meilisearch-python-sdk 5.2.0__tar.gz → 5.3.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.pre-commit-config.yaml +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/CONTRIBUTING.md +2 -2
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/PKG-INFO +2 -2
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/README.md +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/async_index_api.md +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/json_handler.md +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/plugins.md +6 -6
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/pydantic.md +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_client.py +3 -3
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_task.py +4 -4
- meilisearch_python_sdk-5.3.0/meilisearch_python_sdk/_version.py +1 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/decorators.py +6 -6
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/index.py +33 -23
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/pyproject.toml +1 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_async_documents.py +12 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_async_search.py +4 -4
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_documents.py +12 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_search.py +4 -4
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/uv.lock +106 -102
- meilisearch_python_sdk-5.2.0/meilisearch_python_sdk/_version.py +0 -1
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/FUNDING.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/release-draft-template.yaml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/renovate.json5 +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/workflows/docs_publish.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/workflows/nightly_testing.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/workflows/pypi_publish.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/workflows/release-drafter.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.github/workflows/testing.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/.gitignore +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/LICENSE +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/assets/add_in_batches.png +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/assets/searches.png +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/codecov.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/datasets/small_movies.json +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docker-compose.https.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docker-compose.yml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/.nojekyll +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/CNAME +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/async_client_api.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/client_api.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/css/custom.css +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/decorators_api.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/index.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/index_api.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/js/umami.js +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/docs/overrides/partials/footer.html +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/.gitignore +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/README.md +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/__init__.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/add_documents_decorator.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/add_documents_in_batches.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/async_add_documents_decorator.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/async_add_documents_in_batches.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/async_documents_and_search_results.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/async_search_tracker.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/async_update_settings.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/documents_and_search_results.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/fastapi_example.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/orjson_example.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/pyproject.toml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/requirements.txt +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/search_tracker.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/tests/__init__.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/tests/conftest.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/tests/test_async_examples.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/tests/test_examples.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/ujson_example.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/examples/update_settings.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/justfile +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/__init__.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_batch.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_http_requests.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_utils.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/errors.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/json_handler.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/__init__.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/batch.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/client.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/documents.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/health.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/index.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/search.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/settings.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/task.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/version.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/models/webhook.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/plugins.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/py.typed +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/types.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/mkdocs.yaml +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/__init__.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/conftest.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_async_client.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_async_index.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_async_index_plugins.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_client.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_decorators.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_errors.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_index.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_index_plugins.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_settings_models.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_utils.py +0 -0
- {meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/tests/test_version.py +0 -0
|
@@ -164,7 +164,7 @@ Now with the container running, run the test suite
|
|
|
164
164
|
uv run pytest
|
|
165
165
|
```
|
|
166
166
|
|
|
167
|
-
In
|
|
167
|
+
In addition to mainting the coverage percentage please ensure that all
|
|
168
168
|
tests are passing before submitting a pull request.
|
|
169
169
|
|
|
170
170
|
#### just
|
|
@@ -288,7 +288,7 @@ git fetch upstream
|
|
|
288
288
|
git rebase upstream/main
|
|
289
289
|
```
|
|
290
290
|
|
|
291
|
-
There may be some merge
|
|
291
|
+
There may be some merge conflicts that need to be resolved. After the feature branch has been update
|
|
292
292
|
locally, you can now update your pull request by pushing to the branch on GitHub:
|
|
293
293
|
|
|
294
294
|
```sh
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: meilisearch-python-sdk
|
|
3
|
-
Version: 5.
|
|
3
|
+
Version: 5.3.0
|
|
4
4
|
Summary: A Python client providing both async and sync support for the Meilisearch API
|
|
5
5
|
Project-URL: repository, https://github.com/sanders41/meilisearch-python-sdk
|
|
6
6
|
Project-URL: homepage, https://github.com/sanders41/meilisearch-python-sdk
|
|
@@ -252,7 +252,7 @@ Meilisearch takes to index the documents since that is outside of the library fu
|
|
|
252
252
|
|
|
253
253
|
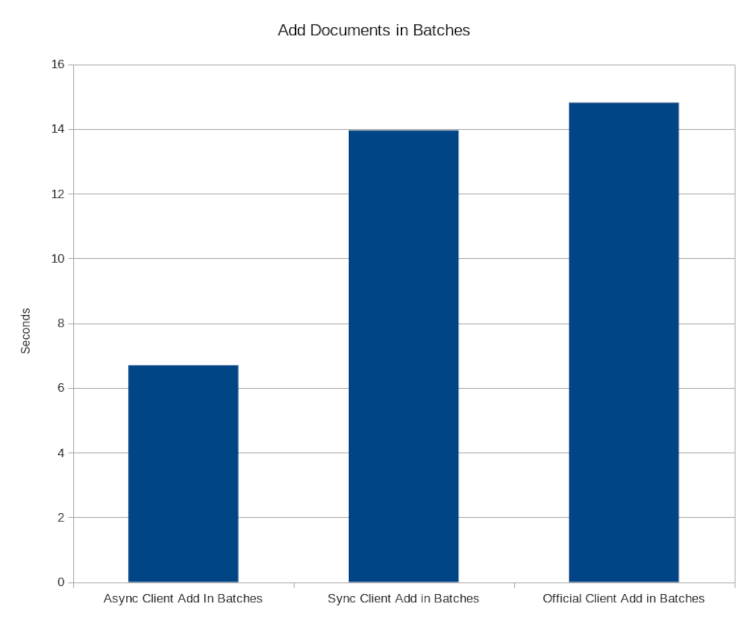
|
|
254
254
|
|
|
255
|
-
###
|
|
255
|
+
### Multiple Searches
|
|
256
256
|
|
|
257
257
|
This test compares how long it takes to complete 1000 searches (lower is better)
|
|
258
258
|
|
|
@@ -196,7 +196,7 @@ Meilisearch takes to index the documents since that is outside of the library fu
|
|
|
196
196
|
|
|
197
197
|

|
|
198
198
|
|
|
199
|
-
###
|
|
199
|
+
### Multiple Searches
|
|
200
200
|
|
|
201
201
|
This test compares how long it takes to complete 1000 searches (lower is better)
|
|
202
202
|
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
## `AsyncIndex` Usage
|
|
2
2
|
|
|
3
|
-
The `AsyncIndex` is the the same as the `Index`, but gives
|
|
3
|
+
The `AsyncIndex` is the the same as the `Index`, but gives asynchronous methods to work with, and
|
|
4
4
|
and should be used when using the `AsyncClient`. When you create a new index with the `AsyncClient`
|
|
5
5
|
it will create an `AsyncIndex` instance.
|
|
6
6
|
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
# JSON Handler
|
|
2
2
|
|
|
3
|
-
For json loads and dumps you have the option to use the `json` module from the standard
|
|
3
|
+
For json loads and dumps you have the option to use the `json` module from the standard library,
|
|
4
4
|
orjson, or ujson. This done by setting the `json_handler` when creating the `AsyncClient` or
|
|
5
5
|
`Client`. By default the standard library `json` module will be used. The examples below use
|
|
6
6
|
`Client`, and the same options are available for `AsyncClient`.
|
|
@@ -15,7 +15,7 @@ is done through a named tuple that specifies where the plugin should run. The op
|
|
|
15
15
|
- update_documents_plugins: Run on the `update_document` method.
|
|
16
16
|
|
|
17
17
|
When creating your plugin you specify if you want it to run before or after the default
|
|
18
|
-
functionality.
|
|
18
|
+
functionality. Additionally plugins for async indexes can be run concurrently with the default
|
|
19
19
|
functionality.
|
|
20
20
|
|
|
21
21
|
## Examples:
|
|
@@ -27,9 +27,9 @@ way to track this out of the box. A search plugin could be used to implement thi
|
|
|
27
27
|
yourself.
|
|
28
28
|
|
|
29
29
|
Note that in these examples the protocol is satisfied by providing the `CONNECURRENT_EVENT`,
|
|
30
|
-
`POST_EVENT`, and `PRE_EVENT`
|
|
30
|
+
`POST_EVENT`, and `PRE_EVENT` variables and the
|
|
31
31
|
`async def run_plugin(self, event: AsyncEvent, **kwargs: Any) -> None:` method for an async index,
|
|
32
|
-
or the `POST_EVENT` and `PRE_EVENT`
|
|
32
|
+
or the `POST_EVENT` and `PRE_EVENT` variables , and
|
|
33
33
|
`def run_plugin(self, event: Event, **kwargs: Any) -> None:` method for a non-async index. You
|
|
34
34
|
class can contain any additional methods/variables needed as long as the protocol requirements
|
|
35
35
|
have been satisfied.
|
|
@@ -160,12 +160,12 @@ if __name__ == "__main__":
|
|
|
160
160
|
### Modify documents and search results
|
|
161
161
|
|
|
162
162
|
A pre event plugin can be used to modify the documents before sending for indexing. In this example
|
|
163
|
-
a new `access` field will be added to the
|
|
163
|
+
a new `access` field will be added to the documents before they are added or updated. The example
|
|
164
164
|
will set every other record to `admin` access with the other records being set to `read`. This will
|
|
165
|
-
illustrate the idea of
|
|
165
|
+
illustrate the idea of modifying documents even it if doesn't make real world sense.
|
|
166
166
|
|
|
167
167
|
A post search plugin, this type of search plugin can only be used post search because it requires
|
|
168
|
-
the result of the search, will be used to remove records marked as `admin` before
|
|
168
|
+
the result of the search, will be used to remove records marked as `admin` before returning the result.
|
|
169
169
|
In the real world this filtering would probably be done with a filterable field in Meilisearch,but
|
|
170
170
|
again, this is just used here to illustrate the idea.
|
|
171
171
|
|
|
@@ -55,7 +55,7 @@ Movie(
|
|
|
55
55
|
```
|
|
56
56
|
|
|
57
57
|
By inheriting from CamelBase, or any of the other [provided models](https://github.com/sanders41/meilisearch-python-sdk/tree/main/meilisearch_python_sdk/models)
|
|
58
|
-
you will be inheriting Pydantic models and therefore have access to the
|
|
58
|
+
you will be inheriting Pydantic models and therefore have access to the functionality Pydantic provides
|
|
59
59
|
such as [validators](https://pydantic-docs.helpmanual.io/usage/validators/) and [Fields](https://pydantic-docs.helpmanual.io/usage/model_config/#alias-precedence).
|
|
60
60
|
Pydantic will also automatically deserialized the data into the correct data type based on the type
|
|
61
61
|
hint provided.
|
{meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_client.py
RENAMED
|
@@ -87,7 +87,7 @@ class BaseClient:
|
|
|
87
87
|
token.
|
|
88
88
|
api_key: The API key to use to generate the token.
|
|
89
89
|
expires_at: The timepoint at which the token should expire. If value is provided it
|
|
90
|
-
|
|
90
|
+
should be a UTC time in the future. Default = None.
|
|
91
91
|
|
|
92
92
|
Returns:
|
|
93
93
|
A JWT token
|
|
@@ -1170,7 +1170,7 @@ class AsyncClient(BaseClient):
|
|
|
1170
1170
|
timeout_in_ms: Amount of time in milliseconds to wait before raising a
|
|
1171
1171
|
MeilisearchTimeoutError. `None` can also be passed to wait indefinitely. Be aware that
|
|
1172
1172
|
if the `None` option is used the wait time could be very long. Defaults to 5000.
|
|
1173
|
-
interval_in_ms: Time interval in
|
|
1173
|
+
interval_in_ms: Time interval in milliseconds to sleep between requests. Defaults to 50.
|
|
1174
1174
|
raise_for_status: When set to `True` a MeilisearchTaskFailedError will be raised if a task
|
|
1175
1175
|
has a failed status. Defaults to False.
|
|
1176
1176
|
|
|
@@ -2271,7 +2271,7 @@ class Client(BaseClient):
|
|
|
2271
2271
|
timeout_in_ms: Amount of time in milliseconds to wait before raising a
|
|
2272
2272
|
MeilisearchTimeoutError. `None` can also be passed to wait indefinitely. Be aware that
|
|
2273
2273
|
if the `None` option is used the wait time could be very long. Defaults to 5000.
|
|
2274
|
-
interval_in_ms: Time interval in
|
|
2274
|
+
interval_in_ms: Time interval in milliseconds to sleep between requests. Defaults to 50.
|
|
2275
2275
|
raise_for_status: When set to `True` a MeilisearchTaskFailedError will be raised if a task
|
|
2276
2276
|
has a failed status. Defaults to False.
|
|
2277
2277
|
|
{meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/_task.py
RENAMED
|
@@ -73,7 +73,7 @@ async def async_cancel_tasks(
|
|
|
73
73
|
)
|
|
74
74
|
|
|
75
75
|
if not parameters:
|
|
76
|
-
# Cancel all tasks if no
|
|
76
|
+
# Cancel all tasks if no parameters provided
|
|
77
77
|
parameters["statuses"] = "enqueued,processing"
|
|
78
78
|
|
|
79
79
|
url = f"tasks/cancel?{urlencode(parameters)}"
|
|
@@ -107,7 +107,7 @@ async def async_delete_tasks(
|
|
|
107
107
|
)
|
|
108
108
|
|
|
109
109
|
if not parameters:
|
|
110
|
-
# delete all tasks if no
|
|
110
|
+
# delete all tasks if no parameters provided
|
|
111
111
|
parameters["statuses"] = "canceled,enqueued,failed,processing,succeeded"
|
|
112
112
|
|
|
113
113
|
url = f"tasks?{urlencode(parameters)}"
|
|
@@ -214,7 +214,7 @@ def cancel_tasks(
|
|
|
214
214
|
)
|
|
215
215
|
|
|
216
216
|
if not parameters:
|
|
217
|
-
# Cancel all tasks if no
|
|
217
|
+
# Cancel all tasks if no parameters provided
|
|
218
218
|
parameters["statuses"] = "enqueued,processing"
|
|
219
219
|
|
|
220
220
|
url = f"tasks/cancel?{urlencode(parameters)}"
|
|
@@ -248,7 +248,7 @@ def delete_tasks(
|
|
|
248
248
|
)
|
|
249
249
|
|
|
250
250
|
if not parameters:
|
|
251
|
-
# delete all tasks if no
|
|
251
|
+
# delete all tasks if no parameters provided
|
|
252
252
|
parameters["statuses"] = "canceled,enqueued,failed,processing,succeeded"
|
|
253
253
|
|
|
254
254
|
url = f"tasks?{urlencode(parameters)}"
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
VERSION = "5.3.0"
|
{meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/decorators.py
RENAMED
|
@@ -10,7 +10,7 @@ from meilisearch_python_sdk._utils import use_task_groups
|
|
|
10
10
|
|
|
11
11
|
|
|
12
12
|
class ConnectionInfo(NamedTuple):
|
|
13
|
-
"""
|
|
13
|
+
"""Information on how to connect to Meilisearch.
|
|
14
14
|
|
|
15
15
|
url: URL for the Meilisearch server.
|
|
16
16
|
api_key: The API key for the server.
|
|
@@ -29,13 +29,13 @@ def async_add_documents(
|
|
|
29
29
|
wait_for_task: bool = False,
|
|
30
30
|
verify: bool = True,
|
|
31
31
|
) -> Callable:
|
|
32
|
-
"""Decorator that takes the returned documents from a function and
|
|
32
|
+
"""Decorator that takes the returned documents from a function and asynchronously adds them to Meilisearch.
|
|
33
33
|
|
|
34
34
|
It is required that either an async_client or url is provided.
|
|
35
35
|
|
|
36
36
|
Args:
|
|
37
37
|
index_name: The name of the index to which the documents should be added.
|
|
38
|
-
connection_info: Either an AsyncClient instance ConnectionInfo with
|
|
38
|
+
connection_info: Either an AsyncClient instance ConnectionInfo with information on how to
|
|
39
39
|
connect to Meilisearch.
|
|
40
40
|
batch_size: If provided the documents will be sent in batches of the specified size.
|
|
41
41
|
Otherwise all documents are sent at once. Default = None.
|
|
@@ -46,7 +46,7 @@ def async_add_documents(
|
|
|
46
46
|
verify: If set to `False` the decorator will not verify the SSL certificate of the server.
|
|
47
47
|
|
|
48
48
|
Returns:
|
|
49
|
-
The list of documents
|
|
49
|
+
The list of documents provided by the decorated function.
|
|
50
50
|
|
|
51
51
|
Raises:
|
|
52
52
|
MeilisearchCommunicationError: If there was an error communicating with the server.
|
|
@@ -117,7 +117,7 @@ def add_documents(
|
|
|
117
117
|
|
|
118
118
|
Args:
|
|
119
119
|
index_name: The name of the index to which the documents should be added.
|
|
120
|
-
connection_info: Either an Client instance ConnectionInfo with
|
|
120
|
+
connection_info: Either an Client instance ConnectionInfo with information on how to
|
|
121
121
|
connect to Meilisearch.
|
|
122
122
|
batch_size: If provided the documents will be sent in batches of the specified size.
|
|
123
123
|
Otherwise all documents are sent at once. Default = None.
|
|
@@ -128,7 +128,7 @@ def add_documents(
|
|
|
128
128
|
verify: If set to `False` the decorator will not verify the SSL certificate of the server.
|
|
129
129
|
|
|
130
130
|
Returns:
|
|
131
|
-
The list of documents
|
|
131
|
+
The list of documents provided by the decorated function.
|
|
132
132
|
|
|
133
133
|
Raises:
|
|
134
134
|
MeilisearchCommunicationError: If there was an error communicating with the server.
|
{meilisearch_python_sdk-5.2.0 → meilisearch_python_sdk-5.3.0}/meilisearch_python_sdk/index.py
RENAMED
|
@@ -562,7 +562,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
562
562
|
return self
|
|
563
563
|
|
|
564
564
|
async def fetch_info(self) -> Self:
|
|
565
|
-
"""Gets the
|
|
565
|
+
"""Gets the information about the index.
|
|
566
566
|
|
|
567
567
|
Returns:
|
|
568
568
|
An instance of the AsyncIndex containing the retrieved information.
|
|
@@ -757,7 +757,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
757
757
|
attributes_to_retrieve: Attributes to display in the returned documents.
|
|
758
758
|
Defaults to ["*"].
|
|
759
759
|
attributes_to_crop: Attributes whose values have to be cropped. Defaults to None.
|
|
760
|
-
crop_length: The
|
|
760
|
+
crop_length: The maximum number of words to display. Defaults to 200.
|
|
761
761
|
attributes_to_highlight: Attributes whose values will contain highlighted matching terms.
|
|
762
762
|
Defaults to None.
|
|
763
763
|
sort: Attributes by which to sort the results. Defaults to None.
|
|
@@ -765,7 +765,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
765
765
|
matches should be returned or not. Defaults to False.
|
|
766
766
|
highlight_pre_tag: The opening tag for highlighting text. Defaults to <em>.
|
|
767
767
|
highlight_post_tag: The closing tag for highlighting text. Defaults to </em>
|
|
768
|
-
crop_marker: Marker to display when the number of words
|
|
768
|
+
crop_marker: Marker to display when the number of words exceeds the `crop_length`.
|
|
769
769
|
Defaults to ...
|
|
770
770
|
matching_strategy: Specifies the matching strategy Meilisearch should use. Defaults to
|
|
771
771
|
`last`.
|
|
@@ -1036,7 +1036,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1036
1036
|
attributes_to_retrieve: Attributes to display in the returned documents.
|
|
1037
1037
|
Defaults to ["*"].
|
|
1038
1038
|
attributes_to_crop: Attributes whose values have to be cropped. Defaults to None.
|
|
1039
|
-
crop_length: The
|
|
1039
|
+
crop_length: The maximum number of words to display. Defaults to 200.
|
|
1040
1040
|
attributes_to_highlight: Attributes whose values will contain highlighted matching terms.
|
|
1041
1041
|
Defaults to None.
|
|
1042
1042
|
sort: Attributes by which to sort the results. Defaults to None.
|
|
@@ -1044,7 +1044,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1044
1044
|
matches should be returned or not. Defaults to False.
|
|
1045
1045
|
highlight_pre_tag: The opening tag for highlighting text. Defaults to <em>.
|
|
1046
1046
|
highlight_post_tag: The closing tag for highlighting text. Defaults to </em>
|
|
1047
|
-
crop_marker: Marker to display when the number of words
|
|
1047
|
+
crop_marker: Marker to display when the number of words exceeds the `crop_length`.
|
|
1048
1048
|
Defaults to ...
|
|
1049
1049
|
matching_strategy: Specifies the matching strategy Meilisearch should use. Defaults to
|
|
1050
1050
|
`last`.
|
|
@@ -1372,6 +1372,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1372
1372
|
async def get_documents(
|
|
1373
1373
|
self,
|
|
1374
1374
|
*,
|
|
1375
|
+
ids: list[str] | None = None,
|
|
1375
1376
|
offset: int = 0,
|
|
1376
1377
|
limit: int = 20,
|
|
1377
1378
|
fields: list[str] | None = None,
|
|
@@ -1382,6 +1383,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1382
1383
|
"""Get a batch documents from the index.
|
|
1383
1384
|
|
|
1384
1385
|
Args:
|
|
1386
|
+
ids: Array of document primary keys to retrieve. Defaults to None (Gets all documents).
|
|
1385
1387
|
offset: Number of documents to skip. Defaults to 0.
|
|
1386
1388
|
limit: Maximum number of documents returnedd. Defaults to 20.
|
|
1387
1389
|
fields: Document attributes to show. If this value is None then all
|
|
@@ -1418,7 +1420,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1418
1420
|
if retrieve_vectors:
|
|
1419
1421
|
parameters["retrieveVectors"] = "true"
|
|
1420
1422
|
|
|
1421
|
-
if not filter:
|
|
1423
|
+
if not filter and not ids:
|
|
1422
1424
|
if fields:
|
|
1423
1425
|
parameters["fields"] = ",".join(fields)
|
|
1424
1426
|
|
|
@@ -1432,6 +1434,9 @@ class AsyncIndex(_BaseIndex):
|
|
|
1432
1434
|
|
|
1433
1435
|
parameters["filter"] = filter
|
|
1434
1436
|
|
|
1437
|
+
if ids:
|
|
1438
|
+
parameters["ids"] = ids
|
|
1439
|
+
|
|
1435
1440
|
response = await self._http_requests.post(f"{self._documents_url}/fetch", body=parameters)
|
|
1436
1441
|
|
|
1437
1442
|
return DocumentsInfo(**response.json())
|
|
@@ -1663,8 +1668,8 @@ class AsyncIndex(_BaseIndex):
|
|
|
1663
1668
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
1664
1669
|
Defaults to None.
|
|
1665
1670
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
1666
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
1667
|
-
the field names, and ever for should have a title.
|
|
1671
|
+
ndjson. For csv files the first row of the document should be a header row
|
|
1672
|
+
containing the field names, and ever for should have a title.
|
|
1668
1673
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
1669
1674
|
can only be used if the file is a csv file. Defaults to comma.
|
|
1670
1675
|
combine_documents: If set to True this will combine the documents from all the files
|
|
@@ -1827,7 +1832,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
1827
1832
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
1828
1833
|
Defaults to None.
|
|
1829
1834
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
1830
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
1835
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
1831
1836
|
the field names, and ever for should have a title.
|
|
1832
1837
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
1833
1838
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -2350,7 +2355,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
2350
2355
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
2351
2356
|
Defaults to None.
|
|
2352
2357
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
2353
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
2358
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
2354
2359
|
the field names, and ever for should have a title.
|
|
2355
2360
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
2356
2361
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -2462,7 +2467,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
2462
2467
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
2463
2468
|
Defaults to None.
|
|
2464
2469
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
2465
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
2470
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
2466
2471
|
the field names, and ever for should have a title.
|
|
2467
2472
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
2468
2473
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -2907,7 +2912,7 @@ class AsyncIndex(_BaseIndex):
|
|
|
2907
2912
|
MeilisearchApiError: If the Meilisearch API returned an error.
|
|
2908
2913
|
|
|
2909
2914
|
Examples
|
|
2910
|
-
>>> from
|
|
2915
|
+
>>> from meilisearch_python_sdk import AsyncClient
|
|
2911
2916
|
>>> async with AsyncClient("http://localhost.com", "masterKey") as client:
|
|
2912
2917
|
>>> index = client.index("movies")
|
|
2913
2918
|
>>> await index.delete_documents_by_filter("genre=horor"))
|
|
@@ -5028,7 +5033,7 @@ class Index(_BaseIndex):
|
|
|
5028
5033
|
return self
|
|
5029
5034
|
|
|
5030
5035
|
def fetch_info(self) -> Self:
|
|
5031
|
-
"""Gets the
|
|
5036
|
+
"""Gets the information about the index.
|
|
5032
5037
|
|
|
5033
5038
|
Returns:
|
|
5034
5039
|
An instance of the AsyncIndex containing the retrieved information.
|
|
@@ -5216,7 +5221,7 @@ class Index(_BaseIndex):
|
|
|
5216
5221
|
attributes_to_retrieve: Attributes to display in the returned documents.
|
|
5217
5222
|
Defaults to ["*"].
|
|
5218
5223
|
attributes_to_crop: Attributes whose values have to be cropped. Defaults to None.
|
|
5219
|
-
crop_length: The
|
|
5224
|
+
crop_length: The maximum number of words to display. Defaults to 200.
|
|
5220
5225
|
attributes_to_highlight: Attributes whose values will contain highlighted matching terms.
|
|
5221
5226
|
Defaults to None.
|
|
5222
5227
|
sort: Attributes by which to sort the results. Defaults to None.
|
|
@@ -5224,7 +5229,7 @@ class Index(_BaseIndex):
|
|
|
5224
5229
|
matches should be returned or not. Defaults to False.
|
|
5225
5230
|
highlight_pre_tag: The opening tag for highlighting text. Defaults to <em>.
|
|
5226
5231
|
highlight_post_tag: The closing tag for highlighting text. Defaults to </em>
|
|
5227
|
-
crop_marker: Marker to display when the number of words
|
|
5232
|
+
crop_marker: Marker to display when the number of words exceeds the `crop_length`.
|
|
5228
5233
|
Defaults to ...
|
|
5229
5234
|
matching_strategy: Specifies the matching strategy Meilisearch should use. Defaults to
|
|
5230
5235
|
`last`.
|
|
@@ -5401,7 +5406,7 @@ class Index(_BaseIndex):
|
|
|
5401
5406
|
attributes_to_retrieve: Attributes to display in the returned documents.
|
|
5402
5407
|
Defaults to ["*"].
|
|
5403
5408
|
attributes_to_crop: Attributes whose values have to be cropped. Defaults to None.
|
|
5404
|
-
crop_length: The
|
|
5409
|
+
crop_length: The maximum number of words to display. Defaults to 200.
|
|
5405
5410
|
attributes_to_highlight: Attributes whose values will contain highlighted matching terms.
|
|
5406
5411
|
Defaults to None.
|
|
5407
5412
|
sort: Attributes by which to sort the results. Defaults to None.
|
|
@@ -5409,7 +5414,7 @@ class Index(_BaseIndex):
|
|
|
5409
5414
|
matches should be returned or not. Defaults to False.
|
|
5410
5415
|
highlight_pre_tag: The opening tag for highlighting text. Defaults to <em>.
|
|
5411
5416
|
highlight_post_tag: The closing tag for highlighting text. Defaults to </em>
|
|
5412
|
-
crop_marker: Marker to display when the number of words
|
|
5417
|
+
crop_marker: Marker to display when the number of words exceeds the `crop_length`.
|
|
5413
5418
|
Defaults to ...
|
|
5414
5419
|
matching_strategy: Specifies the matching strategy Meilisearch should use. Defaults to
|
|
5415
5420
|
`last`.
|
|
@@ -5640,6 +5645,7 @@ class Index(_BaseIndex):
|
|
|
5640
5645
|
def get_documents(
|
|
5641
5646
|
self,
|
|
5642
5647
|
*,
|
|
5648
|
+
ids: list[str] | None = None,
|
|
5643
5649
|
offset: int = 0,
|
|
5644
5650
|
limit: int = 20,
|
|
5645
5651
|
fields: list[str] | None = None,
|
|
@@ -5650,6 +5656,7 @@ class Index(_BaseIndex):
|
|
|
5650
5656
|
"""Get a batch documents from the index.
|
|
5651
5657
|
|
|
5652
5658
|
Args:
|
|
5659
|
+
ids: Array of document primary keys to retrieve. Defaults to None (Gets all documents).
|
|
5653
5660
|
offset: Number of documents to skip. Defaults to 0.
|
|
5654
5661
|
limit: Maximum number of documents returnedd. Defaults to 20.
|
|
5655
5662
|
fields: Document attributes to show. If this value is None then all
|
|
@@ -5686,7 +5693,7 @@ class Index(_BaseIndex):
|
|
|
5686
5693
|
if retrieve_vectors:
|
|
5687
5694
|
parameters["retrieveVectors"] = "true"
|
|
5688
5695
|
|
|
5689
|
-
if not filter:
|
|
5696
|
+
if not filter and not ids:
|
|
5690
5697
|
if fields:
|
|
5691
5698
|
parameters["fields"] = ",".join(fields)
|
|
5692
5699
|
|
|
@@ -5700,6 +5707,9 @@ class Index(_BaseIndex):
|
|
|
5700
5707
|
|
|
5701
5708
|
parameters["filter"] = filter
|
|
5702
5709
|
|
|
5710
|
+
if ids:
|
|
5711
|
+
parameters["ids"] = ids
|
|
5712
|
+
|
|
5703
5713
|
response = self._http_requests.post(f"{self._documents_url}/fetch", body=parameters)
|
|
5704
5714
|
|
|
5705
5715
|
return DocumentsInfo(**response.json())
|
|
@@ -5817,7 +5827,7 @@ class Index(_BaseIndex):
|
|
|
5817
5827
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
5818
5828
|
Defaults to None.
|
|
5819
5829
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
5820
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
5830
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
5821
5831
|
the field names, and ever for should have a title.
|
|
5822
5832
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
5823
5833
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -5893,7 +5903,7 @@ class Index(_BaseIndex):
|
|
|
5893
5903
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
5894
5904
|
Defaults to None.
|
|
5895
5905
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
5896
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
5906
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
5897
5907
|
the field names, and ever for should have a title.
|
|
5898
5908
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
5899
5909
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -6282,7 +6292,7 @@ class Index(_BaseIndex):
|
|
|
6282
6292
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
6283
6293
|
Defaults to None.
|
|
6284
6294
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
6285
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
6295
|
+
ndjson. For csv files the first row of the document should be a header row containing
|
|
6286
6296
|
the field names, and ever for should have a title.
|
|
6287
6297
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
6288
6298
|
can only be used if the file is a csv file. Defaults to comma.
|
|
@@ -6357,8 +6367,8 @@ class Index(_BaseIndex):
|
|
|
6357
6367
|
primary_key: The primary key of the documents. This will be ignored if already set.
|
|
6358
6368
|
Defaults to None.
|
|
6359
6369
|
document_type: The type of document being added. Accepted types are json, csv, and
|
|
6360
|
-
ndjson. For csv files the first row of the document should be a header row
|
|
6361
|
-
the field names, and ever for should have a title.
|
|
6370
|
+
ndjson. For csv files the first row of the document should be a header row
|
|
6371
|
+
containing the field names, and ever for should have a title.
|
|
6362
6372
|
csv_delimiter: A single ASCII character to specify the delimiter for csv files. This
|
|
6363
6373
|
can only be used if the file is a csv file. Defaults to comma.
|
|
6364
6374
|
combine_documents: If set to True this will combine the documents from all the files
|
|
@@ -748,6 +748,18 @@ async def test_get_documents_filter(async_index_with_documents):
|
|
|
748
748
|
assert next(iter(genres)) == "action"
|
|
749
749
|
|
|
750
750
|
|
|
751
|
+
async def test_get_documents_ids(async_index_with_documents):
|
|
752
|
+
index = await async_index_with_documents()
|
|
753
|
+
documents = await index.get_documents()
|
|
754
|
+
assert len(documents.results) > 2
|
|
755
|
+
ids = [documents.results[0]["id"], documents.results[1]["id"]]
|
|
756
|
+
response = await index.get_documents(ids=ids)
|
|
757
|
+
assert len(response.results) == 2
|
|
758
|
+
retrieved_ids = [result["id"] for result in response.results]
|
|
759
|
+
assert ids[0] in retrieved_ids
|
|
760
|
+
assert ids[1] in retrieved_ids
|
|
761
|
+
|
|
762
|
+
|
|
751
763
|
async def test_get_documents_filter_with_fields(async_index_with_documents):
|
|
752
764
|
index = await async_index_with_documents()
|
|
753
765
|
response = await index.update_filterable_attributes(["genre"])
|
|
@@ -57,7 +57,7 @@ async def test_custom_search(async_index_with_documents):
|
|
|
57
57
|
assert "dragon" in response.hits[0]["_formatted"]["title"].lower()
|
|
58
58
|
|
|
59
59
|
|
|
60
|
-
async def
|
|
60
|
+
async def test_custom_search_highlight_tags_and_crop_marker(async_index_with_documents):
|
|
61
61
|
index = await async_index_with_documents()
|
|
62
62
|
response = await index.search(
|
|
63
63
|
"Dragon",
|
|
@@ -288,7 +288,7 @@ async def test_search_sort(sort, titles, async_index_with_documents):
|
|
|
288
288
|
await async_wait_for_task(index.http_client, response.task_uid)
|
|
289
289
|
stats = await index.get_stats() # get this to get the total document count
|
|
290
290
|
|
|
291
|
-
# Using a placeholder search because ranking rules affect sort
|
|
291
|
+
# Using a placeholder search because ranking rules affect sort otherwise meaning the results
|
|
292
292
|
# will almost never be in alphabetical order.
|
|
293
293
|
response = await index.search(sort=sort, limit=stats.number_of_documents)
|
|
294
294
|
assert response.hits[0]["title"] == titles[0]
|
|
@@ -482,14 +482,14 @@ async def test_attributes_to_search_on_search_no_match(async_index_with_document
|
|
|
482
482
|
assert response.hits == []
|
|
483
483
|
|
|
484
484
|
|
|
485
|
-
async def
|
|
485
|
+
async def test_show_ranking_score_search(async_index_with_documents):
|
|
486
486
|
index = await async_index_with_documents()
|
|
487
487
|
response = await index.search("How to Train Your Dragon", show_ranking_score=True)
|
|
488
488
|
assert response.hits[0]["id"] == "166428"
|
|
489
489
|
assert "_rankingScore" in response.hits[0]
|
|
490
490
|
|
|
491
491
|
|
|
492
|
-
async def
|
|
492
|
+
async def test_show_ranking_details_search(async_index_with_documents):
|
|
493
493
|
index = await async_index_with_documents()
|
|
494
494
|
response = await index.search("How to Train Your Dragon", show_ranking_score_details=True)
|
|
495
495
|
assert response.hits[0]["id"] == "166428"
|
|
@@ -668,6 +668,18 @@ def test_get_documents_filter(index_with_documents):
|
|
|
668
668
|
assert next(iter(genres)) == "action"
|
|
669
669
|
|
|
670
670
|
|
|
671
|
+
def test_get_documents_ids(index_with_documents):
|
|
672
|
+
index = index_with_documents()
|
|
673
|
+
documents = index.get_documents()
|
|
674
|
+
assert len(documents.results) > 2
|
|
675
|
+
ids = [documents.results[0]["id"], documents.results[1]["id"]]
|
|
676
|
+
response = index.get_documents(ids=ids)
|
|
677
|
+
assert len(response.results) == 2
|
|
678
|
+
retrieved_ids = [result["id"] for result in response.results]
|
|
679
|
+
assert ids[0] in retrieved_ids
|
|
680
|
+
assert ids[1] in retrieved_ids
|
|
681
|
+
|
|
682
|
+
|
|
671
683
|
def test_get_documents_with_vectors(index_with_documents):
|
|
672
684
|
index = index_with_documents()
|
|
673
685
|
response = index.update_filterable_attributes(["genre"])
|
|
@@ -57,7 +57,7 @@ def test_custom_search(index_with_documents):
|
|
|
57
57
|
assert "dragon" in response.hits[0]["_formatted"]["title"].lower()
|
|
58
58
|
|
|
59
59
|
|
|
60
|
-
def
|
|
60
|
+
def test_custom_search_highlight_tags_and_crop_marker(index_with_documents):
|
|
61
61
|
index = index_with_documents()
|
|
62
62
|
response = index.search(
|
|
63
63
|
"Dragon",
|
|
@@ -288,7 +288,7 @@ def test_search_sort(sort, titles, index_with_documents):
|
|
|
288
288
|
wait_for_task(index.http_client, response.task_uid)
|
|
289
289
|
stats = index.get_stats() # get this to get the total document count
|
|
290
290
|
|
|
291
|
-
# Using a placeholder search because ranking rules affect sort
|
|
291
|
+
# Using a placeholder search because ranking rules affect sort otherwise meaning the results
|
|
292
292
|
# will almost never be in alphabetical order.
|
|
293
293
|
response = index.search(sort=sort, limit=stats.number_of_documents)
|
|
294
294
|
assert response.hits[0]["title"] == titles[0]
|
|
@@ -459,14 +459,14 @@ def test_attributes_to_search_on_search_no_match(index_with_documents):
|
|
|
459
459
|
assert response.hits == []
|
|
460
460
|
|
|
461
461
|
|
|
462
|
-
def
|
|
462
|
+
def test_show_ranking_score_search(index_with_documents):
|
|
463
463
|
index = index_with_documents()
|
|
464
464
|
response = index.search("How to Train Your Dragon", show_ranking_score=True)
|
|
465
465
|
assert response.hits[0]["id"] == "166428"
|
|
466
466
|
assert "_rankingScore" in response.hits[0]
|
|
467
467
|
|
|
468
468
|
|
|
469
|
-
def
|
|
469
|
+
def test_show_ranking_details_search(index_with_documents):
|
|
470
470
|
index = index_with_documents()
|
|
471
471
|
response = index.search("How to Train Your Dragon", show_ranking_score_details=True)
|
|
472
472
|
assert response.hits[0]["id"] == "166428"
|