loopgain 0.5.0__tar.gz → 0.5.2__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {loopgain-0.5.0 → loopgain-0.5.2}/PKG-INFO +36 -10
- {loopgain-0.5.0 → loopgain-0.5.2}/README.md +35 -9
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/_version.py +1 -1
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/telemetry.py +1 -1
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/PKG-INFO +36 -10
- {loopgain-0.5.0 → loopgain-0.5.2}/LICENSE +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/__init__.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/__main__.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/classifier.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/cli.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/core.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/funnel.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/__init__.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/autogen.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/claude_agent_sdk.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/crewai.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/langchain.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/langgraph.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain/integrations/openai_agents.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/SOURCES.txt +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/dependency_links.txt +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/entry_points.txt +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/requires.txt +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/loopgain.egg-info/top_level.txt +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/pyproject.toml +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/setup.cfg +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_classifier_mock_validation.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_classifier_synthetic.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_core.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_funnel.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_integrations.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_stress.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_telemetry.py +0 -0
- {loopgain-0.5.0 → loopgain-0.5.2}/tests/test_termination_safety.py +0 -0
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: loopgain
|
|
3
|
-
Version: 0.5.
|
|
3
|
+
Version: 0.5.2
|
|
4
4
|
Summary: An open-source cost controller for AI agent loops. Stops a loop when it has actually converged and rolls back before it degrades — replacing the max_iterations guess with a real-time loop-gain (Aβ) monitor with five named threshold bands and best-so-far rollback.
|
|
5
5
|
Author-email: Dave Fitzsimmons <hello@loopgain.ai>
|
|
6
6
|
License: Apache-2.0
|
|
@@ -53,19 +53,24 @@ Dynamic: license-file
|
|
|
53
53
|
|
|
54
54
|
AI agent loops waste time and money when they don't know when to stop. LoopGain measures the loop in real time and stops it the moment it has actually converged — and rolls back before it degrades — instead of running to a fixed `max_iterations` cap.
|
|
55
55
|
|
|
56
|
-
> **
|
|
56
|
+
> **Benchmark — 2,000 paired trials across 10 workload cells** ([run it yourself](https://github.com/loopgain-ai/loopgain-bench)):
|
|
57
|
+
>
|
|
58
|
+
> - **92.8% less API spend** than `max_iter=20` — $27.05 → $1.94 in total benchmark spend
|
|
59
|
+
> - **~15× faster** — median wall-clock per trial 30.9s → 2.1s
|
|
60
|
+
> - **Quality preserved, not traded for speed** — judge win-rate 0.50–0.63 on natural-distribution workloads (W1–W4, CI excluding null on most cells), 0.92–0.95 on engineered-failure workloads (W5); 0.678 weighted preference across 1,800 judge comparisons
|
|
61
|
+
> - **Zero of six kill criteria fired** (all six pre-registered with thresholds before the run)
|
|
62
|
+
|
|
63
|
+
**Honest limits, up front:** LoopGain detects *convergence, not correctness* — it knows when more iterations won't help, not whether the answer is right, and it's only as good as the verifier behind your error signal. [The full list of what it can't do →](#what-loopgain-does-and-doesnt-guarantee)
|
|
57
64
|
|
|
58
65
|
[](https://pypi.org/project/loopgain/)
|
|
59
66
|
[](https://pypi.org/project/loopgain/)
|
|
60
67
|
[](LICENSE)
|
|
61
|
-
[](tests/)
|
|
62
69
|
|
|
63
70
|
**Home:** [loopgain.ai](https://loopgain.ai)
|
|
64
71
|
|
|
65
72
|
Works for **any iterative AI workflow with a measurable error signal** — verify-revise loops, refinement passes, tool-use retry chains, RAG with self-correction, code-gen with linter feedback, multi-step reasoning loops. **Pre-built adapters for [LangGraph](#langgraph), [CrewAI](#crewai), [AutoGen](#autogen-v04), [LangChain](#langchain), [OpenAI Agents SDK](#openai-agents-sdk), and [Claude Agent SDK](#claude-agent-sdk)**; drop-in via the raw API for any custom stack. Pure Python, no runtime dependencies.
|
|
66
73
|
|
|
67
|
-
**Keywords:** AI agent loops · agentic AI · infinite loop detection · divergence detection · early stopping · convergence · agent orchestration · LLM stability · generator-verifier-reviser · feedback-loop control.
|
|
68
|
-
|
|
69
74
|
---
|
|
70
75
|
|
|
71
76
|
## Why
|
|
@@ -176,13 +181,34 @@ This transforms divergence detection from "abort with garbage" into "abort with
|
|
|
176
181
|
|
|
177
182
|
---
|
|
178
183
|
|
|
184
|
+
## See it across a fleet (optional dashboard)
|
|
185
|
+
|
|
186
|
+
The library is the whole product locally — telemetry is opt-in and self-hostable. If you want a fleet view of every loop's stability, cost, and rollbacks across a team, there's a hosted dashboard fed by the [telemetry receiver](https://github.com/loopgain-ai/telemetry-receiver):
|
|
187
|
+
|
|
188
|
+
[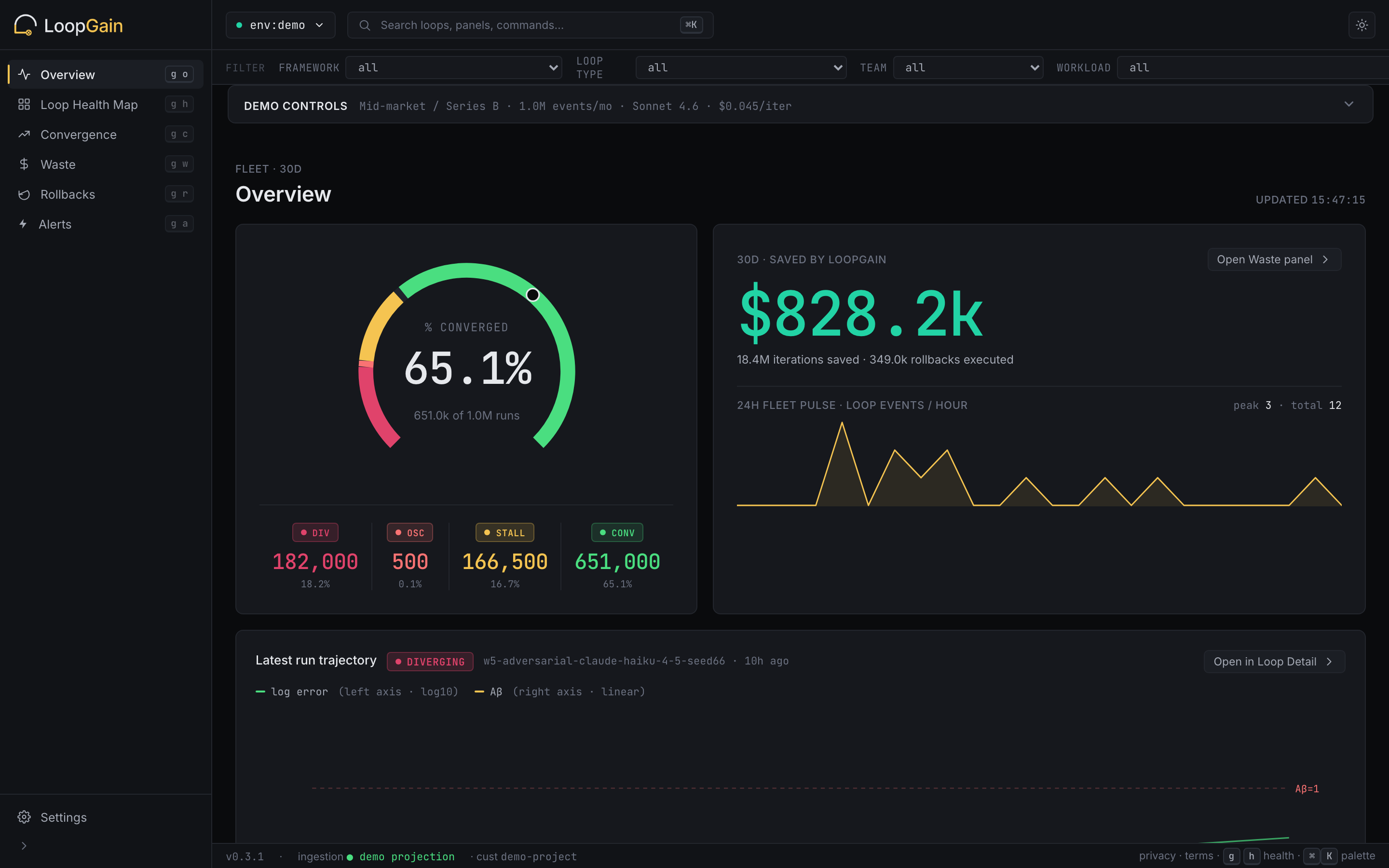](https://dashboard.loopgain.ai/demo)
|
|
189
|
+
|
|
190
|
+
**[Open the live demo →](https://dashboard.loopgain.ai/demo)** — no signup, real benchmark data.
|
|
191
|
+
|
|
192
|
+
The receiver and dashboard are both open-source — self-host to keep telemetry entirely under your control.
|
|
193
|
+
|
|
194
|
+
### Repositories
|
|
195
|
+
|
|
196
|
+
| Repo | What it is |
|
|
197
|
+
| --- | --- |
|
|
198
|
+
| [**loopgain**](https://github.com/loopgain-ai/loopgain) | This library — the Apache-2.0 control loop (you are here) |
|
|
199
|
+
| [**telemetry-receiver**](https://github.com/loopgain-ai/telemetry-receiver) | Cloudflare Worker that ingests anonymized loop telemetry |
|
|
200
|
+
| [**dashboard**](https://github.com/loopgain-ai/dashboard) | The fleet dashboard — self-hostable |
|
|
201
|
+
| [**loopgain-bench**](https://github.com/loopgain-ai/loopgain-bench) | The reproducible 2,000-trial benchmark behind the numbers above |
|
|
202
|
+
|
|
203
|
+
---
|
|
204
|
+
|
|
179
205
|
## What LoopGain does and doesn't guarantee
|
|
180
206
|
|
|
181
|
-
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8%
|
|
207
|
+
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8% cut in total API spend** vs `max_iterations=20`, with output quality preserved. Two honest limits:
|
|
182
208
|
|
|
183
209
|
- **Savings depend on your workload.** Loops that usually succeed fast save the most (~96%); adversarial, failure-prone loops save less (~78–84%). The headline is a blend — run the benchmark on your own loops before quoting a number.
|
|
184
210
|
- **LoopGain detects convergence, not correctness.** It stops when your error signal stops improving — which means more iterations won't help, *not* that the loop succeeded. On the benchmark this preserved quality (it rarely stopped early on a worse output; false-stop rate ≤4.5%), but a loop can stall with the error still above zero — a plateau at, say, 2 failing tests. So check `result.best_error` (or your own pass/fail) before you trust the output: if it plateaued short of your target, that's a quality gap LoopGain can't see, and a false stop that forces a rerun is the one way it eats into the savings. LoopGain decides *when to stop*; you decide *whether the answer is good enough*.
|
|
185
|
-
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against.
|
|
211
|
+
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. We measured this on the benchmark's code-gen workload: **4.5% of converged runs (16/355) passed every check the loop ran but failed the full held-out test suite** — and that's a floor, not a ceiling, because the in-loop verifier there was strong; a weaker verifier exposes more. (Distinct from the ≤4.5% false-stop rate above — the numbers coincide, the failure modes don't.) Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against. **[How to design a strong verifier](https://loopgain.ai/blog/posts/how-to-design-a-strong-verifier/)** is a field guide to exactly this.
|
|
186
212
|
|
|
187
213
|
---
|
|
188
214
|
|
|
@@ -246,9 +272,9 @@ python3 -c "import keyring; keyring.set_password('loopgain', 'telemetry', input(
|
|
|
246
272
|
# Then in code: keyring.get_password('loopgain', 'telemetry')
|
|
247
273
|
```
|
|
248
274
|
|
|
249
|
-
What is sent: state transitions, Aβ summary (min/max/median),
|
|
275
|
+
What is sent: state transitions, Aβ summary (min/max/median), rollback flag, iterations used, savings, library version, optional opaque `workload_id`, threshold config, hour-bucketed timestamp — and, unless you pass `include_per_iteration=False`, a length-capped per-iteration trajectory (smoothed Aβ values and numeric error magnitudes; this is what drives the dashboard's convergence-profile scrubbing).
|
|
250
276
|
|
|
251
|
-
**What is NEVER sent: prompts, completions, error contents, output buffer,
|
|
277
|
+
**What is NEVER sent: prompts, completions, error contents, the output buffer, or any customer identity beyond the bearer token.** Numeric error *magnitudes* are sent (they're the loop-gain signal); error *contents* never are. Privacy contract is enforced by the payload-shape unit tests in `tests/test_telemetry.py`.
|
|
252
278
|
|
|
253
279
|
The hosted endpoint at `telemetry.loopgain.ai` is one acceptable destination. The [receiver](https://github.com/loopgain-ai/telemetry-receiver) and [dashboard](https://github.com/loopgain-ai/dashboard) are both open-source — self-host to keep telemetry fully under your control.
|
|
254
280
|
|
|
@@ -507,7 +533,7 @@ This is alpha software. The API may break before 1.0 if production usage surface
|
|
|
507
533
|
|
|
508
534
|
LoopGain applies the **Barkhausen stability criterion** (Heinrich Barkhausen, 1921 — the foundational result on when feedback amplifiers oscillate) to AI agent feedback loops. The criterion was originally a way to predict whether an electronic oscillator would sustain oscillation; it turns out to map cleanly onto any feedback loop you can attach an error signal to.
|
|
509
535
|
|
|
510
|
-
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, decides what to do,
|
|
536
|
+
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, and decides what to do — stop, continue, or roll back to the best output seen so far.
|
|
511
537
|
|
|
512
538
|
Loop types this applies to in practice:
|
|
513
539
|
|
|
@@ -4,19 +4,24 @@
|
|
|
4
4
|
|
|
5
5
|
AI agent loops waste time and money when they don't know when to stop. LoopGain measures the loop in real time and stops it the moment it has actually converged — and rolls back before it degrades — instead of running to a fixed `max_iterations` cap.
|
|
6
6
|
|
|
7
|
-
> **
|
|
7
|
+
> **Benchmark — 2,000 paired trials across 10 workload cells** ([run it yourself](https://github.com/loopgain-ai/loopgain-bench)):
|
|
8
|
+
>
|
|
9
|
+
> - **92.8% less API spend** than `max_iter=20` — $27.05 → $1.94 in total benchmark spend
|
|
10
|
+
> - **~15× faster** — median wall-clock per trial 30.9s → 2.1s
|
|
11
|
+
> - **Quality preserved, not traded for speed** — judge win-rate 0.50–0.63 on natural-distribution workloads (W1–W4, CI excluding null on most cells), 0.92–0.95 on engineered-failure workloads (W5); 0.678 weighted preference across 1,800 judge comparisons
|
|
12
|
+
> - **Zero of six kill criteria fired** (all six pre-registered with thresholds before the run)
|
|
13
|
+
|
|
14
|
+
**Honest limits, up front:** LoopGain detects *convergence, not correctness* — it knows when more iterations won't help, not whether the answer is right, and it's only as good as the verifier behind your error signal. [The full list of what it can't do →](#what-loopgain-does-and-doesnt-guarantee)
|
|
8
15
|
|
|
9
16
|
[](https://pypi.org/project/loopgain/)
|
|
10
17
|
[](https://pypi.org/project/loopgain/)
|
|
11
18
|
[](LICENSE)
|
|
12
|
-
[](tests/)
|
|
13
20
|
|
|
14
21
|
**Home:** [loopgain.ai](https://loopgain.ai)
|
|
15
22
|
|
|
16
23
|
Works for **any iterative AI workflow with a measurable error signal** — verify-revise loops, refinement passes, tool-use retry chains, RAG with self-correction, code-gen with linter feedback, multi-step reasoning loops. **Pre-built adapters for [LangGraph](#langgraph), [CrewAI](#crewai), [AutoGen](#autogen-v04), [LangChain](#langchain), [OpenAI Agents SDK](#openai-agents-sdk), and [Claude Agent SDK](#claude-agent-sdk)**; drop-in via the raw API for any custom stack. Pure Python, no runtime dependencies.
|
|
17
24
|
|
|
18
|
-
**Keywords:** AI agent loops · agentic AI · infinite loop detection · divergence detection · early stopping · convergence · agent orchestration · LLM stability · generator-verifier-reviser · feedback-loop control.
|
|
19
|
-
|
|
20
25
|
---
|
|
21
26
|
|
|
22
27
|
## Why
|
|
@@ -127,13 +132,34 @@ This transforms divergence detection from "abort with garbage" into "abort with
|
|
|
127
132
|
|
|
128
133
|
---
|
|
129
134
|
|
|
135
|
+
## See it across a fleet (optional dashboard)
|
|
136
|
+
|
|
137
|
+
The library is the whole product locally — telemetry is opt-in and self-hostable. If you want a fleet view of every loop's stability, cost, and rollbacks across a team, there's a hosted dashboard fed by the [telemetry receiver](https://github.com/loopgain-ai/telemetry-receiver):
|
|
138
|
+
|
|
139
|
+
[](https://dashboard.loopgain.ai/demo)
|
|
140
|
+
|
|
141
|
+
**[Open the live demo →](https://dashboard.loopgain.ai/demo)** — no signup, real benchmark data.
|
|
142
|
+
|
|
143
|
+
The receiver and dashboard are both open-source — self-host to keep telemetry entirely under your control.
|
|
144
|
+
|
|
145
|
+
### Repositories
|
|
146
|
+
|
|
147
|
+
| Repo | What it is |
|
|
148
|
+
| --- | --- |
|
|
149
|
+
| [**loopgain**](https://github.com/loopgain-ai/loopgain) | This library — the Apache-2.0 control loop (you are here) |
|
|
150
|
+
| [**telemetry-receiver**](https://github.com/loopgain-ai/telemetry-receiver) | Cloudflare Worker that ingests anonymized loop telemetry |
|
|
151
|
+
| [**dashboard**](https://github.com/loopgain-ai/dashboard) | The fleet dashboard — self-hostable |
|
|
152
|
+
| [**loopgain-bench**](https://github.com/loopgain-ai/loopgain-bench) | The reproducible 2,000-trial benchmark behind the numbers above |
|
|
153
|
+
|
|
154
|
+
---
|
|
155
|
+
|
|
130
156
|
## What LoopGain does and doesn't guarantee
|
|
131
157
|
|
|
132
|
-
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8%
|
|
158
|
+
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8% cut in total API spend** vs `max_iterations=20`, with output quality preserved. Two honest limits:
|
|
133
159
|
|
|
134
160
|
- **Savings depend on your workload.** Loops that usually succeed fast save the most (~96%); adversarial, failure-prone loops save less (~78–84%). The headline is a blend — run the benchmark on your own loops before quoting a number.
|
|
135
161
|
- **LoopGain detects convergence, not correctness.** It stops when your error signal stops improving — which means more iterations won't help, *not* that the loop succeeded. On the benchmark this preserved quality (it rarely stopped early on a worse output; false-stop rate ≤4.5%), but a loop can stall with the error still above zero — a plateau at, say, 2 failing tests. So check `result.best_error` (or your own pass/fail) before you trust the output: if it plateaued short of your target, that's a quality gap LoopGain can't see, and a false stop that forces a rerun is the one way it eats into the savings. LoopGain decides *when to stop*; you decide *whether the answer is good enough*.
|
|
136
|
-
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against.
|
|
162
|
+
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. We measured this on the benchmark's code-gen workload: **4.5% of converged runs (16/355) passed every check the loop ran but failed the full held-out test suite** — and that's a floor, not a ceiling, because the in-loop verifier there was strong; a weaker verifier exposes more. (Distinct from the ≤4.5% false-stop rate above — the numbers coincide, the failure modes don't.) Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against. **[How to design a strong verifier](https://loopgain.ai/blog/posts/how-to-design-a-strong-verifier/)** is a field guide to exactly this.
|
|
137
163
|
|
|
138
164
|
---
|
|
139
165
|
|
|
@@ -197,9 +223,9 @@ python3 -c "import keyring; keyring.set_password('loopgain', 'telemetry', input(
|
|
|
197
223
|
# Then in code: keyring.get_password('loopgain', 'telemetry')
|
|
198
224
|
```
|
|
199
225
|
|
|
200
|
-
What is sent: state transitions, Aβ summary (min/max/median),
|
|
226
|
+
What is sent: state transitions, Aβ summary (min/max/median), rollback flag, iterations used, savings, library version, optional opaque `workload_id`, threshold config, hour-bucketed timestamp — and, unless you pass `include_per_iteration=False`, a length-capped per-iteration trajectory (smoothed Aβ values and numeric error magnitudes; this is what drives the dashboard's convergence-profile scrubbing).
|
|
201
227
|
|
|
202
|
-
**What is NEVER sent: prompts, completions, error contents, output buffer,
|
|
228
|
+
**What is NEVER sent: prompts, completions, error contents, the output buffer, or any customer identity beyond the bearer token.** Numeric error *magnitudes* are sent (they're the loop-gain signal); error *contents* never are. Privacy contract is enforced by the payload-shape unit tests in `tests/test_telemetry.py`.
|
|
203
229
|
|
|
204
230
|
The hosted endpoint at `telemetry.loopgain.ai` is one acceptable destination. The [receiver](https://github.com/loopgain-ai/telemetry-receiver) and [dashboard](https://github.com/loopgain-ai/dashboard) are both open-source — self-host to keep telemetry fully under your control.
|
|
205
231
|
|
|
@@ -458,7 +484,7 @@ This is alpha software. The API may break before 1.0 if production usage surface
|
|
|
458
484
|
|
|
459
485
|
LoopGain applies the **Barkhausen stability criterion** (Heinrich Barkhausen, 1921 — the foundational result on when feedback amplifiers oscillate) to AI agent feedback loops. The criterion was originally a way to predict whether an electronic oscillator would sustain oscillation; it turns out to map cleanly onto any feedback loop you can attach an error signal to.
|
|
460
486
|
|
|
461
|
-
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, decides what to do,
|
|
487
|
+
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, and decides what to do — stop, continue, or roll back to the best output seen so far.
|
|
462
488
|
|
|
463
489
|
Loop types this applies to in practice:
|
|
464
490
|
|
|
@@ -2,7 +2,7 @@
|
|
|
2
2
|
|
|
3
3
|
Opt-in. Sends a single POST per loop run to a customer-configured endpoint.
|
|
4
4
|
Privacy: only structural statistics — Aβ values, error magnitudes, state
|
|
5
|
-
transitions,
|
|
5
|
+
transitions, rollback flag, library version, optional opaque
|
|
6
6
|
workload/classification labels. Never sends prompts, completions, error
|
|
7
7
|
contents (the textual content of failures), customer identity beyond the
|
|
8
8
|
bearer token, or best-so-far outputs.
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.4
|
|
2
2
|
Name: loopgain
|
|
3
|
-
Version: 0.5.
|
|
3
|
+
Version: 0.5.2
|
|
4
4
|
Summary: An open-source cost controller for AI agent loops. Stops a loop when it has actually converged and rolls back before it degrades — replacing the max_iterations guess with a real-time loop-gain (Aβ) monitor with five named threshold bands and best-so-far rollback.
|
|
5
5
|
Author-email: Dave Fitzsimmons <hello@loopgain.ai>
|
|
6
6
|
License: Apache-2.0
|
|
@@ -53,19 +53,24 @@ Dynamic: license-file
|
|
|
53
53
|
|
|
54
54
|
AI agent loops waste time and money when they don't know when to stop. LoopGain measures the loop in real time and stops it the moment it has actually converged — and rolls back before it degrades — instead of running to a fixed `max_iterations` cap.
|
|
55
55
|
|
|
56
|
-
> **
|
|
56
|
+
> **Benchmark — 2,000 paired trials across 10 workload cells** ([run it yourself](https://github.com/loopgain-ai/loopgain-bench)):
|
|
57
|
+
>
|
|
58
|
+
> - **92.8% less API spend** than `max_iter=20` — $27.05 → $1.94 in total benchmark spend
|
|
59
|
+
> - **~15× faster** — median wall-clock per trial 30.9s → 2.1s
|
|
60
|
+
> - **Quality preserved, not traded for speed** — judge win-rate 0.50–0.63 on natural-distribution workloads (W1–W4, CI excluding null on most cells), 0.92–0.95 on engineered-failure workloads (W5); 0.678 weighted preference across 1,800 judge comparisons
|
|
61
|
+
> - **Zero of six kill criteria fired** (all six pre-registered with thresholds before the run)
|
|
62
|
+
|
|
63
|
+
**Honest limits, up front:** LoopGain detects *convergence, not correctness* — it knows when more iterations won't help, not whether the answer is right, and it's only as good as the verifier behind your error signal. [The full list of what it can't do →](#what-loopgain-does-and-doesnt-guarantee)
|
|
57
64
|
|
|
58
65
|
[](https://pypi.org/project/loopgain/)
|
|
59
66
|
[](https://pypi.org/project/loopgain/)
|
|
60
67
|
[](LICENSE)
|
|
61
|
-
[](tests/)
|
|
62
69
|
|
|
63
70
|
**Home:** [loopgain.ai](https://loopgain.ai)
|
|
64
71
|
|
|
65
72
|
Works for **any iterative AI workflow with a measurable error signal** — verify-revise loops, refinement passes, tool-use retry chains, RAG with self-correction, code-gen with linter feedback, multi-step reasoning loops. **Pre-built adapters for [LangGraph](#langgraph), [CrewAI](#crewai), [AutoGen](#autogen-v04), [LangChain](#langchain), [OpenAI Agents SDK](#openai-agents-sdk), and [Claude Agent SDK](#claude-agent-sdk)**; drop-in via the raw API for any custom stack. Pure Python, no runtime dependencies.
|
|
66
73
|
|
|
67
|
-
**Keywords:** AI agent loops · agentic AI · infinite loop detection · divergence detection · early stopping · convergence · agent orchestration · LLM stability · generator-verifier-reviser · feedback-loop control.
|
|
68
|
-
|
|
69
74
|
---
|
|
70
75
|
|
|
71
76
|
## Why
|
|
@@ -176,13 +181,34 @@ This transforms divergence detection from "abort with garbage" into "abort with
|
|
|
176
181
|
|
|
177
182
|
---
|
|
178
183
|
|
|
184
|
+
## See it across a fleet (optional dashboard)
|
|
185
|
+
|
|
186
|
+
The library is the whole product locally — telemetry is opt-in and self-hostable. If you want a fleet view of every loop's stability, cost, and rollbacks across a team, there's a hosted dashboard fed by the [telemetry receiver](https://github.com/loopgain-ai/telemetry-receiver):
|
|
187
|
+
|
|
188
|
+
[](https://dashboard.loopgain.ai/demo)
|
|
189
|
+
|
|
190
|
+
**[Open the live demo →](https://dashboard.loopgain.ai/demo)** — no signup, real benchmark data.
|
|
191
|
+
|
|
192
|
+
The receiver and dashboard are both open-source — self-host to keep telemetry entirely under your control.
|
|
193
|
+
|
|
194
|
+
### Repositories
|
|
195
|
+
|
|
196
|
+
| Repo | What it is |
|
|
197
|
+
| --- | --- |
|
|
198
|
+
| [**loopgain**](https://github.com/loopgain-ai/loopgain) | This library — the Apache-2.0 control loop (you are here) |
|
|
199
|
+
| [**telemetry-receiver**](https://github.com/loopgain-ai/telemetry-receiver) | Cloudflare Worker that ingests anonymized loop telemetry |
|
|
200
|
+
| [**dashboard**](https://github.com/loopgain-ai/dashboard) | The fleet dashboard — self-hostable |
|
|
201
|
+
| [**loopgain-bench**](https://github.com/loopgain-ai/loopgain-bench) | The reproducible 2,000-trial benchmark behind the numbers above |
|
|
202
|
+
|
|
203
|
+
---
|
|
204
|
+
|
|
179
205
|
## What LoopGain does and doesn't guarantee
|
|
180
206
|
|
|
181
|
-
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8%
|
|
207
|
+
LoopGain saves money by stopping a loop once it stops improving — fewer iterations, fewer tokens. In our [public benchmark](https://github.com/loopgain-ai/loopgain-bench), that was a **92.8% cut in total API spend** vs `max_iterations=20`, with output quality preserved. Two honest limits:
|
|
182
208
|
|
|
183
209
|
- **Savings depend on your workload.** Loops that usually succeed fast save the most (~96%); adversarial, failure-prone loops save less (~78–84%). The headline is a blend — run the benchmark on your own loops before quoting a number.
|
|
184
210
|
- **LoopGain detects convergence, not correctness.** It stops when your error signal stops improving — which means more iterations won't help, *not* that the loop succeeded. On the benchmark this preserved quality (it rarely stopped early on a worse output; false-stop rate ≤4.5%), but a loop can stall with the error still above zero — a plateau at, say, 2 failing tests. So check `result.best_error` (or your own pass/fail) before you trust the output: if it plateaued short of your target, that's a quality gap LoopGain can't see, and a false stop that forces a rerun is the one way it eats into the savings. LoopGain decides *when to stop*; you decide *whether the answer is good enough*.
|
|
185
|
-
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against.
|
|
211
|
+
- **LoopGain is only as right as your verifier.** It acts on the error signal you give it. If your verifier reports zero errors, LoopGain trusts that and stops — so a verifier with blind spots can report success on an answer that is still wrong, and LoopGain will confidently stop there. This is not the plateau case above: the error reads zero and the loop looks like a clean success, so neither LoopGain nor its convergence signal can flag it. The quality of the stop is bounded by the quality of the check behind your error signal. We measured this on the benchmark's code-gen workload: **4.5% of converged runs (16/355) passed every check the loop ran but failed the full held-out test suite** — and that's a floor, not a ceiling, because the in-loop verifier there was strong; a weaker verifier exposes more. (Distinct from the ≤4.5% false-stop rate above — the numbers coincide, the failure modes don't.) Pair LoopGain with the strongest verifier you can afford at the stop — executable tests over a sampled subset, a schema or type check over a vibe, a held-out check the loop didn't optimize against. **[How to design a strong verifier](https://loopgain.ai/blog/posts/how-to-design-a-strong-verifier/)** is a field guide to exactly this.
|
|
186
212
|
|
|
187
213
|
---
|
|
188
214
|
|
|
@@ -246,9 +272,9 @@ python3 -c "import keyring; keyring.set_password('loopgain', 'telemetry', input(
|
|
|
246
272
|
# Then in code: keyring.get_password('loopgain', 'telemetry')
|
|
247
273
|
```
|
|
248
274
|
|
|
249
|
-
What is sent: state transitions, Aβ summary (min/max/median),
|
|
275
|
+
What is sent: state transitions, Aβ summary (min/max/median), rollback flag, iterations used, savings, library version, optional opaque `workload_id`, threshold config, hour-bucketed timestamp — and, unless you pass `include_per_iteration=False`, a length-capped per-iteration trajectory (smoothed Aβ values and numeric error magnitudes; this is what drives the dashboard's convergence-profile scrubbing).
|
|
250
276
|
|
|
251
|
-
**What is NEVER sent: prompts, completions, error contents, output buffer,
|
|
277
|
+
**What is NEVER sent: prompts, completions, error contents, the output buffer, or any customer identity beyond the bearer token.** Numeric error *magnitudes* are sent (they're the loop-gain signal); error *contents* never are. Privacy contract is enforced by the payload-shape unit tests in `tests/test_telemetry.py`.
|
|
252
278
|
|
|
253
279
|
The hosted endpoint at `telemetry.loopgain.ai` is one acceptable destination. The [receiver](https://github.com/loopgain-ai/telemetry-receiver) and [dashboard](https://github.com/loopgain-ai/dashboard) are both open-source — self-host to keep telemetry fully under your control.
|
|
254
280
|
|
|
@@ -507,7 +533,7 @@ This is alpha software. The API may break before 1.0 if production usage surface
|
|
|
507
533
|
|
|
508
534
|
LoopGain applies the **Barkhausen stability criterion** (Heinrich Barkhausen, 1921 — the foundational result on when feedback amplifiers oscillate) to AI agent feedback loops. The criterion was originally a way to predict whether an electronic oscillator would sustain oscillation; it turns out to map cleanly onto any feedback loop you can attach an error signal to.
|
|
509
535
|
|
|
510
|
-
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, decides what to do,
|
|
536
|
+
The cleanest summary: an iterative AI loop with a measurable error signal is a feedback system. The ratio `E(n) / E(n-1)` is its empirical loop gain. The Barkhausen result tells you that loop gain less than 1 converges, equal to 1 oscillates, greater than 1 diverges. LoopGain operationalizes this: classifies the loop's current band, and decides what to do — stop, continue, or roll back to the best output seen so far.
|
|
511
537
|
|
|
512
538
|
Loop types this applies to in practice:
|
|
513
539
|
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|
|
File without changes
|