|
167
|
+
# → 'Hello ᠰᠠᠢᠨ world'
|
|
168
|
+
```
|
|
169
|
+
|
|
170
|
+
#### Batch normalization example
|
|
171
|
+
|
|
172
|
+
```python
|
|
173
|
+
words = ["ᠰᠡᠢᠨ", "ᠰᠠᠢᠨ", "ᠰᠨ᠌ᠢᠢᠨ", "ᠰᠠᠶ᠋ᠢᠨ"]
|
|
174
|
+
normalized = [shaper.normalize(w) for w in words]
|
|
175
|
+
unique = set(normalized)
|
|
176
|
+
print(f"{len(words)} inputs → {len(unique)} unique form(s): {unique}")
|
|
177
|
+
# 4 inputs → 1 unique form(s): {'ᠰᠠᠢᠨ'}
|
|
178
|
+
```
|
|
179
|
+
|
|
180
|
+
#### Command line
|
|
181
|
+
|
|
182
|
+
After `pip install .`, the `mongol-norm` command is on `PATH` (or run `python -m mongol_norm.shaper ...` without installing).
|
|
183
|
+
|
|
184
|
+
```bash
|
|
185
|
+
# Inline text
|
|
186
|
+
mongol-norm shape 'ᠰᠠᠢᠨ' # → S+A+I+I+A
|
|
187
|
+
mongol-norm normalize 'ᠰᠡᠢᠨ' # canonical form
|
|
188
|
+
mongol-norm normalize-text 'Hello ᠰᠡᠢᠨ' # mixed-script
|
|
189
|
+
|
|
190
|
+
# Pipe / stdin (use `-` as the text)
|
|
191
|
+
echo 'ᠰᠡᠢᠨ' | mongol-norm normalize -
|
|
192
|
+
cat doc.txt | mongol-norm normalize-text -
|
|
193
|
+
|
|
194
|
+
# File in / out
|
|
195
|
+
mongol-norm normalize-text -i in.txt -o out.txt
|
|
196
|
+
|
|
197
|
+
# Batch: one word per line in, one canonical per line out
|
|
198
|
+
mongol-norm normalize --batch -i words.txt -o canonical.txt
|
|
199
|
+
|
|
200
|
+
# Visual-identity check (exit 0 if same, 1 if different)
|
|
201
|
+
mongol-norm same 'ᠰᠠᠢᠨ' 'ᠰᠡᠢᠨ'
|
|
202
|
+
```
|
|
203
|
+
|
|
204
|
+
`normalize` (single-word) skips non-Mongolian characters, so feeding it a multi-line file treats the whole thing as one word. Use `--batch` for one-word-per-line files, or `normalize-text` for free-form text.
|
|
205
|
+
|
|
206
|
+
### Running Tests
|
|
207
|
+
|
|
208
|
+
```bash
|
|
209
|
+
cd mongol-norm
|
|
210
|
+
|
|
211
|
+
# Shaping + same_shape + normalize unit tests
|
|
212
|
+
python -m unittest tests.test_shaper -v
|
|
213
|
+
|
|
214
|
+
# Normalize properties: round-trip + shape-canonicity + prefix-stability
|
|
215
|
+
python -m unittest tests.test_round_trip
|
|
216
|
+
|
|
217
|
+
# Normalize-table export (compute == load)
|
|
218
|
+
python -m unittest tests.test_normalize_table
|
|
219
|
+
|
|
220
|
+
# mongfontbuilder core-hud (225) + GB/T 25914-2023 eac-hud (3513, 5 UTN-xfail)
|
|
221
|
+
python -m unittest tests.test_core_hud tests.test_eac_hud
|
|
222
|
+
|
|
223
|
+
# Or all together (auto-discovers every tests/test_*.py)
|
|
224
|
+
python -m unittest discover -s tests -p 'test_*.py'
|
|
225
|
+
```
|
|
226
|
+
|
|
227
|
+
The hand-written suite covers:
|
|
228
|
+
|
|
229
|
+
| Test class | What it checks |
|
|
230
|
+
|------------|---------------|
|
|
231
|
+
| `TestShape` | `shape()` returns correct written-unit sequence (sain variants, the 5 shaping phases step-by-step, UTN-vs-EAC divergences) |
|
|
232
|
+
| `TestSameShape` | `same_shape()` correctly identifies visually identical vs. distinct encodings |
|
|
233
|
+
| `TestNormalize` | `normalize()` produces canonical output; idempotency; normalized result matches original visually |
|
|
234
|
+
| `TestNormalizeText` | `normalize_text()` handles multi-word, mixed-script, punctuation, empty input; idempotency; word independence |
|
|
235
|
+
| `TestNNBSP` | NNBSP ↔ MVS equivalence (UTN model) |
|
|
236
|
+
|
|
237
|
+
Current totals: **142 tests** (unit + property + 225 core-hud + 3513 eac-hud corpus runners), all green on Python 3.9 – 3.13.
|
|
238
|
+
|
|
239
|
+
### Use Cases
|
|
240
|
+
|
|
241
|
+
- **Search & Retrieval** — Index Mongolian text with unique keys per visual word
|
|
242
|
+
- **Deduplication** — Detect identical words encoded differently
|
|
243
|
+
- **Spell Checking** — Normalize before dictionary lookup
|
|
244
|
+
- **Corpus Linguistics** — Consistent word frequency counts
|
|
245
|
+
- **OCR Post-processing** — Standardize OCR output that may use inconsistent encodings
|
|
246
|
+
- **Input Method Engines** — Validate and normalize user input
|
|
247
|
+
|
|
248
|
+
### Project Structure
|
|
249
|
+
|
|
250
|
+
```
|
|
251
|
+
mongol-norm/ # the repo = the package (single, self-contained)
|
|
252
|
+
├── .github/workflows/test.yml # CI: Python 3.9-3.13 on every push
|
|
253
|
+
├── pyproject.toml
|
|
254
|
+
├── mongol_norm/
|
|
255
|
+
│ ├── shaper.py # tokenize / assign_positions / shape / normalize
|
|
256
|
+
│ ├── rules.py # the 5 shaping phases (iii1..iii5) mirroring iii.py
|
|
257
|
+
│ ├── _data.py # loaders for the bundled JSON
|
|
258
|
+
│ └── data/ # bundled shaping + normalize data
|
|
259
|
+
│ ├── MNG.json TOD.json SIB.json MCH.json
|
|
260
|
+
│ └── MNG.normalize.json # per-unit normalize table
|
|
261
|
+
├── scripts/ # dev-only generators (preprocess, gen_normalize_table)
|
|
262
|
+
├── docs/data-format.md # JSON schema, for other-language ports
|
|
263
|
+
└── tests/
|
|
264
|
+
├── test_shaper.py test_round_trip.py test_normalize_table.py
|
|
265
|
+
├── test_core_hud.py test_eac_hud.py
|
|
266
|
+
└── data/{core,eac}-hud.tsv # vendored from mongfontbuilder
|
|
267
|
+
```
|
|
268
|
+
|
|
269
|
+
`mongol-norm` has **no runtime dependencies** — the shaping/normalize JSON is bundled in `mongol_norm/data/`. Not on PyPI yet — install from source.
|
|
270
|
+
|
|
271
|
+
### Data Sources & Acknowledgments
|
|
272
|
+
|
|
273
|
+
- **[UTN #57 v4](https://www.unicode.org/notes/tn57/tn57-4.html)** — Unicode Technical Note: Encoding and Shaping of the Mongolian Script. The authoritative specification for Mongolian shaping rules.
|
|
274
|
+
- **[mongfontbuilder](https://github.com/Kushim-Jiang/mongfontbuilder)** by Kushim Jiang — Source for the bundled flat variant tables in `mongol_norm/data/` (preprocessed from `data.variants` / `data.particles`) and for the `core-hud.tsv` / `eac-hud.tsv` regression suites we vendor into `tests/data/`. Both UTN #57 and mongfontbuilder are authored by the same person.
|
|
275
|
+
- **[GB/T 25914—2023](https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=BD6429DE5A7FC782FAAE13938A07166E)** — China national standard for Traditional Mongolian nominal characters; source of the EAC compliance test set.
|
|
276
|
+
- **[Claude Code](https://claude.ai/code)** — This project was developed with AI assistance. The shaping rules are derived from the above sources; Claude Code was used to implement and structure the engine.
|
|
277
|
+
|
|
278
|
+
### Supported Locales
|
|
279
|
+
|
|
280
|
+
| Locale | Script | Status |
|
|
281
|
+
|--------|--------|--------|
|
|
282
|
+
| MNG | Hudum (Traditional Mongolian) | ✅ Full shaping + normalization |
|
|
283
|
+
| TOD | Todo | ⬜ Shaping rules generated, normalization WIP |
|
|
284
|
+
| SIB | Sibe | ⬜ Shaping rules generated, normalization WIP |
|
|
285
|
+
| MCH | Manchu | ⬜ Shaping rules generated, normalization WIP |
|
|
286
|
+
|
|
287
|
+
### Requirements
|
|
288
|
+
|
|
289
|
+
- Python 3.6+ (CI-tested on 3.9 / 3.10 / 3.11 / 3.12 / 3.13)
|
|
290
|
+
- No runtime dependencies (shaping/normalize data is bundled)
|
|
291
|
+
|
|
292
|
+
### License
|
|
293
|
+
|
|
294
|
+
SIL Open Font License 1.1 (`OFL-1.1`) — consistent with upstream `mongfontbuilder` and UTN #57 sources.
|
|
295
|
+
|
|
296
|
+
---
|
|
297
|
+
|
|
298
|
+
<a id="中文"></a>
|
|
299
|
+
## 中文
|
|
300
|
+
|
|
301
|
+
### 状态
|
|
302
|
+
|
|
303
|
+
库的两部分 —— 整形与规范化(MNG / Hudum)—— 都对照同一批上游语料验证。CI 在每次 push 上对 Python 3.9 – 3.13 跑完整套件。
|
|
304
|
+
|
|
305
|
+
#### ✅ Shaping(整形)
|
|
306
|
+
|
|
307
|
+
`shape()` 和 `same_shape()` 对照两套上游 TSV 套件交叉验证:
|
|
308
|
+
|
|
309
|
+
| 套件 | 用例数 | 通过 | 说明 |
|
|
310
|
+
|---|---|---|---|
|
|
311
|
+
| `mongfontbuilder/core-hud.tsv` | 225 | **100%** | 精选回归集 |
|
|
312
|
+
| `mongfontbuilder/eac-hud.tsv` (GB/T 25914-2023) | 3513 | **100%** | 5 个 UTN ↔ EAC 分歧 case 跳过(跟 mongfontbuilder 自己的 `pytest.mark.xfail` 列表一致) |
|
|
313
|
+
| 手写单元测试 | — | **100%** | shape / same_shape / joiner token(nirugu、ZWJ) |
|
|
314
|
+
|
|
315
|
+
#### ✅ Normalization(规范化)— 与整形同级保障,机器验证
|
|
316
|
+
|
|
317
|
+
`normalize()` / `normalize_text()` 是 **shape 的纯函数**,以下不变量在 CI 中对每一条语料编码逐一验证:
|
|
318
|
+
|
|
319
|
+
| 性质 | 结果 |
|
|
320
|
+
|---|---|
|
|
321
|
+
| 往返 —— `shape(normalize(x)) == shape(x)` | **3757 / 3757** 语料编码(100%) |
|
|
322
|
+
| 同形同码 —— shape 相同 ⟹ 输出 Unicode 相同 | **1993 / 1993** shape 组(100%) |
|
|
323
|
+
| 前缀稳定 —— 词与词+后缀共享前缀编码 | **99.87%** 真实语料词对 |
|
|
324
|
+
|
|
325
|
+
范围说明:规范化目前只实现了 MNG(Hudum)—— Todo / 锡伯文 / 满文已加载 shaping 规则,尚无规范化。
|
|
326
|
+
|
|
327
|
+
本项目由 [Claude Code](https://claude.ai/code)(AI 辅助编码)生成;测试与部分核心代码经**人工审核**,测试覆盖比较充分(语料往返 / 同形同码 / 前缀稳定 + 上游跨实现套件)。当前为**预览版**,正常使用应无问题;遇到问题欢迎提 [issue 和 PR](https://github.com/Satsrag/mongol-norm/issues)。Shaping 逻辑源自 UTN #57 v4 和 mongfontbuilder。
|
|
328
|
+
|
|
329
|
+
---
|
|
330
|
+
|
|
331
|
+
### 为什么做这个项目
|
|
332
|
+
|
|
333
|
+
传统蒙古文在 Unicode 中存在一个根本性问题:**同一个可见词形可以用多种不同的 Unicode 序列编码**。原因是:
|
|
334
|
+
|
|
335
|
+
1. **字母共享字形** — A 和 E 在中间和尾部位置外形完全相同;O 和 U 共享形态;QA 和 GA 根据元音和谐共享形态。
|
|
336
|
+
2. **多种编码路径** — 同一个齿形字形可以编码为 I、YA+FVS1,甚至两个独立的 I 字符。
|
|
337
|
+
|
|
338
|
+

|
|
339
|
+
3. **冗余的 FVS 使用** — 自由变体选择符(FVS1–FVS4)可以创建渲染结果完全相同的等价序列。
|
|
340
|
+
|
|
341
|
+
这意味着:
|
|
342
|
+
- **搜索失效**:搜索同一个词的某种编码,找不到另一种编码,尽管它们外形完全一样。
|
|
343
|
+
- **去重失败**:同一个词有多种 Unicode 表示。
|
|
344
|
+
- **索引不可靠**:同一个词的不同编码产生不同的索引键。
|
|
345
|
+
|
|
346
|
+
### 这个项目做什么
|
|
347
|
+
|
|
348
|
+
这是一个**形态感知的蒙古文规范化器**。它:
|
|
349
|
+
|
|
350
|
+
1. 使用完整的 UTN #57 v4 shaping 过程(5 步条件映射)对输入进行**字形化**
|
|
351
|
+
2. 通过比较字形序列来**检测**视觉上相同的词形
|
|
352
|
+
3. **规范化**为唯一的、人类可读的、bare Unicode 编码
|
|
353
|
+
|
|
354
|
+
**示例**:以下五种编码都表示 "sain"(好的),外形完全相同:
|
|
355
|
+
|
|
356
|
+

|
|
357
|
+
|
|
358
|
+
### 工作原理
|
|
359
|
+
|
|
360
|
+
本规范化器实现了一个**轻量级蒙古文 shaping 引擎**——功能相当于 HarfBuzz 配合字体文件所做的事情,但仅使用 [UTN #57 v4](https://www.unicode.org/notes/tn57/tn57-4.html) 的规则数据和 [mongfontbuilder](https://github.com/Kushim-Jiang/mongfontbuilder) 项目的变体数据。**不需要字体文件**。
|
|
361
|
+
|
|
362
|
+
#### Shaping 管线(UTN #57 v4 蒙古文特定阶段)
|
|
363
|
+
|
|
364
|
+
| 步骤 | 名称 | 说明 |
|
|
365
|
+
|------|------|------|
|
|
366
|
+
| 1 | Chachlag | MVS(蒙古文元音分隔符)后的 a/e 后缀形态 |
|
|
367
|
+
| 2 | Syllabic | 辅音/元音上下文:onset/devsger/marked/阴阳和谐/dotless |
|
|
368
|
+
| 3 | Particle | MVS 小品词词典查找 |
|
|
369
|
+
| 4 | Devsger | 元音后的 i 获得双齿形态:`I → I+I`(vowel_devsger) |
|
|
370
|
+
| 5 | Post-bowed | 弓形辅音(G/B/K/P/F)后的元音形态变化 |
|
|
371
|
+
|
|
372
|
+
#### 规范化策略
|
|
373
|
+
|
|
374
|
+
`normalize` 是 **shape 的纯函数**:任意两个 shape 相同的编码,normalize 输出相同,且始终往返成立 —— `shape(normalize(x)) == shape(x)`,同时**前缀稳定**。三者冲突时优先级:**往返 > 前缀稳定 > 最短**。
|
|
375
|
+
|
|
376
|
+
逐词:
|
|
377
|
+
|
|
378
|
+
1. **shape** 成书写单元序列。结构字符 —— MVS、nirugu、ZWJ —— 原样输出为 `mvs` / `nirugu` / `zwj` token(nirugu 是可见的连笔字形;三者都是邻居字母 init/medi/fina 形的依据)。按这些 token **切成 chain**,token 本身原样拷贝。
|
|
379
|
+
2. **逐 chain 编码**(从右往左,这样加后缀不影响前面):
|
|
380
|
+
1. **划分 + 查表**(主路径):每个位置优先取单单元(输出干净),否则取最长多单元,查 `(位置, 书写单元) → (字母, FVS)` 的 FVS 钉死表。每个值**不依赖邻居**就渲染出该单元 → 确定性、O(N)、前缀稳定。
|
|
381
|
+
2. **velar 阴性微调**:`G`/`Gx` 前向耦合的元音(`a`/`o`/`u`)换成阴性(`e`/`oe`/`ue`),输出更干净。
|
|
382
|
+
3. **校验**:在完整上下文里重新 shape,只接受与目标 chain shape 一致的结果。
|
|
383
|
+
4. **缺口 chain**:少数 chain 仅靠表条目表达不了(弓形辅音+后随元音形如 `B+A`;`Sh+I` 簇),回退到对字母划分×FVS 组合的穷举搜索(语料中约 13 个)。紧邻 joiner 的字母只是按移动后的连接位置查表 —— 不再需要任何包裹技巧。
|
|
384
|
+
3. **MVS 后缀规则**:紧跟 MVS 的 chain 用其 **standalone** canonical(去掉 MVS、归一、再拼回),拼写不依赖 MVS。唯一例外:MVS 后的 chachlag `Aa` 写裸字母 `a`。(孤立 `I` → `i+FVS1` 的拼写已钉进表本身 —— 不存在后处理。)
|
|
385
|
+
|
|
386
|
+
**前缀稳定**的含义:若词 *A* = 词 *B* + 后缀,且二者 shape 共享前缀,则共享部分编码完全一致,只有那个位置发生变化的边界单元不同(在 *B* 里是词尾、在 *A* 里变词中)。逐单元表天然保证这点 —— 每个单元的编码只取决于它自己的位置,与邻居无关。
|
|
387
|
+
|
|
388
|
+
**表是怎么来的**(*选择方法*):离线跑一个 **context 无关性电池** —— 对每个 `(位置, 书写单元)`,按"阳性优先、裸形优先"挑出那个在**所有**探测邻居上下文里都**恰好**渲染出该单元的 `(字母, FVS)`。结果导出成 JSON 随包发布;见 `MongolianShaper.compute_normalize_tables()`。
|
|
389
|
+
|
|
390
|
+
> 注意:输出是 **FVS 钉死**而非 bare —— 每个单元都带着把字形固定住、不受上下文影响的选择符,这正是"同 shape ⟹ 同 Unicode"和前缀稳定成立的原因。逐单元表导出为语言无关的 JSON(`mongol_norm/data/MNG.normalize.json`),schema 与消费算法见 [docs/data-format.md](docs/data-format.md);其他语言只需一个 JSON 解析器即可实现 normalize。
|
|
391
|
+
|
|
392
|
+
### 安装
|
|
393
|
+
|
|
394
|
+
`mongol-norm` 是单一自包含包 —— shaping/normalize 数据已内置,没有独立数据包,也没有运行时依赖。还没发布到 PyPI,从源码本地安装:
|
|
395
|
+
|
|
396
|
+
```bash
|
|
397
|
+
git clone https://github.com/Satsrag/mongol-norm.git
|
|
398
|
+
cd mongol-norm
|
|
399
|
+
pip install .
|
|
400
|
+
```
|
|
401
|
+
|
|
402
|
+
### 使用方法
|
|
403
|
+
|
|
404
|
+
```python
|
|
405
|
+
from mongol_norm import MongolianShaper
|
|
406
|
+
|
|
407
|
+
shaper = MongolianShaper(locale="MNG") # Hudum 传统蒙文
|
|
408
|
+
|
|
409
|
+
# 字形化:获取书写单元序列
|
|
410
|
+
shaper.shape("ᠰᠠᠢᠨ")
|
|
411
|
+
# → ['S', 'A', 'I', 'I', 'A']
|
|
412
|
+
|
|
413
|
+
# 比较:两个编码视觉上是否相同?
|
|
414
|
+
shaper.same_shape("ᠰᠠᠢᠨ", "ᠰᠡᠢᠨ")
|
|
415
|
+
# → True
|
|
416
|
+
|
|
417
|
+
shaper.same_shape("ᠰᠠᠢᠨ", "ᠨᠠᠢᠮᠠ")
|
|
418
|
+
# → False
|
|
419
|
+
|
|
420
|
+
# 规范化:输出唯一的 bare Unicode
|
|
421
|
+
shaper.normalize("ᠰᠡᠢᠨ")
|
|
422
|
+
# → 'ᠰᠠᠢᠨ'
|
|
423
|
+
|
|
424
|
+
shaper.normalize("ᠰᠠᠶ᠋ᠢᠨ")
|
|
425
|
+
# → 'ᠰᠠᠢᠨ'
|
|
426
|
+
|
|
427
|
+
shaper.normalize("ᠰᠠᠶ᠋ᠶ᠋ᠨ")
|
|
428
|
+
# → 'ᠰᠠᠢᠨ'
|
|
429
|
+
```
|
|
430
|
+
|
|
431
|
+
#### 全文规范化
|
|
432
|
+
|
|
433
|
+
`normalize()` 作用于单个词。对于句子、段落或混合文字文本,使用 `normalize_text()` ——它独立规范化每个蒙古文词,同时原样保留空格、标点和非蒙古文文本。
|
|
434
|
+
|
|
435
|
+
```python
|
|
436
|
+
# 规范化句子(每个蒙古文词独立规范化)
|
|
437
|
+
shaper.normalize_text("ᠰᠡᠢᠨ ᠨᠠᠢᠮᠠ")
|
|
438
|
+
# → 'ᠰᠠᠢᠨ ᠨᠠᠢᠮᠠ'
|
|
439
|
+
|
|
440
|
+
# 混合文字:非蒙古文文本原样保留
|
|
441
|
+
shaper.normalize_text("Hello ᠰᠡᠢᠨ world")
|
|
442
|
+
# → 'Hello ᠰᠠᠢᠨ world'
|
|
443
|
+
```
|
|
444
|
+
|
|
445
|
+
#### 批量规范化示例
|
|
446
|
+
|
|
447
|
+
```python
|
|
448
|
+
words = ["ᠰᠡᠢᠨ", "ᠰᠠᠢᠨ", "ᠰᠨ᠌ᠢᠢᠨ", "ᠰᠠᠶ᠋ᠢᠨ"]
|
|
449
|
+
normalized = [shaper.normalize(w) for w in words]
|
|
450
|
+
unique = set(normalized)
|
|
451
|
+
print(f"{len(words)} 个输入 → {len(unique)} 个唯一形态:{unique}")
|
|
452
|
+
# 4 个输入 → 1 个唯一形态:{'ᠰᠠᠢᠨ'}
|
|
453
|
+
```
|
|
454
|
+
|
|
455
|
+
### 运行测试
|
|
456
|
+
|
|
457
|
+
```bash
|
|
458
|
+
cd mongol-norm
|
|
459
|
+
|
|
460
|
+
# 手写 shaper / same_shape / normalize 测试
|
|
461
|
+
python -m unittest tests.test_shaper -v
|
|
462
|
+
|
|
463
|
+
# normalize 性质:往返 + 同 shape 同输出 + 前缀稳定
|
|
464
|
+
python -m unittest tests.test_round_trip
|
|
465
|
+
|
|
466
|
+
# normalize 表导出(compute == load)
|
|
467
|
+
python -m unittest tests.test_normalize_table
|
|
468
|
+
|
|
469
|
+
# mongfontbuilder core-hud(225)+ GB/T 25914-2023 eac-hud(3513,5 个 UTN-xfail)
|
|
470
|
+
python -m unittest tests.test_core_hud tests.test_eac_hud
|
|
471
|
+
|
|
472
|
+
# 或一次跑全部(自动发现所有 tests/test_*.py)
|
|
473
|
+
python -m unittest discover -s tests -p 'test_*.py'
|
|
474
|
+
```
|
|
475
|
+
|
|
476
|
+
手写套件覆盖范围:
|
|
477
|
+
|
|
478
|
+
| 测试类 | 测试内容 |
|
|
479
|
+
|--------|---------|
|
|
480
|
+
| `TestShape` | `shape()` 输出正确的书写单元序列(sain 变体、5 步 shaping 分步测试、UTN-vs-EAC 分歧) |
|
|
481
|
+
| `TestSameShape` | `same_shape()` 正确识别外形相同 vs 不同的编码 |
|
|
482
|
+
| `TestNormalize` | `normalize()` 输出规范结果; 幂等性; 规范化后与原始词形视觉相同 |
|
|
483
|
+
| `TestNormalizeText` | `normalize_text()` 处理多词、混合文字、标点、空输入; 幂等性; 词独立性 |
|
|
484
|
+
| `TestNNBSP` | NNBSP ↔ MVS 等价性(UTN 模型) |
|
|
485
|
+
|
|
486
|
+
当前总数: **142 个测试**(单元 + 性质 + 225 core-hud + 3513 eac-hud 语料跑批), 在 Python 3.9 – 3.13 上全绿。
|
|
487
|
+
|
|
488
|
+
### 应用场景
|
|
489
|
+
|
|
490
|
+
- **搜索与检索** — 为每个可见词形建立唯一索引键
|
|
491
|
+
- **文本去重** — 检测编码不同但外形相同的词
|
|
492
|
+
- **拼写检查** — 规范化后再查词典
|
|
493
|
+
- **语料库语言学** — 一致的词频统计
|
|
494
|
+
- **OCR 后处理** — 标准化可能使用不一致编码的 OCR 输出
|
|
495
|
+
- **输入法引擎** — 验证和规范化用户输入
|
|
496
|
+
|
|
497
|
+
### 项目结构
|
|
498
|
+
|
|
499
|
+
```
|
|
500
|
+
mongol-norm/ # 仓库 = 包(单一自包含)
|
|
501
|
+
├── .github/workflows/test.yml # CI: 每次 push 跑 Python 3.9-3.13
|
|
502
|
+
├── pyproject.toml
|
|
503
|
+
├── mongol_norm/
|
|
504
|
+
│ ├── shaper.py # tokenize / assign_positions / shape / normalize
|
|
505
|
+
│ ├── rules.py # 5 步 shaping 阶段 (iii1..iii5) 镜像 iii.py
|
|
506
|
+
│ ├── _data.py # 内置 JSON 的加载器
|
|
507
|
+
│ └── data/ # 内置 shaping + normalize 数据
|
|
508
|
+
│ ├── MNG.json TOD.json SIB.json MCH.json
|
|
509
|
+
│ └── MNG.normalize.json # 逐单元 normalize 表
|
|
510
|
+
├── scripts/ # 仅开发用的生成脚本 (preprocess, gen_normalize_table)
|
|
511
|
+
├── docs/data-format.md # JSON schema, 供其他语言移植
|
|
512
|
+
└── tests/
|
|
513
|
+
├── test_shaper.py test_round_trip.py test_normalize_table.py
|
|
514
|
+
├── test_core_hud.py test_eac_hud.py
|
|
515
|
+
└── data/{core,eac}-hud.tsv # 来自 mongfontbuilder
|
|
516
|
+
```
|
|
517
|
+
|
|
518
|
+
`mongol-norm` **没有运行时依赖** —— shaping/normalize JSON 内置在 `mongol_norm/data/`。还没上 PyPI, 从源码安装。
|
|
519
|
+
|
|
520
|
+
### 数据来源与致谢
|
|
521
|
+
|
|
522
|
+
- **[UTN #57 v4](https://www.unicode.org/notes/tn57/tn57-4.html)** — Unicode 技术注释:蒙古文编码与字形化。蒙古文 shaping 规则的权威规范。
|
|
523
|
+
- **[mongfontbuilder](https://github.com/Kushim-Jiang/mongfontbuilder)**(Kushim Jiang)— `mongol_norm/data/` 内置扁平变体表的来源(从 `data.variants` / `data.particles` 预处理而来), 同时也是我们 vendor 进 `tests/data/` 的 `core-hud.tsv` / `eac-hud.tsv` 回归套件的来源。UTN #57 和 mongfontbuilder 的作者是同一人。
|
|
524
|
+
- **[GB/T 25914—2023](https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=BD6429DE5A7FC782FAAE13938A07166E)** — 中国国家标准:传统蒙古文名义字符、表现字符和控制字符使用规则; EAC 一致性测试集的来源。
|
|
525
|
+
- **[Claude Code](https://claude.ai/code)** — 本项目使用 AI 辅助开发。shaping 规则来源于上述数据;Claude Code 用于实现和组织引擎代码。
|
|
526
|
+
|
|
527
|
+
### 支持的语种
|
|
528
|
+
|
|
529
|
+
| Locale | 文字 | 状态 |
|
|
530
|
+
|--------|------|------|
|
|
531
|
+
| MNG | Hudum(传统蒙文) | ✅ 完整 shaping + 规范化 |
|
|
532
|
+
| TOD | Todo(托忒文) | ⬜ shaping 规则已生成,规范化开发中 |
|
|
533
|
+
| SIB | Sibe(锡伯文) | ⬜ shaping 规则已生成,规范化开发中 |
|
|
534
|
+
| MCH | Manchu(满文) | ⬜ shaping 规则已生成,规范化开发中 |
|
|
535
|
+
|
|
536
|
+
### 环境要求
|
|
537
|
+
|
|
538
|
+
- Python 3.6+(CI 实测矩阵: 3.9 / 3.10 / 3.11 / 3.12 / 3.13)
|
|
539
|
+
- 无运行时依赖(shaping/normalize 数据已内置)
|
|
540
|
+
|
|
541
|
+
### 许可证
|
|
542
|
+
|
|
543
|
+
SIL Open Font License 1.1 (`OFL-1.1`) — 跟上游 `mongfontbuilder` 和 UTN #57 一致。
|