mlxmc 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- mlxmc-0.1.0/.gitattributes +2 -0
- mlxmc-0.1.0/.github/workflows/tests.yml +52 -0
- mlxmc-0.1.0/.gitignore +21 -0
- mlxmc-0.1.0/CHANGELOG.md +18 -0
- mlxmc-0.1.0/LICENSE +28 -0
- mlxmc-0.1.0/PKG-INFO +200 -0
- mlxmc-0.1.0/README.md +174 -0
- mlxmc-0.1.0/examples/affine_invariance.py +56 -0
- mlxmc-0.1.0/examples/gaussian_ess.py +88 -0
- mlxmc-0.1.0/examples/hard_targets.py +235 -0
- mlxmc-0.1.0/examples/nuts_funnel.py +126 -0
- mlxmc-0.1.0/examples/plot_hard_targets.py +159 -0
- mlxmc-0.1.0/examples/warmup_validation.py +54 -0
- mlxmc-0.1.0/hard_targets_figure.png +0 -0
- mlxmc-0.1.0/pixi.lock +1040 -0
- mlxmc-0.1.0/pyproject.toml +62 -0
- mlxmc-0.1.0/src/mlxmc/__init__.py +26 -0
- mlxmc-0.1.0/src/mlxmc/diagnostics.py +49 -0
- mlxmc-0.1.0/src/mlxmc/ensemble.py +60 -0
- mlxmc-0.1.0/src/mlxmc/hmc.py +59 -0
- mlxmc-0.1.0/src/mlxmc/nuts.py +211 -0
- mlxmc-0.1.0/src/mlxmc/preconditioned.py +56 -0
- mlxmc-0.1.0/src/mlxmc/targets.py +70 -0
- mlxmc-0.1.0/src/mlxmc/warmup.py +178 -0
- mlxmc-0.1.0/tests/conftest.py +21 -0
- mlxmc-0.1.0/tests/test_affine_invariance.py +57 -0
- mlxmc-0.1.0/tests/test_diagnostics.py +36 -0
- mlxmc-0.1.0/tests/test_samplers_gaussian.py +98 -0
- mlxmc-0.1.0/tests/test_warmup.py +37 -0
- mlxmc-0.1.0/tests/util.py +29 -0
|
@@ -0,0 +1,52 @@
|
|
|
1
|
+
name: tests
|
|
2
|
+
|
|
3
|
+
# CI runs only on pull requests to main (plus manual dispatch from the Actions tab) to
|
|
4
|
+
# limit GitHub's macOS runner minutes (billed at 10x Linux). This is a Mac-only package,
|
|
5
|
+
# so every job needs a macOS runner; PRs are deliberate and infrequent, while direct
|
|
6
|
+
# pushes to main do NOT trigger CI. Doc-only changes are skipped via paths-ignore. To
|
|
7
|
+
# also run on pushes, add a `push: { branches: [main] }` key here.
|
|
8
|
+
on:
|
|
9
|
+
workflow_dispatch:
|
|
10
|
+
pull_request:
|
|
11
|
+
branches: [main]
|
|
12
|
+
paths-ignore:
|
|
13
|
+
- '**.md'
|
|
14
|
+
- 'LICENSE'
|
|
15
|
+
- '**.png'
|
|
16
|
+
|
|
17
|
+
# Cancel an in-progress run when the same PR gets a new push -- only the latest commit is
|
|
18
|
+
# worth testing, and it stops macOS jobs from stacking up.
|
|
19
|
+
concurrency:
|
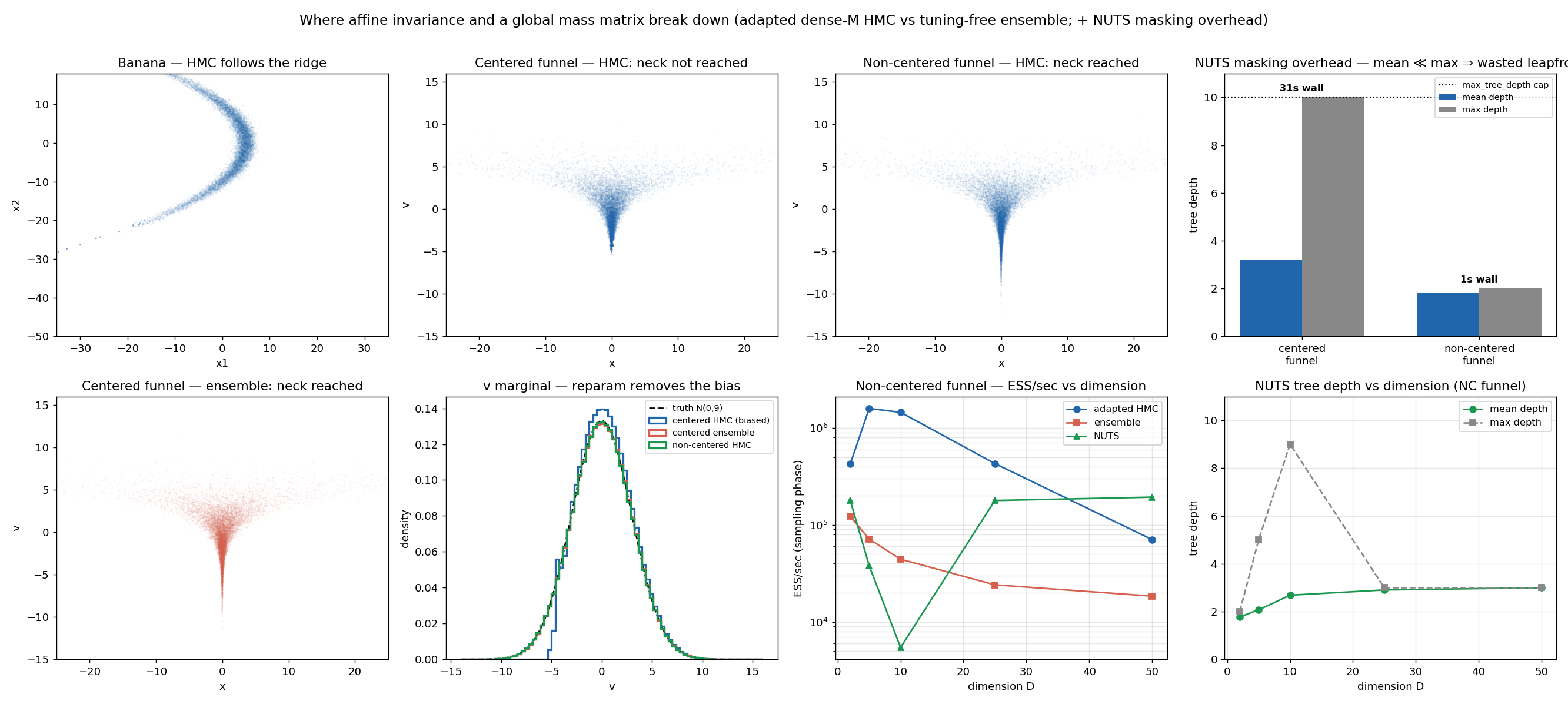
|
20
|
+
group: ${{ github.workflow }}-${{ github.ref }}
|
|
21
|
+
cancel-in-progress: true
|
|
22
|
+
|
|
23
|
+
jobs:
|
|
24
|
+
test:
|
|
25
|
+
# Apple-silicon runner: MLX needs arm64 macOS. The CPU leg is required; the GPU
|
|
26
|
+
# leg is allowed to fail because GitHub's virtualized macOS runners may not expose
|
|
27
|
+
# a usable Metal device (mlxmc is fp32 on both backends, so coverage is equivalent).
|
|
28
|
+
runs-on: macos-14
|
|
29
|
+
strategy:
|
|
30
|
+
fail-fast: false
|
|
31
|
+
matrix:
|
|
32
|
+
device: [cpu, gpu]
|
|
33
|
+
continue-on-error: ${{ matrix.device == 'gpu' }}
|
|
34
|
+
env:
|
|
35
|
+
MLXMC_TEST_DEVICE: ${{ matrix.device }}
|
|
36
|
+
name: test (${{ matrix.device }})
|
|
37
|
+
steps:
|
|
38
|
+
- uses: actions/checkout@v4
|
|
39
|
+
|
|
40
|
+
- uses: prefix-dev/setup-pixi@v0.8.1
|
|
41
|
+
with:
|
|
42
|
+
manifest-path: pyproject.toml
|
|
43
|
+
# Tests run in the default env; the optional `viz` env (matplotlib) isn't needed.
|
|
44
|
+
environments: default
|
|
45
|
+
# Enforce the pixi.lock co-commit invariant: fail if the lock is stale.
|
|
46
|
+
locked: true
|
|
47
|
+
|
|
48
|
+
- name: MLX device info
|
|
49
|
+
run: pixi run python -c "import mlx.core as mx; print('MLX default device:', mx.default_device()); print('requested:', '${{ matrix.device }}')"
|
|
50
|
+
|
|
51
|
+
- name: Run tests
|
|
52
|
+
run: pixi run test
|
mlxmc-0.1.0/.gitignore
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
# pixi environments
|
|
2
|
+
.pixi/*
|
|
3
|
+
!.pixi/config.toml
|
|
4
|
+
|
|
5
|
+
# Python
|
|
6
|
+
__pycache__/
|
|
7
|
+
*.py[cod]
|
|
8
|
+
*.egg-info/
|
|
9
|
+
.ipynb_checkpoints/
|
|
10
|
+
|
|
11
|
+
# Build / test artifacts
|
|
12
|
+
build/
|
|
13
|
+
dist/
|
|
14
|
+
.pytest_cache/
|
|
15
|
+
|
|
16
|
+
# macOS
|
|
17
|
+
.DS_Store
|
|
18
|
+
|
|
19
|
+
# Local project notes / Claude Code instructions — kept on disk, not part of the
|
|
20
|
+
# public package (its findings live in the README instead).
|
|
21
|
+
CLAUDE.md
|
mlxmc-0.1.0/CHANGELOG.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
1
|
+
# Changelog
|
|
2
|
+
|
|
3
|
+
All notable changes to `mlxmc` are documented here. The format follows
|
|
4
|
+
[Keep a Changelog](https://keepachangelog.com/), and the project aims to follow
|
|
5
|
+
[Semantic Versioning](https://semver.org/).
|
|
6
|
+
|
|
7
|
+
## [0.1.0] — 2026-06-03
|
|
8
|
+
|
|
9
|
+
Initial public release.
|
|
10
|
+
|
|
11
|
+
- Affine-invariant ensemble sampler (Goodman & Weare 2010).
|
|
12
|
+
- Hamiltonian Monte Carlo: identity-mass (`hmc`) and preconditioned (`preconditioned`).
|
|
13
|
+
- Stan-style warmup: dual-averaging step size + windowed dense mass-matrix estimation (`warmup`).
|
|
14
|
+
- NUTS (multinomial; Hoffman & Gelman 2014), vectorized over chains, with a NUTS-specific warmup (`nuts`).
|
|
15
|
+
- ESS / integrated-autocorrelation diagnostics (`diagnostics`).
|
|
16
|
+
- Example targets with known moments: correlated Gaussian, banana, centered / non-centered funnel (`targets`).
|
|
17
|
+
|
|
18
|
+
[0.1.0]: https://github.com/jrcheshire/mlxmc/releases/tag/v0.1.0
|
mlxmc-0.1.0/LICENSE
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
1
|
+
BSD 3-Clause License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026, Jamie Cheshire
|
|
4
|
+
|
|
5
|
+
Redistribution and use in source and binary forms, with or without
|
|
6
|
+
modification, are permitted provided that the following conditions are met:
|
|
7
|
+
|
|
8
|
+
1. Redistributions of source code must retain the above copyright notice, this
|
|
9
|
+
list of conditions and the following disclaimer.
|
|
10
|
+
|
|
11
|
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
|
12
|
+
this list of conditions and the following disclaimer in the documentation
|
|
13
|
+
and/or other materials provided with the distribution.
|
|
14
|
+
|
|
15
|
+
3. Neither the name of the copyright holder nor the names of its
|
|
16
|
+
contributors may be used to endorse or promote products derived from
|
|
17
|
+
this software without specific prior written permission.
|
|
18
|
+
|
|
19
|
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
|
20
|
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
|
21
|
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
|
22
|
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
|
23
|
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
|
24
|
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
|
25
|
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
|
26
|
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
|
27
|
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
|
28
|
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
mlxmc-0.1.0/PKG-INFO
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: mlxmc
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: MCMC samplers in Apple MLX
|
|
5
|
+
Project-URL: Homepage, https://github.com/jrcheshire/mlxmc
|
|
6
|
+
Project-URL: Repository, https://github.com/jrcheshire/mlxmc
|
|
7
|
+
Project-URL: Issues, https://github.com/jrcheshire/mlxmc/issues
|
|
8
|
+
Author-email: Jamie Cheshire <cheshire@caltech.edu>
|
|
9
|
+
License-Expression: BSD-3-Clause
|
|
10
|
+
License-File: LICENSE
|
|
11
|
+
Keywords: apple-silicon,bayesian,ensemble-sampler,hmc,mcmc,mlx,nuts,sampling
|
|
12
|
+
Classifier: Development Status :: 3 - Alpha
|
|
13
|
+
Classifier: Intended Audience :: Science/Research
|
|
14
|
+
Classifier: Operating System :: MacOS
|
|
15
|
+
Classifier: Programming Language :: Python :: 3
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
17
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
18
|
+
Classifier: Topic :: Scientific/Engineering
|
|
19
|
+
Classifier: Topic :: Scientific/Engineering :: Mathematics
|
|
20
|
+
Requires-Python: >=3.11
|
|
21
|
+
Requires-Dist: mlx<0.30,>=0.29.3
|
|
22
|
+
Requires-Dist: numpy<3,>=2
|
|
23
|
+
Provides-Extra: viz
|
|
24
|
+
Requires-Dist: matplotlib<4,>=3.10; extra == 'viz'
|
|
25
|
+
Description-Content-Type: text/markdown
|
|
26
|
+
|
|
27
|
+
# mlxmc
|
|
28
|
+
|
|
29
|
+
MCMC samplers written in Apple [MLX](https://github.com/ml-explore/mlx), using its
|
|
30
|
+
`grad` / `vmap` / `compile` transforms. MLX has no probabilistic-programming library
|
|
31
|
+
yet (nothing like BlackJAX or NumPyro), so this is a first pass at one.
|
|
32
|
+
|
|
33
|
+
> **Status: research code.** The samplers are tested (moment recovery, Σ-estimation,
|
|
34
|
+
> affine invariance, and the autocorrelation diagnostics, on both the CPU and Metal
|
|
35
|
+
> backends), but the API is young and likely to change.
|
|
36
|
+
|
|
37
|
+
## What's here
|
|
38
|
+
|
|
39
|
+
The package lives under `src/mlxmc/`; runnable demos and the benchmark study are in
|
|
40
|
+
`examples/`.
|
|
41
|
+
|
|
42
|
+
| Module (`mlxmc.`) | Sampler / tool |
|
|
43
|
+
|---|---|
|
|
44
|
+
| `ensemble` | Affine-invariant ensemble (Goodman & Weare 2010 — the `emcee` stretch move). Gradient-free, tuning-free. `make_sampler`, `run_ensemble`. |
|
|
45
|
+
| `hmc` | Hamiltonian Monte Carlo, identity mass. `grad ∘ vmap` batched over chains. `make_hmc`, `run_hmc`. |
|
|
46
|
+
| `preconditioned` | Mass-matrix HMC (M = Σ⁻¹). `make_phmc`, `run_phmc`. |
|
|
47
|
+
| `warmup` | Stan-style warmup: dual-averaging step size + windowed **dense** mass-matrix estimation. `warmup`, `run_chain`. |
|
|
48
|
+
| `nuts` | NUTS (multinomial; Hoffman & Gelman 2014), vectorized over chains. `make_nuts`, `run_nuts`. |
|
|
49
|
+
| `diagnostics` | Effective sample size / integrated autocorrelation time (FFT + Sokal window); the cross-sampler **ESS/sec** metric. |
|
|
50
|
+
| `targets` | Example log-densities: correlated Gaussian, banana, centered / non-centered funnel, with known moments. |
|
|
51
|
+
|
|
52
|
+
| Example (`examples/`) | What it shows |
|
|
53
|
+
|---|---|
|
|
54
|
+
| `gaussian_ess.py` | Ensemble vs identity-mass HMC vs preconditioned HMC by ESS/sec on the Gaussian. |
|
|
55
|
+
| `warmup_validation.py` | Warmup recovers the true Σ and matches oracle ESS/sec. |
|
|
56
|
+
| `hard_targets.py` | Banana + funnel benchmark (`lscan` / `dscan` modes). |
|
|
57
|
+
| `nuts_funnel.py` | NUTS correctness on the Gaussian; `funnel` mode for the masking-overhead study. |
|
|
58
|
+
| `affine_invariance.py` | Empirical proof of affine invariance (same RNG → bit-identical acceptance under an affine map). |
|
|
59
|
+
| `plot_hard_targets.py` | Renders `hard_targets_figure.png` (needs the optional `viz` env). |
|
|
60
|
+
|
|
61
|
+
## Why MLX
|
|
62
|
+
|
|
63
|
+
`grad`, `vmap`, `jvp`/`vjp`, and `compile` transfer almost directly from JAX,
|
|
64
|
+
with JAX-style functional RNG keys (`mx.random.split`). The wrinkles that shape
|
|
65
|
+
this code:
|
|
66
|
+
|
|
67
|
+
- **No traced control-flow primitives** (no `while_loop` / `scan` / `cond`). MLX
|
|
68
|
+
is eager execution plus `compile` of *static* graphs. Fixed-length unrolled
|
|
69
|
+
loops (leapfrog, fixed-`L` HMC) compile fine; data-dependent trajectory length
|
|
70
|
+
(NUTS) is the hard case — `mlxmc.nuts` runs every chain to a fixed `max_tree_depth`
|
|
71
|
+
and **masks** finished chains.
|
|
72
|
+
- **fp32 on the GPU.** Apple Metal has no fp64 in hardware (MLX has fp64 only on
|
|
73
|
+
the CPU backend). This is fine for sampling — Monte Carlo error (~1/√ESS) swamps
|
|
74
|
+
fp32 roundoff (~1e-6) — but ill-conditioned linear algebra (covariance, Cholesky
|
|
75
|
+
in warmup) is kept host-side in numpy fp64; only the leapfrog runs on the GPU.
|
|
76
|
+
|
|
77
|
+
## Install
|
|
78
|
+
|
|
79
|
+
This is a [pixi](https://pixi.sh) project (installs the package editable):
|
|
80
|
+
|
|
81
|
+
```bash
|
|
82
|
+
pixi install
|
|
83
|
+
pixi run python examples/gaussian_ess.py # ensemble vs HMC vs preconditioned
|
|
84
|
+
pixi run python examples/nuts_funnel.py funnel # several examples have demo modes
|
|
85
|
+
pixi run -e viz python examples/plot_hard_targets.py # plotting needs the optional viz env
|
|
86
|
+
```
|
|
87
|
+
|
|
88
|
+
Or install into any environment with pip: `pip install -e .` (needs `mlx`, so arm64
|
|
89
|
+
macOS). Add the plotting extra with `pip install -e ".[viz]"` (matplotlib).
|
|
90
|
+
|
|
91
|
+
## Usage
|
|
92
|
+
|
|
93
|
+
Every sampler takes a single-point log-density `logp(x) -> scalar` for `x` of
|
|
94
|
+
shape `(D,)`; batching over walkers/chains is handled internally with `vmap`.
|
|
95
|
+
Positions are MLX arrays of shape `(n_chains, D)`.
|
|
96
|
+
|
|
97
|
+
```python
|
|
98
|
+
import mlx.core as mx
|
|
99
|
+
import numpy as np
|
|
100
|
+
|
|
101
|
+
# Target: a strongly correlated 2-D Gaussian (corr 0.9, 25:1 variance ratio).
|
|
102
|
+
# mlxmc.targets ships this one (as `gaussian_logp`) plus banana / funnel.
|
|
103
|
+
mu = mx.array([1.0, -2.0])
|
|
104
|
+
Sig_inv = mx.array(np.linalg.inv([[25.0, 4.5], [4.5, 1.0]]))
|
|
105
|
+
|
|
106
|
+
def logp(x): # x: (D,) -> scalar
|
|
107
|
+
d = x - mu
|
|
108
|
+
return -0.5 * (d @ Sig_inv @ d)
|
|
109
|
+
|
|
110
|
+
key = mx.random.key(0)
|
|
111
|
+
```
|
|
112
|
+
|
|
113
|
+
**Gradient-free ensemble** — no tuning, handles the ill-conditioning for free:
|
|
114
|
+
|
|
115
|
+
```python
|
|
116
|
+
from mlxmc import run_ensemble
|
|
117
|
+
|
|
118
|
+
key, k = mx.random.split(key)
|
|
119
|
+
ensemble = mx.random.normal(shape=(2000, 2), key=k) * 5.0 # (n_walkers, D)
|
|
120
|
+
samples, accept_frac = run_ensemble(logp, ensemble, n_steps=3000, burn=1000, key=key)
|
|
121
|
+
```
|
|
122
|
+
|
|
123
|
+
**HMC, hand-tuned**, and **NUTS after Stan-style warmup** (same `logp`):
|
|
124
|
+
|
|
125
|
+
```python
|
|
126
|
+
from mlxmc import run_hmc, warmup, run_nuts
|
|
127
|
+
|
|
128
|
+
key, k = mx.random.split(key)
|
|
129
|
+
q0 = mx.random.normal(shape=(1000, 2), key=k) * 5.0 # (n_chains, D)
|
|
130
|
+
|
|
131
|
+
samples, acc = run_hmc(logp, q0, n_steps=1500, burn=500,
|
|
132
|
+
eps=0.15, n_leap=40, key=key)
|
|
133
|
+
|
|
134
|
+
# Warmup adapts (eps, dense M); NUTS then adapts trajectory length itself.
|
|
135
|
+
q_last, eps, Minv = warmup(logp, q0, n_warmup=600, n_leap=8, key=key)
|
|
136
|
+
chain, mean_depth, max_depth = run_nuts(logp, q_last, n_samples=1500,
|
|
137
|
+
eps=eps, Minv_np=Minv, key=key)
|
|
138
|
+
```
|
|
139
|
+
|
|
140
|
+
> **Return shapes differ by sampler.** `run_ensemble` and `run_hmc` return
|
|
141
|
+
> `(samples, accept_frac)` with `samples` flattened to `(n_draws, D)`.
|
|
142
|
+
> `run_phmc`, `run_chain` (post-warmup HMC), and `run_nuts` return a structured
|
|
143
|
+
> `(steps, chains, D)` chain — the layout `mlxmc.diagnostics` expects for ESS —
|
|
144
|
+
> and `run_nuts` additionally returns the mean/max tree depth.
|
|
145
|
+
|
|
146
|
+
## Findings
|
|
147
|
+
|
|
148
|
+
|
|
149
|
+
|
|
150
|
+
Validated on a corr-0.9, 25:1-variance Gaussian and on banana / funnel targets;
|
|
151
|
+
every number below is reproducible with the scripts in
|
|
152
|
+
[`examples/`](https://github.com/jrcheshire/mlxmc/tree/main/examples):
|
|
153
|
+
|
|
154
|
+
- **Affine-invariant ensemble** is the robust low-D default: gradient-free,
|
|
155
|
+
tuning-free, handles ill-conditioning for free (acceptance is bit-identical
|
|
156
|
+
under an affine map). But weaker per-step mixing and it degrades with dimension.
|
|
157
|
+
- **HMC** needs gradients and a tuned `eps`/`L`, but mixes far better
|
|
158
|
+
(τ≈2 vs ≈26). A **warmup-adapted dense mass matrix** recovers the true Σ to
|
|
159
|
+
<1% Frobenius error and buys ~7–11× the ESS/sec — HMC's version of affine
|
|
160
|
+
invariance, earned rather than supplied.
|
|
161
|
+
- **Fixed-`L` HMC has a trajectory resonance:** on near-Gaussian targets, when
|
|
162
|
+
`eps·L` lands near a multiple of 2π the trajectory returns to its start and
|
|
163
|
+
mixing collapses. Jittering `eps` per trajectory cures it; NUTS's adaptive
|
|
164
|
+
trajectory length is the principled fix.
|
|
165
|
+
- **NUTS** is validated exact on the Gaussian (recovered covariance 24.97 vs 25)
|
|
166
|
+
and auto-tunes trajectory length, but vectorized NUTS pays a real masking cost
|
|
167
|
+
when trajectory lengths are heterogeneous — with no `while_loop`, every chain
|
|
168
|
+
runs to the deepest chain's tree depth, up to a ~30× wall-time penalty at the
|
|
169
|
+
funnel mouth versus the same target reparametrized.
|
|
170
|
+
- **Geometry matters more than the sampler:** on the *centered* funnel the
|
|
171
|
+
gradient-free ensemble beats a global-metric HMC, because a constant mass matrix
|
|
172
|
+
is wrong everywhere when the scale is position-dependent; a **non-centered
|
|
173
|
+
reparametrization** removes the geometry and makes HMC unbiased again.
|
|
174
|
+
- **ESS/sec is the honest efficiency metric** — acceptance fraction is a
|
|
175
|
+
misleading proxy.
|
|
176
|
+
|
|
177
|
+
## Development
|
|
178
|
+
|
|
179
|
+
```bash
|
|
180
|
+
pixi run test # full suite on the default device
|
|
181
|
+
MLXMC_TEST_DEVICE=cpu pixi run test # force the CPU backend
|
|
182
|
+
MLXMC_TEST_DEVICE=gpu pixi run test # force the Metal GPU
|
|
183
|
+
```
|
|
184
|
+
|
|
185
|
+
The suite (`tests/`) checks moment recovery for every sampler, warmup's Σ
|
|
186
|
+
estimate, the affine-invariance identity, and the autocorrelation-time
|
|
187
|
+
diagnostics. A GitHub Actions workflow (`.github/workflows/tests.yml`) runs the
|
|
188
|
+
CPU + GPU matrix on an Apple-silicon runner for pull requests to `main` (and on
|
|
189
|
+
manual dispatch from the Actions tab). Direct pushes to `main` don't trigger it,
|
|
190
|
+
which keeps the (10x-billed) macOS runner minutes down.
|
|
191
|
+
|
|
192
|
+
## References
|
|
193
|
+
|
|
194
|
+
- Goodman & Weare (2010), *Ensemble samplers with affine invariance.*
|
|
195
|
+
- Hoffman & Gelman (2014), *The No-U-Turn Sampler.*
|
|
196
|
+
- Betancourt (2017), *A Conceptual Introduction to Hamiltonian Monte Carlo.*
|
|
197
|
+
|
|
198
|
+
## License
|
|
199
|
+
|
|
200
|
+
[BSD-3-Clause](https://github.com/jrcheshire/mlxmc/blob/main/LICENSE).
|
mlxmc-0.1.0/README.md
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
1
|
+
# mlxmc
|
|
2
|
+
|
|
3
|
+
MCMC samplers written in Apple [MLX](https://github.com/ml-explore/mlx), using its
|
|
4
|
+
`grad` / `vmap` / `compile` transforms. MLX has no probabilistic-programming library
|
|
5
|
+
yet (nothing like BlackJAX or NumPyro), so this is a first pass at one.
|
|
6
|
+
|
|
7
|
+
> **Status: research code.** The samplers are tested (moment recovery, Σ-estimation,
|
|
8
|
+
> affine invariance, and the autocorrelation diagnostics, on both the CPU and Metal
|
|
9
|
+
> backends), but the API is young and likely to change.
|
|
10
|
+
|
|
11
|
+
## What's here
|
|
12
|
+
|
|
13
|
+
The package lives under `src/mlxmc/`; runnable demos and the benchmark study are in
|
|
14
|
+
`examples/`.
|
|
15
|
+
|
|
16
|
+
| Module (`mlxmc.`) | Sampler / tool |
|
|
17
|
+
|---|---|
|
|
18
|
+
| `ensemble` | Affine-invariant ensemble (Goodman & Weare 2010 — the `emcee` stretch move). Gradient-free, tuning-free. `make_sampler`, `run_ensemble`. |
|
|
19
|
+
| `hmc` | Hamiltonian Monte Carlo, identity mass. `grad ∘ vmap` batched over chains. `make_hmc`, `run_hmc`. |
|
|
20
|
+
| `preconditioned` | Mass-matrix HMC (M = Σ⁻¹). `make_phmc`, `run_phmc`. |
|
|
21
|
+
| `warmup` | Stan-style warmup: dual-averaging step size + windowed **dense** mass-matrix estimation. `warmup`, `run_chain`. |
|
|
22
|
+
| `nuts` | NUTS (multinomial; Hoffman & Gelman 2014), vectorized over chains. `make_nuts`, `run_nuts`. |
|
|
23
|
+
| `diagnostics` | Effective sample size / integrated autocorrelation time (FFT + Sokal window); the cross-sampler **ESS/sec** metric. |
|
|
24
|
+
| `targets` | Example log-densities: correlated Gaussian, banana, centered / non-centered funnel, with known moments. |
|
|
25
|
+
|
|
26
|
+
| Example (`examples/`) | What it shows |
|
|
27
|
+
|---|---|
|
|
28
|
+
| `gaussian_ess.py` | Ensemble vs identity-mass HMC vs preconditioned HMC by ESS/sec on the Gaussian. |
|
|
29
|
+
| `warmup_validation.py` | Warmup recovers the true Σ and matches oracle ESS/sec. |
|
|
30
|
+
| `hard_targets.py` | Banana + funnel benchmark (`lscan` / `dscan` modes). |
|
|
31
|
+
| `nuts_funnel.py` | NUTS correctness on the Gaussian; `funnel` mode for the masking-overhead study. |
|
|
32
|
+
| `affine_invariance.py` | Empirical proof of affine invariance (same RNG → bit-identical acceptance under an affine map). |
|
|
33
|
+
| `plot_hard_targets.py` | Renders `hard_targets_figure.png` (needs the optional `viz` env). |
|
|
34
|
+
|
|
35
|
+
## Why MLX
|
|
36
|
+
|
|
37
|
+
`grad`, `vmap`, `jvp`/`vjp`, and `compile` transfer almost directly from JAX,
|
|
38
|
+
with JAX-style functional RNG keys (`mx.random.split`). The wrinkles that shape
|
|
39
|
+
this code:
|
|
40
|
+
|
|
41
|
+
- **No traced control-flow primitives** (no `while_loop` / `scan` / `cond`). MLX
|
|
42
|
+
is eager execution plus `compile` of *static* graphs. Fixed-length unrolled
|
|
43
|
+
loops (leapfrog, fixed-`L` HMC) compile fine; data-dependent trajectory length
|
|
44
|
+
(NUTS) is the hard case — `mlxmc.nuts` runs every chain to a fixed `max_tree_depth`
|
|
45
|
+
and **masks** finished chains.
|
|
46
|
+
- **fp32 on the GPU.** Apple Metal has no fp64 in hardware (MLX has fp64 only on
|
|
47
|
+
the CPU backend). This is fine for sampling — Monte Carlo error (~1/√ESS) swamps
|
|
48
|
+
fp32 roundoff (~1e-6) — but ill-conditioned linear algebra (covariance, Cholesky
|
|
49
|
+
in warmup) is kept host-side in numpy fp64; only the leapfrog runs on the GPU.
|
|
50
|
+
|
|
51
|
+
## Install
|
|
52
|
+
|
|
53
|
+
This is a [pixi](https://pixi.sh) project (installs the package editable):
|
|
54
|
+
|
|
55
|
+
```bash
|
|
56
|
+
pixi install
|
|
57
|
+
pixi run python examples/gaussian_ess.py # ensemble vs HMC vs preconditioned
|
|
58
|
+
pixi run python examples/nuts_funnel.py funnel # several examples have demo modes
|
|
59
|
+
pixi run -e viz python examples/plot_hard_targets.py # plotting needs the optional viz env
|
|
60
|
+
```
|
|
61
|
+
|
|
62
|
+
Or install into any environment with pip: `pip install -e .` (needs `mlx`, so arm64
|
|
63
|
+
macOS). Add the plotting extra with `pip install -e ".[viz]"` (matplotlib).
|
|
64
|
+
|
|
65
|
+
## Usage
|
|
66
|
+
|
|
67
|
+
Every sampler takes a single-point log-density `logp(x) -> scalar` for `x` of
|
|
68
|
+
shape `(D,)`; batching over walkers/chains is handled internally with `vmap`.
|
|
69
|
+
Positions are MLX arrays of shape `(n_chains, D)`.
|
|
70
|
+
|
|
71
|
+
```python
|
|
72
|
+
import mlx.core as mx
|
|
73
|
+
import numpy as np
|
|
74
|
+
|
|
75
|
+
# Target: a strongly correlated 2-D Gaussian (corr 0.9, 25:1 variance ratio).
|
|
76
|
+
# mlxmc.targets ships this one (as `gaussian_logp`) plus banana / funnel.
|
|
77
|
+
mu = mx.array([1.0, -2.0])
|
|
78
|
+
Sig_inv = mx.array(np.linalg.inv([[25.0, 4.5], [4.5, 1.0]]))
|
|
79
|
+
|
|
80
|
+
def logp(x): # x: (D,) -> scalar
|
|
81
|
+
d = x - mu
|
|
82
|
+
return -0.5 * (d @ Sig_inv @ d)
|
|
83
|
+
|
|
84
|
+
key = mx.random.key(0)
|
|
85
|
+
```
|
|
86
|
+
|
|
87
|
+
**Gradient-free ensemble** — no tuning, handles the ill-conditioning for free:
|
|
88
|
+
|
|
89
|
+
```python
|
|
90
|
+
from mlxmc import run_ensemble
|
|
91
|
+
|
|
92
|
+
key, k = mx.random.split(key)
|
|
93
|
+
ensemble = mx.random.normal(shape=(2000, 2), key=k) * 5.0 # (n_walkers, D)
|
|
94
|
+
samples, accept_frac = run_ensemble(logp, ensemble, n_steps=3000, burn=1000, key=key)
|
|
95
|
+
```
|
|
96
|
+
|
|
97
|
+
**HMC, hand-tuned**, and **NUTS after Stan-style warmup** (same `logp`):
|
|
98
|
+
|
|
99
|
+
```python
|
|
100
|
+
from mlxmc import run_hmc, warmup, run_nuts
|
|
101
|
+
|
|
102
|
+
key, k = mx.random.split(key)
|
|
103
|
+
q0 = mx.random.normal(shape=(1000, 2), key=k) * 5.0 # (n_chains, D)
|
|
104
|
+
|
|
105
|
+
samples, acc = run_hmc(logp, q0, n_steps=1500, burn=500,
|
|
106
|
+
eps=0.15, n_leap=40, key=key)
|
|
107
|
+
|
|
108
|
+
# Warmup adapts (eps, dense M); NUTS then adapts trajectory length itself.
|
|
109
|
+
q_last, eps, Minv = warmup(logp, q0, n_warmup=600, n_leap=8, key=key)
|
|
110
|
+
chain, mean_depth, max_depth = run_nuts(logp, q_last, n_samples=1500,
|
|
111
|
+
eps=eps, Minv_np=Minv, key=key)
|
|
112
|
+
```
|
|
113
|
+
|
|
114
|
+
> **Return shapes differ by sampler.** `run_ensemble` and `run_hmc` return
|
|
115
|
+
> `(samples, accept_frac)` with `samples` flattened to `(n_draws, D)`.
|
|
116
|
+
> `run_phmc`, `run_chain` (post-warmup HMC), and `run_nuts` return a structured
|
|
117
|
+
> `(steps, chains, D)` chain — the layout `mlxmc.diagnostics` expects for ESS —
|
|
118
|
+
> and `run_nuts` additionally returns the mean/max tree depth.
|
|
119
|
+
|
|
120
|
+
## Findings
|
|
121
|
+
|
|
122
|
+

|
|
123
|
+
|
|
124
|
+
Validated on a corr-0.9, 25:1-variance Gaussian and on banana / funnel targets;
|
|
125
|
+
every number below is reproducible with the scripts in
|
|
126
|
+
[`examples/`](https://github.com/jrcheshire/mlxmc/tree/main/examples):
|
|
127
|
+
|
|
128
|
+
- **Affine-invariant ensemble** is the robust low-D default: gradient-free,
|
|
129
|
+
tuning-free, handles ill-conditioning for free (acceptance is bit-identical
|
|
130
|
+
under an affine map). But weaker per-step mixing and it degrades with dimension.
|
|
131
|
+
- **HMC** needs gradients and a tuned `eps`/`L`, but mixes far better
|
|
132
|
+
(τ≈2 vs ≈26). A **warmup-adapted dense mass matrix** recovers the true Σ to
|
|
133
|
+
<1% Frobenius error and buys ~7–11× the ESS/sec — HMC's version of affine
|
|
134
|
+
invariance, earned rather than supplied.
|
|
135
|
+
- **Fixed-`L` HMC has a trajectory resonance:** on near-Gaussian targets, when
|
|
136
|
+
`eps·L` lands near a multiple of 2π the trajectory returns to its start and
|
|
137
|
+
mixing collapses. Jittering `eps` per trajectory cures it; NUTS's adaptive
|
|
138
|
+
trajectory length is the principled fix.
|
|
139
|
+
- **NUTS** is validated exact on the Gaussian (recovered covariance 24.97 vs 25)
|
|
140
|
+
and auto-tunes trajectory length, but vectorized NUTS pays a real masking cost
|
|
141
|
+
when trajectory lengths are heterogeneous — with no `while_loop`, every chain
|
|
142
|
+
runs to the deepest chain's tree depth, up to a ~30× wall-time penalty at the
|
|
143
|
+
funnel mouth versus the same target reparametrized.
|
|
144
|
+
- **Geometry matters more than the sampler:** on the *centered* funnel the
|
|
145
|
+
gradient-free ensemble beats a global-metric HMC, because a constant mass matrix
|
|
146
|
+
is wrong everywhere when the scale is position-dependent; a **non-centered
|
|
147
|
+
reparametrization** removes the geometry and makes HMC unbiased again.
|
|
148
|
+
- **ESS/sec is the honest efficiency metric** — acceptance fraction is a
|
|
149
|
+
misleading proxy.
|
|
150
|
+
|
|
151
|
+
## Development
|
|
152
|
+
|
|
153
|
+
```bash
|
|
154
|
+
pixi run test # full suite on the default device
|
|
155
|
+
MLXMC_TEST_DEVICE=cpu pixi run test # force the CPU backend
|
|
156
|
+
MLXMC_TEST_DEVICE=gpu pixi run test # force the Metal GPU
|
|
157
|
+
```
|
|
158
|
+
|
|
159
|
+
The suite (`tests/`) checks moment recovery for every sampler, warmup's Σ
|
|
160
|
+
estimate, the affine-invariance identity, and the autocorrelation-time
|
|
161
|
+
diagnostics. A GitHub Actions workflow (`.github/workflows/tests.yml`) runs the
|
|
162
|
+
CPU + GPU matrix on an Apple-silicon runner for pull requests to `main` (and on
|
|
163
|
+
manual dispatch from the Actions tab). Direct pushes to `main` don't trigger it,
|
|
164
|
+
which keeps the (10x-billed) macOS runner minutes down.
|
|
165
|
+
|
|
166
|
+
## References
|
|
167
|
+
|
|
168
|
+
- Goodman & Weare (2010), *Ensemble samplers with affine invariance.*
|
|
169
|
+
- Hoffman & Gelman (2014), *The No-U-Turn Sampler.*
|
|
170
|
+
- Betancourt (2017), *A Conceptual Introduction to Hamiltonian Monte Carlo.*
|
|
171
|
+
|
|
172
|
+
## License
|
|
173
|
+
|
|
174
|
+
[BSD-3-Clause](https://github.com/jrcheshire/mlxmc/blob/main/LICENSE).
|
|
@@ -0,0 +1,56 @@
|
|
|
1
|
+
"""Empirical proof of affine invariance for the G&W ensemble sampler.
|
|
2
|
+
|
|
3
|
+
Map the base target p(x) through y = A x + b to q(y) = p(A^{-1}(y-b)). Running
|
|
4
|
+
the sampler on q from the affine-mapped initial ensemble, with the SAME random
|
|
5
|
+
stream, must reproduce the base run exactly mapped: y_t = A x_t + b for every
|
|
6
|
+
walker and step. So acceptance and mixing are identical -- a 256x-worse-
|
|
7
|
+
conditioned target costs nothing extra. (Exact to float32; a borderline accept
|
|
8
|
+
can rarely flip, which would show up as a large deviation.)
|
|
9
|
+
"""
|
|
10
|
+
import mlx.core as mx
|
|
11
|
+
import numpy as np
|
|
12
|
+
|
|
13
|
+
from mlxmc.ensemble import run_ensemble
|
|
14
|
+
|
|
15
|
+
rng = np.random.default_rng(0)
|
|
16
|
+
D = 3
|
|
17
|
+
|
|
18
|
+
# Base target: isotropic standard normal.
|
|
19
|
+
def logp_base(x):
|
|
20
|
+
return -0.5 * (x @ x)
|
|
21
|
+
|
|
22
|
+
# Ill-conditioned affine map: random rotation times scales [8, 2, 0.5].
|
|
23
|
+
Q, _ = np.linalg.qr(rng.standard_normal((D, D)))
|
|
24
|
+
A_np = Q @ np.diag([8.0, 2.0, 0.5]) # cond(A)=16 -> cond(Sigma)=256
|
|
25
|
+
b_np = np.array([3.0, -5.0, 1.0])
|
|
26
|
+
A = mx.array(A_np)
|
|
27
|
+
A_T = mx.transpose(A)
|
|
28
|
+
b = mx.array(b_np)
|
|
29
|
+
Ainv = mx.array(np.linalg.inv(A_np))
|
|
30
|
+
|
|
31
|
+
# Transformed target q(y) = N(b, A A^T): logq(y) = -0.5 |A^{-1}(y-b)|^2.
|
|
32
|
+
def logq(y):
|
|
33
|
+
r = Ainv @ (y - b)
|
|
34
|
+
return -0.5 * (r @ r)
|
|
35
|
+
|
|
36
|
+
n_walkers, n_steps, burn = 200, 100, 0 # init is in equilibrium, no burn needed
|
|
37
|
+
key = mx.random.key(42)
|
|
38
|
+
key, k_init = mx.random.split(key)
|
|
39
|
+
E0 = mx.random.normal(shape=(n_walkers, D), key=k_init) # matched to base N(0, I)
|
|
40
|
+
E0_mapped = E0 @ A_T + b # matched to q = N(b, A A^T)
|
|
41
|
+
|
|
42
|
+
# SAME key for both runs -> identical random stream.
|
|
43
|
+
xs, acc_base = run_ensemble(logp_base, E0, n_steps, burn, key)
|
|
44
|
+
ys, acc_tr = run_ensemble(logq, E0_mapped, n_steps, burn, key)
|
|
45
|
+
|
|
46
|
+
mapped = xs @ A_T + b
|
|
47
|
+
max_dev = float(mx.max(mx.abs(ys - mapped)))
|
|
48
|
+
|
|
49
|
+
print(f"condition number: base target 1 | transformed target {np.linalg.cond(A_np @ A_np.T):.0f}")
|
|
50
|
+
print(f"acceptance: base {acc_base:.6f} transformed {acc_tr:.6f} (identical => invariant)")
|
|
51
|
+
print(f"max |y - (A x + b)| over {ys.shape[0]:,} samples: {max_dev:.2e} (=> exact affine image, to float32)")
|
|
52
|
+
|
|
53
|
+
y = np.array(ys)
|
|
54
|
+
print("\ntransformed run recovers N(b, A A^T):")
|
|
55
|
+
print(f" mean recovered {np.round(y.mean(0), 2)} vs true {b_np}")
|
|
56
|
+
print(f" cov diag recovered {np.round(np.cov(y.T).diagonal(), 1)} vs true {np.round((A_np @ A_np.T).diagonal(), 1)}")
|
|
@@ -0,0 +1,88 @@
|
|
|
1
|
+
"""The Gaussian ESS story: affine-invariant ensemble vs identity-mass HMC vs
|
|
2
|
+
preconditioned HMC (M = Sigma^{-1}), compared by ESS/sec on the canonical
|
|
3
|
+
correlated 2-D Gaussian (corr 0.9, 25:1 variance ratio).
|
|
4
|
+
|
|
5
|
+
The point: the ensemble handles the ill-conditioning for free (no tuning, no
|
|
6
|
+
gradients); identity-mass HMC pays for the bad conditioning in mixing; supplying
|
|
7
|
+
the right mass matrix (here the true Sigma) is HMC's affine invariance and recovers
|
|
8
|
+
the gap with far fewer, cheaper leapfrog steps. `examples/warmup_validation.py`
|
|
9
|
+
shows the same M *estimated* during warmup rather than supplied.
|
|
10
|
+
|
|
11
|
+
ESS needs the per-chain structure, so these local runners retain the (T, N, D)
|
|
12
|
+
chain -- unlike the library's run_ensemble/run_hmc, which flatten for moment recovery.
|
|
13
|
+
|
|
14
|
+
Run: python examples/gaussian_ess.py
|
|
15
|
+
"""
|
|
16
|
+
import time
|
|
17
|
+
|
|
18
|
+
import mlx.core as mx
|
|
19
|
+
import numpy as np
|
|
20
|
+
|
|
21
|
+
from mlxmc.diagnostics import report
|
|
22
|
+
from mlxmc.ensemble import make_sampler
|
|
23
|
+
from mlxmc.hmc import make_hmc
|
|
24
|
+
from mlxmc.preconditioned import run_phmc
|
|
25
|
+
from mlxmc.targets import GAUSSIAN_SIGMA, gaussian_logp
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
def run_ensemble_chain(e0, n_steps, burn, key, a=2.0):
|
|
29
|
+
n_walkers, n_dim = e0.shape
|
|
30
|
+
half = n_walkers // 2
|
|
31
|
+
update = make_sampler(gaussian_logp, n_dim, a)
|
|
32
|
+
chain, e = [], e0
|
|
33
|
+
for t in range(n_steps):
|
|
34
|
+
key, k0, k1 = mx.random.split(key, 3)
|
|
35
|
+
h0, h1 = e[:half], e[half:]
|
|
36
|
+
h0, _ = update(h0, h1, k0)
|
|
37
|
+
h1, _ = update(h1, h0, k1)
|
|
38
|
+
e = mx.concatenate([h0, h1], axis=0)
|
|
39
|
+
mx.eval(e)
|
|
40
|
+
if t >= burn:
|
|
41
|
+
chain.append(e)
|
|
42
|
+
return mx.stack(chain, axis=0)
|
|
43
|
+
|
|
44
|
+
|
|
45
|
+
def run_hmc_chain(q0, n_steps, burn, eps, n_leap, key):
|
|
46
|
+
step = make_hmc(gaussian_logp, eps, n_leap)
|
|
47
|
+
chain, q = [], q0
|
|
48
|
+
for t in range(n_steps):
|
|
49
|
+
key, k = mx.random.split(key, 2)
|
|
50
|
+
q, _ = step(q, k)
|
|
51
|
+
mx.eval(q)
|
|
52
|
+
if t >= burn:
|
|
53
|
+
chain.append(q)
|
|
54
|
+
return mx.stack(chain, axis=0)
|
|
55
|
+
|
|
56
|
+
|
|
57
|
+
if __name__ == "__main__":
|
|
58
|
+
Sigma = GAUSSIAN_SIGMA
|
|
59
|
+
Minv = Sigma # M^{-1} = Sigma
|
|
60
|
+
Mhalf = np.linalg.cholesky(np.linalg.inv(Sigma)) # chol(M), M = Sigma^{-1}
|
|
61
|
+
key = mx.random.key(0)
|
|
62
|
+
|
|
63
|
+
key, ki = mx.random.split(key)
|
|
64
|
+
ens0 = mx.random.normal(shape=(2000, 2), key=ki) * 5.0
|
|
65
|
+
t0 = time.time()
|
|
66
|
+
ec = run_ensemble_chain(ens0, 2000, 500, key)
|
|
67
|
+
mx.eval(ec)
|
|
68
|
+
e_ess, e_dt = report(ec, "ensemble (no grad, no tuning)", time.time() - t0)
|
|
69
|
+
|
|
70
|
+
key, ki = mx.random.split(key)
|
|
71
|
+
q0 = mx.random.normal(shape=(1000, 2), key=ki) * 5.0
|
|
72
|
+
t0 = time.time()
|
|
73
|
+
hc = run_hmc_chain(q0, 1500, 500, 0.15, 40, key)
|
|
74
|
+
mx.eval(hc)
|
|
75
|
+
h_ess, h_dt = report(hc, "HMC identity mass (eps=0.15, L=40)", time.time() - t0)
|
|
76
|
+
|
|
77
|
+
key, ki = mx.random.split(key)
|
|
78
|
+
q0p = mx.random.normal(shape=(1000, 2), key=ki) * 5.0
|
|
79
|
+
t0 = time.time()
|
|
80
|
+
pc = run_phmc(gaussian_logp, q0p, 1500, 500, 0.7, 6, key, Minv, Mhalf)
|
|
81
|
+
mx.eval(pc)
|
|
82
|
+
p_ess, p_dt = report(pc, "HMC preconditioned M=Sigma^-1 (eps=0.7, L=6)", time.time() - t0)
|
|
83
|
+
|
|
84
|
+
print("\n=== ESS/sec ===")
|
|
85
|
+
print(f" ensemble: {e_ess / e_dt:>10,.0f}")
|
|
86
|
+
print(f" HMC identity: {h_ess / h_dt:>10,.0f}")
|
|
87
|
+
print(f" HMC precond: {p_ess / p_dt:>10,.0f} "
|
|
88
|
+
f"({(p_ess / p_dt) / (h_ess / h_dt):.1f}x identity HMC, L=6 vs 40 -> 7/41 the gradients/step)")
|