jntajis-python 0.0.13__tar.gz → 0.0.16__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- jntajis_python-0.0.16/.agents/docs/ARCHITECTURE.md +154 -0
- jntajis_python-0.0.16/.agents/docs/IMPLEMENTATION.md +238 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/.gitignore +6 -0
- jntajis_python-0.0.16/PKG-INFO +117 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/conf.py +0 -1
- jntajis_python-0.0.16/pyproject.toml +107 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/Makefile +20 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/api.rst +834 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/changelog.rst +217 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/conf.py +53 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/index.rst +29 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/links.rst +29 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/make.bat +35 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/tests.rst +17 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/upgrade.rst +168 -0
- jntajis_python-0.0.16/pythoncapi-compat/docs/users.rst +74 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/__init__.py +19 -3
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/_jntajis.pyx +26 -24
- jntajis_python-0.0.16/src/jntajis/_version.py +34 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/gen.py +9 -26
- jntajis_python-0.0.16/src/jntajis/pythoncapi_compat_shim.h +20 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/xlsx_parser/parser.py +0 -1
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/xlsx_parser/xmlutils.py +9 -25
- jntajis-python-0.0.13/.black.ini +0 -2
- jntajis-python-0.0.13/.flake8 +0 -2
- jntajis-python-0.0.13/.github/workflows/wheels.yml +0 -33
- jntajis-python-0.0.13/.readthedocs.yaml +0 -11
- jntajis-python-0.0.13/MANIFEST.in +0 -8
- jntajis-python-0.0.13/Makefile +0 -25
- jntajis-python-0.0.13/PKG-INFO +0 -110
- jntajis-python-0.0.13/setup.cfg +0 -57
- jntajis-python-0.0.13/setup.py +0 -10
- jntajis-python-0.0.13/src/jntajis/_jntajis.c +0 -15348
- jntajis-python-0.0.13/src/jntajis/tests/test_encoder.py +0 -269
- jntajis-python-0.0.13/src/jntajis/tests/test_mj_translit.py +0 -155
- jntajis-python-0.0.13/src/jntajis_python.egg-info/PKG-INFO +0 -110
- jntajis-python-0.0.13/src/jntajis_python.egg-info/SOURCES.txt +0 -38
- jntajis-python-0.0.13/src/jntajis_python.egg-info/dependency_links.txt +0 -1
- jntajis-python-0.0.13/src/jntajis_python.egg-info/not-zip-safe +0 -1
- jntajis-python-0.0.13/src/jntajis_python.egg-info/requires.txt +0 -9
- jntajis-python-0.0.13/src/jntajis_python.egg-info/top_level.txt +0 -1
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/LICENSE +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/README.md +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/.gitignore +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/Makefile +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/make.bat +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/_static/images/mj-jnta.svg +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/_static/images/relationships-character-mappings.svg +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/api.rst +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/index.rst +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/docs/source/license.rst +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/_jntajis.h +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/_jntajis.pyi +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/py.typed +0 -0
- {jntajis-python-0.0.13 → jntajis_python-0.0.16}/src/jntajis/xlsx_parser/__init__.py +0 -0
|
@@ -0,0 +1,154 @@
|
|
|
1
|
+
# Architecture
|
|
2
|
+
|
|
3
|
+
## Project Overview
|
|
4
|
+
|
|
5
|
+
jntajis-python is a Python library for transliterating and encoding/decoding characters across three Japanese character set standards: JIS X 0208, JIS X 0213, and Unicode. It also supports transliteration via the MJ (Moji Joho) character table and shrink conversion maps.
|
|
6
|
+
|
|
7
|
+
## Directory Layout
|
|
8
|
+
|
|
9
|
+
```
|
|
10
|
+
jntajis-python/
|
|
11
|
+
setup.py # setuptools + Cython extension build
|
|
12
|
+
setup.cfg # Package metadata, dependencies, dev extras
|
|
13
|
+
Makefile # Data pipeline: download -> parse -> codegen
|
|
14
|
+
src/jntajis/
|
|
15
|
+
__init__.py # Public Python API surface (enums + re-exports)
|
|
16
|
+
_jntajis.pyx # Cython implementation (core logic)
|
|
17
|
+
_jntajis.h # Generated C header (lookup tables)
|
|
18
|
+
_jntajis.pyi # Type stubs for the Cython extension
|
|
19
|
+
_jntajis.c # Cython-generated C source (not committed normally)
|
|
20
|
+
gen.py # Code generator: Excel/JSON -> _jntajis.h
|
|
21
|
+
py.typed # PEP 561 marker
|
|
22
|
+
tests/
|
|
23
|
+
test_encoder.py # Tests for encoding/decoding and IncrementalEncoder
|
|
24
|
+
test_mj_translit.py # Tests for MJ shrink candidate transliteration
|
|
25
|
+
xlsx_parser/
|
|
26
|
+
__init__.py # Re-exports read_xlsx
|
|
27
|
+
parser.py # Streaming OpenXML XLSX reader
|
|
28
|
+
xmlutils.py # SAX-style XML parser framework (expat-based)
|
|
29
|
+
docs/
|
|
30
|
+
source/
|
|
31
|
+
api.rst # Sphinx API documentation
|
|
32
|
+
conf.py # Sphinx configuration
|
|
33
|
+
_static/images/ # SVG diagrams
|
|
34
|
+
.github/workflows/
|
|
35
|
+
main.yml # CI entry point (PR + push + tag triggers)
|
|
36
|
+
tests.yml # Lint (black, flake8, mypy) + test job
|
|
37
|
+
wheels.yml # cibuildwheel multi-platform wheel builds
|
|
38
|
+
```
|
|
39
|
+
|
|
40
|
+
## High-Level Architecture
|
|
41
|
+
|
|
42
|
+
The system has three distinct phases: **data pipeline** (build-time), **native extension** (compile-time), and **runtime API** (user-facing).
|
|
43
|
+
|
|
44
|
+
### 1. Data Pipeline (build-time, `Makefile` + `gen.py`)
|
|
45
|
+
|
|
46
|
+
External data sources are downloaded and processed into a single generated C header file:
|
|
47
|
+
|
|
48
|
+
```
|
|
49
|
+
[JNTA Excel] ---+
|
|
50
|
+
[MJ Excel] ---+--> gen.py (Jinja2 template) --> _jntajis.h (C lookup tables)
|
|
51
|
+
[MJ Shrink JSON]+
|
|
52
|
+
```
|
|
53
|
+
|
|
54
|
+
- **JNTA Excel** (`jissyukutaimap1_0_0.xlsx`): NTA shrink conversion map. Downloaded from NTA.
|
|
55
|
+
- **MJ Excel** (`mji.00601.xlsx`): MJ character table. Downloaded from CITPC/IPA.
|
|
56
|
+
- **MJ Shrink JSON** (`MJShrinkMap.1.2.0.json`): MJ shrink conversion map. Downloaded from CITPC/IPA.
|
|
57
|
+
|
|
58
|
+
`gen.py` uses a custom `xlsx_parser` to read the Excel files, processes the data into optimized lookup structures, and renders `_jntajis.h` via a Jinja2 template. The generated header contains:
|
|
59
|
+
|
|
60
|
+
- `tx_mappings[]`: 2*94*94 entries, one per JIS X 0213 codepoint (men-ku-ten)
|
|
61
|
+
- `urange_to_jis_mappings[]`: Sorted ranges for Unicode-to-JIS binary search
|
|
62
|
+
- `sm_uni_to_jis_mapping()`: State machine for multi-codepoint Unicode-to-JIS mapping
|
|
63
|
+
- `urange_to_mj_mappings[]`: Sorted ranges for Unicode-to-MJ-mapping-set binary search
|
|
64
|
+
- `mj_shrink_mappings[]`: MJ shrink mapping unicode sets indexed by MJ code
|
|
65
|
+
|
|
66
|
+
### 2. Native Extension (compile-time, Cython)
|
|
67
|
+
|
|
68
|
+
`_jntajis.pyx` is a Cython file compiled into a C extension module. It:
|
|
69
|
+
|
|
70
|
+
- Includes `_jntajis.h` via `cdef extern` to access the generated lookup tables
|
|
71
|
+
- Uses CPython internal APIs (`_PyUnicodeWriter`, `_PyBytesWriter`, `PyUnicode_READ`, etc.) directly for high-performance string construction
|
|
72
|
+
- Compiles with safety checks disabled (`boundscheck=False`, `wraparound=False`, `cdivision=True`)
|
|
73
|
+
|
|
74
|
+
The build process is: `_jntajis.pyx` + `_jntajis.h` --> Cython --> `_jntajis.c` --> C compiler --> `_jntajis.so`.
|
|
75
|
+
|
|
76
|
+
### 3. Runtime API
|
|
77
|
+
|
|
78
|
+
The public API is exposed via `__init__.py` which re-exports from the Cython extension:
|
|
79
|
+
|
|
80
|
+
| Symbol | Type | Description |
|
|
81
|
+
|--------|------|-------------|
|
|
82
|
+
| `jnta_encode()` | function | Unicode -> JIS byte sequence |
|
|
83
|
+
| `jnta_decode()` | function | JIS byte sequence -> Unicode |
|
|
84
|
+
| `jnta_shrink_translit()` | function | JNTA shrink transliteration (Unicode -> Unicode) |
|
|
85
|
+
| `mj_shrink_candidates()` | function | MJ-based shrink transliteration candidates |
|
|
86
|
+
| `IncrementalEncoder` | class | Stateful encoder (codec-compatible) |
|
|
87
|
+
| `TransliterationError` | exception | Raised on transliteration failure |
|
|
88
|
+
| `ConversionMode` | enum | Encoding mode selection |
|
|
89
|
+
| `MJShrinkScheme` | enum | Individual MJ shrink scheme identifiers |
|
|
90
|
+
| `MJShrinkSchemeCombo` | flag enum | Combinable MJ shrink scheme selectors |
|
|
91
|
+
|
|
92
|
+
## Key Data Structures
|
|
93
|
+
|
|
94
|
+
### JIS Code Representation
|
|
95
|
+
|
|
96
|
+
JIS codepoints are packed into a `uint16_t` as: `(men - 1) * 94 * 94 + (ku - 1) * 94 + (ten - 1)`, where men is 1 or 2 (JIS X 0213 plane), ku is 1-94 (row), ten is 1-94 (column).
|
|
97
|
+
|
|
98
|
+
### ShrinkingTransliterationMapping
|
|
99
|
+
|
|
100
|
+
Each JIS X 0213 position has an entry:
|
|
101
|
+
- `jis`: packed men-ku-ten code
|
|
102
|
+
- `us[2]`: primary Unicode codepoint(s)
|
|
103
|
+
- `sus[2]`: secondary (similar glyph) Unicode codepoint(s)
|
|
104
|
+
- `class_`: JIS character class (level 1-4, non-kanji, reserved)
|
|
105
|
+
- `tx_jis[4]`/`tx_us[4]`: transliterated form (JIS and Unicode)
|
|
106
|
+
|
|
107
|
+
### Unicode-to-JIS Reverse Lookup
|
|
108
|
+
|
|
109
|
+
Uses sorted range tables (`URangeToJISMapping`) with binary search. Multi-codepoint sequences (e.g. base + combining mark) use a state machine (`sm_uni_to_jis_mapping()`).
|
|
110
|
+
|
|
111
|
+
### MJ Mapping Structures
|
|
112
|
+
|
|
113
|
+
- `MJMapping`: Maps an MJ code to Unicode codepoints + IVS (Ideographic Variation Sequence) pairs
|
|
114
|
+
- `MJMappingSet`: A set of MJ mappings for a single Unicode codepoint
|
|
115
|
+
- `URangeToMJMappings`: Sorted range table for Unicode-to-MJ binary search
|
|
116
|
+
- `MJShrinkMappingUnicodeSet`: Per-MJ-code shrink targets, one array per scheme (4 schemes)
|
|
117
|
+
|
|
118
|
+
## Component Interactions
|
|
119
|
+
|
|
120
|
+
```
|
|
121
|
+
User code
|
|
122
|
+
|
|
|
123
|
+
v
|
|
124
|
+
__init__.py (Python enums + re-exports)
|
|
125
|
+
|
|
|
126
|
+
v
|
|
127
|
+
_jntajis.pyx (Cython: encoding, decoding, transliteration logic)
|
|
128
|
+
|
|
|
129
|
+
v
|
|
130
|
+
_jntajis.h (Generated C: static lookup tables + state machine)
|
|
131
|
+
```
|
|
132
|
+
|
|
133
|
+
## xlsx_parser Sub-package
|
|
134
|
+
|
|
135
|
+
A lightweight, streaming, read-only XLSX parser. It avoids heavyweight dependencies like openpyxl by:
|
|
136
|
+
|
|
137
|
+
1. Opening XLSX as a zip file (`zipfile.ZipFile`)
|
|
138
|
+
2. Parsing `xl/sharedStrings.xml` for the shared string table
|
|
139
|
+
3. Parsing `xl/worksheets/sheetN.xml` incrementally via SAX-style handlers
|
|
140
|
+
|
|
141
|
+
The XML parsing framework in `xmlutils.py` provides:
|
|
142
|
+
- A hierarchical `Handlers`/`HandlersBase` abstract pattern where each nesting level of XML is handled by a different handler class
|
|
143
|
+
- `HandlerShim` wraps handlers to dynamically switch the active handler as XML nesting changes
|
|
144
|
+
- `read_xml_incremental()` enables pull-style iteration over worksheet rows
|
|
145
|
+
|
|
146
|
+
## CI/CD
|
|
147
|
+
|
|
148
|
+
- **Trigger** (`main.yml`): On PR open, push to main, or version tag push (`v*`)
|
|
149
|
+
- **Lint & Test** (`tests.yml`): black + flake8 + mypy on Python 3.11
|
|
150
|
+
- **Wheels** (`wheels.yml`): cibuildwheel across Ubuntu, Windows, macOS (11/12/13), excluding PyPy. Only runs on tag push.
|
|
151
|
+
|
|
152
|
+
## Documentation
|
|
153
|
+
|
|
154
|
+
Sphinx with `sphinx_rtd_theme`, hosted on Read the Docs. API docs are manually authored in `api.rst` (not autodoc).
|
|
@@ -0,0 +1,238 @@
|
|
|
1
|
+
# Implementation Details
|
|
2
|
+
|
|
3
|
+
## Code Generation (`gen.py`)
|
|
4
|
+
|
|
5
|
+
### Entry Point
|
|
6
|
+
|
|
7
|
+
`gen.py` provides a CLI via `click`:
|
|
8
|
+
|
|
9
|
+
```
|
|
10
|
+
python -m jntajis.gen -- <dest> <src_jnta> <src_mj> <src_mj_shrink>
|
|
11
|
+
```
|
|
12
|
+
|
|
13
|
+
### Input Parsing
|
|
14
|
+
|
|
15
|
+
Three source data files are read:
|
|
16
|
+
|
|
17
|
+
1. **`read_jnta_excel_file()`** parses the NTA shrink map Excel:
|
|
18
|
+
- Validates header rows match expected Japanese column names
|
|
19
|
+
- For each row: parses men-ku-ten code, Unicode codepoint(s), JIS character class, transliteration target (single or multi-char)
|
|
20
|
+
- Fills gaps between consecutive JIS codes with `RESERVED` entries
|
|
21
|
+
- Extracts secondary Unicode mappings from memo fields via regex
|
|
22
|
+
|
|
23
|
+
2. **`read_mj_excel_file()`** parses the MJ character table Excel:
|
|
24
|
+
- Extracts MJ code, corresponding UCS, implemented UCS, IVS pairs (Moji_Joho collection + SVS)
|
|
25
|
+
- Builds `UIVSPair` tuples (Unicode codepoint + variation selector number)
|
|
26
|
+
- Tracks max variant count across all entries
|
|
27
|
+
|
|
28
|
+
3. **`read_mj_shrink_file()`** parses the MJ shrink map JSON:
|
|
29
|
+
- Reads target Unicode codepoints for each of the 4 shrink schemes
|
|
30
|
+
- Groups by source MJ code
|
|
31
|
+
|
|
32
|
+
### Data Structure Construction
|
|
33
|
+
|
|
34
|
+
1. **`build_reverse_mappings()`**: Builds Unicode-to-JIS reverse lookup:
|
|
35
|
+
- Sorts all mappings by primary Unicode codepoint
|
|
36
|
+
- Groups contiguous codepoints into ranges (`URangeToJISMapping`), splitting at gaps >= `gap_thr` (default 256)
|
|
37
|
+
- Separately collects multi-codepoint sequences into `Outer` groups for the state machine
|
|
38
|
+
|
|
39
|
+
2. **`build_digested_shrink_mappings()`**: Linearizes MJ shrink mappings:
|
|
40
|
+
- Creates a dense array indexed by MJ code
|
|
41
|
+
- Fills gaps with empty tuples
|
|
42
|
+
- Tracks per-scheme maximum array lengths
|
|
43
|
+
|
|
44
|
+
3. **`build_chunked_mj_mappings()`**: Builds Unicode-to-MJ reverse lookup:
|
|
45
|
+
- Groups all MJ mappings by Unicode codepoint
|
|
46
|
+
- Chunks contiguous ranges, splitting at gaps >= 64
|
|
47
|
+
- Returns `URangeToMJMappings` list + max mapping set size
|
|
48
|
+
|
|
49
|
+
### Template Rendering
|
|
50
|
+
|
|
51
|
+
Uses Jinja2 to render the C header from `code_template`. The template generates:
|
|
52
|
+
|
|
53
|
+
- `JISCharacterClass` enum
|
|
54
|
+
- `ShrinkingTransliterationMapping` struct and the `tx_mappings[]` array (2 * 94 * 94 entries)
|
|
55
|
+
- Per-range `uint16_t` arrays for Unicode-to-JIS lookup
|
|
56
|
+
- `URangeToJISMapping` array for binary search
|
|
57
|
+
- `sm_uni_to_jis_mapping()` function: a C switch-based state machine for multi-codepoint Unicode sequences
|
|
58
|
+
- MJ-related structs and arrays (`MJMapping`, `MJMappingSet`, `URangeToMJMappings`, `MJShrinkMappingUnicodeSet`)
|
|
59
|
+
|
|
60
|
+
## Cython Extension (`_jntajis.pyx`)
|
|
61
|
+
|
|
62
|
+
### Compiler Directives
|
|
63
|
+
|
|
64
|
+
```cython
|
|
65
|
+
# cython: language_level=3, cdivision=True, boundscheck=False, wraparound=False, embedsignature=True
|
|
66
|
+
```
|
|
67
|
+
|
|
68
|
+
All safety checks are disabled for performance. `embedsignature=True` embeds Python signatures in docstrings.
|
|
69
|
+
|
|
70
|
+
### Core Internal Types
|
|
71
|
+
|
|
72
|
+
- **`JNTAJISIncrementalEncoder`**: Struct holding encoder state:
|
|
73
|
+
- `encoding`: Python string (ref-counted) for error reporting
|
|
74
|
+
- `replacement`: Fallback JIS code (0xFFFF = no replacement)
|
|
75
|
+
- `put_jis`: Function pointer selecting the output strategy
|
|
76
|
+
- `la[32]`/`lal`: Lookahead buffer for multi-codepoint sequences
|
|
77
|
+
- `shift_state`/`state`: State machine state
|
|
78
|
+
|
|
79
|
+
- **`JNTAJISIncrementalEncoderContext`**: Per-call context wrapping the encoder + `_PyBytesWriter` for output construction
|
|
80
|
+
|
|
81
|
+
- **`JNTAJISShrinkingTransliteratorContext`**: Per-call context for `jnta_shrink_translit`, using `_PyUnicodeWriter` for output
|
|
82
|
+
|
|
83
|
+
- **`MJShrinkCandidates`**: Manages cartesian product enumeration for `mj_shrink_candidates`
|
|
84
|
+
|
|
85
|
+
### Encoding Flow (`jnta_encode` / `IncrementalEncoder.encode`)
|
|
86
|
+
|
|
87
|
+
1. Initialize `_PyBytesWriter` with estimated size (2 * input length)
|
|
88
|
+
2. For each Unicode codepoint in input:
|
|
89
|
+
a. Feed to `sm_uni_to_jis_mapping()` state machine
|
|
90
|
+
b. If state machine returns a JIS code (state == -1): call `put_jis` function pointer
|
|
91
|
+
c. If state machine is still consuming (state > 0): buffer in lookahead
|
|
92
|
+
d. If state machine returns to state 0 with buffered chars: flush lookahead via reverse table lookup
|
|
93
|
+
3. On flush: flush remaining lookahead, emit shift-out if in SISO mode
|
|
94
|
+
4. Finalize bytes writer
|
|
95
|
+
|
|
96
|
+
### Output Strategies (`put_jis` function pointers)
|
|
97
|
+
|
|
98
|
+
| Function | ConversionMode | Behavior |
|
|
99
|
+
|----------|---------------|----------|
|
|
100
|
+
| `jis_put_siso` | SISO | Emits SI/SO escape bytes for plane switching + 2-byte JIS |
|
|
101
|
+
| `jis_put_men_1` | MEN1 | Only allows plane 1; rejects plane 2 characters |
|
|
102
|
+
| `jis_put_jisx0208` | JISX0208 | Only allows level 1/2 kanji and JIS X 0208 non-kanji |
|
|
103
|
+
| `jis_put_jisx0208_translit` | JISX0208_TRANSLIT | Like JISX0208, but falls back to `tx_jis[]`/`tx_us[]` transliteration for non-0208 chars |
|
|
104
|
+
|
|
105
|
+
### Decoding Flow (`jnta_decode`)
|
|
106
|
+
|
|
107
|
+
1. Initialize `_PyUnicodeWriter`
|
|
108
|
+
2. Parse byte pairs as JIS row+column codes
|
|
109
|
+
3. Handle SI (0x0E) / SO (0x0F) shift bytes in SISO mode
|
|
110
|
+
4. Look up `tx_mappings[jis]` to get Unicode codepoint(s)
|
|
111
|
+
5. Write 1 or 2 Unicode codepoints per JIS code
|
|
112
|
+
|
|
113
|
+
### JNTA Shrink Transliteration (`jnta_shrink_translit`)
|
|
114
|
+
|
|
115
|
+
1. Initialize `_PyUnicodeWriter`
|
|
116
|
+
2. For each Unicode codepoint: use `sm_uni_to_jis_mapping()` to find JIS code
|
|
117
|
+
3. If the JIS code maps to a level 3/4 or non-kanji-extended character with a transliteration entry: output the transliterated form (`tx_us[]`)
|
|
118
|
+
4. Otherwise: output the original Unicode codepoint(s) from `us[]`
|
|
119
|
+
5. If no mapping found: use replacement string or passthrough
|
|
120
|
+
|
|
121
|
+
### MJ Shrink Candidates (`mj_shrink_candidates`)
|
|
122
|
+
|
|
123
|
+
This is the most complex function. It:
|
|
124
|
+
|
|
125
|
+
1. Allocates per-character candidate arrays (`UIVSPair[20]` per position)
|
|
126
|
+
2. For each input character (possibly with trailing IVS):
|
|
127
|
+
a. Look up `urange_to_mj_mappings` to find candidate `MJMapping` entries
|
|
128
|
+
b. If IVS present: filter to exact IVS match
|
|
129
|
+
c. If no IVS: collect all non-IVS variants
|
|
130
|
+
d. For each matching MJ code, look up `mj_shrink_mappings` and collect target Unicode codepoints per selected scheme (combo bitmask)
|
|
131
|
+
e. Also include the original Unicode variants from the MJ mapping itself
|
|
132
|
+
f. If no candidates: keep the original character
|
|
133
|
+
3. Enumerate the cartesian product of per-character candidates (up to `limit`) using carry-based iteration
|
|
134
|
+
4. Build result strings using `_PyUnicodeWriter`
|
|
135
|
+
|
|
136
|
+
### Binary Search Pattern
|
|
137
|
+
|
|
138
|
+
Both `lookup_rev_table()` and `lookup_mj_mapping_table()` use the same pattern:
|
|
139
|
+
- Binary search over sorted range arrays
|
|
140
|
+
- Each range has `start`, `end`, and a pointer to a dense sub-array
|
|
141
|
+
- Index into sub-array as `array[u - start]`
|
|
142
|
+
|
|
143
|
+
### Unicode String Internals Access
|
|
144
|
+
|
|
145
|
+
The extension directly uses CPython internal APIs for zero-copy string access:
|
|
146
|
+
- `PyUnicode_KIND()`: Get the internal storage width (1/2/4 byte)
|
|
147
|
+
- `PyUnicode_DATA()`: Get raw buffer pointer
|
|
148
|
+
- `PyUnicode_READ()`: Read a codepoint at an index
|
|
149
|
+
- `_PyUnicodeWriter` / `_PyBytesWriter`: Internal buffer builders that handle memory allocation and string compaction
|
|
150
|
+
|
|
151
|
+
This makes the code CPython-specific and incompatible with other Python implementations.
|
|
152
|
+
|
|
153
|
+
## xlsx_parser Implementation
|
|
154
|
+
|
|
155
|
+
### xmlutils.py - XML Framework
|
|
156
|
+
|
|
157
|
+
The framework builds a hierarchical SAX handler system:
|
|
158
|
+
|
|
159
|
+
- **`Handlers`** (ABC): Defines `start_element()`, `end_element()`, `cdata()` -- each returns `Optional[Handlers]` to signal handler switching
|
|
160
|
+
- **`HandlersBase`**: Concrete base with `outer` (parent handler), `parser` ref, `path` tuple for error reporting, and `next()` for creating child handlers
|
|
161
|
+
- **`HandlerShim`**: Adapts the handler-switching protocol to expat's flat callback interface; stores the current handler and swaps it when a method returns non-None
|
|
162
|
+
- **`wrap_start_element_handler`**: Decorator that splits `namespace\nlocal_name` and converts attlist to `OrderedDict`
|
|
163
|
+
- **`read_xml_incremental()`**: Drives expat parsing in 4KB chunks, yielding events from a `pull_events` callback between chunks
|
|
164
|
+
|
|
165
|
+
### parser.py - XLSX Parser
|
|
166
|
+
|
|
167
|
+
Layered handler hierarchy for each XML document:
|
|
168
|
+
|
|
169
|
+
**Shared strings** (`xl/sharedStrings.xml`):
|
|
170
|
+
- Level 0 (`SharedStringsReader_0`): Expects `<sst>`
|
|
171
|
+
- Level 1 (`SharedStringsReader_1`): Iterates `<si>` elements
|
|
172
|
+
- Level 2 (`SharedStringsReader_2`): Extracts text from `<t>` within `<si>`
|
|
173
|
+
|
|
174
|
+
**Worksheet** (`xl/worksheets/sheetN.xml`):
|
|
175
|
+
- Level 0 (`WorksheetReader_0`): Expects `<worksheet>`
|
|
176
|
+
- Level 1 (`WorksheetReader_1`): Handles `<dimension>` and `<sheetData>`
|
|
177
|
+
- Level 2 (`WorksheetReader_2`): Iterates `<row>` elements
|
|
178
|
+
- Level 3 (`WorksheetReader_3`): Iterates `<c>` (cell) elements within a row
|
|
179
|
+
- Level 4 (`WorksheetReader_4`): Extracts `<v>` (value) or `<f>` (formula) content
|
|
180
|
+
|
|
181
|
+
**`StreamingWorksheetReader`**: Resolves shared string references (`t="s"`) and pads sparse rows into dense arrays based on cell references (e.g. "A1", "C3").
|
|
182
|
+
|
|
183
|
+
**`ReadonlyWorkbook`/`ReadonlyWorksheet`**: Top-level API wrapping zipfile access with lazy shared string loading and incremental row iteration.
|
|
184
|
+
|
|
185
|
+
## Python API Layer (`__init__.py`)
|
|
186
|
+
|
|
187
|
+
### Enums
|
|
188
|
+
|
|
189
|
+
- **`ConversionMode`** (`IntEnum`): SISO=0, MEN1=1, JISX0208=2, JISX0208_TRANSLIT=3
|
|
190
|
+
- **`MJShrinkScheme`** (`IntEnum`): Four MJ shrink scheme identifiers (0-3)
|
|
191
|
+
- **`MJShrinkSchemeCombo`** (`IntFlag`): Bitmask flags (1, 2, 4, 8) for combining MJ shrink schemes
|
|
192
|
+
|
|
193
|
+
The Cython extension symbols are imported with a `try/except ImportError` guard so the package can be imported even when the native extension is not built (e.g. for documentation generation).
|
|
194
|
+
|
|
195
|
+
## Build System
|
|
196
|
+
|
|
197
|
+
### setup.py / setup.cfg
|
|
198
|
+
|
|
199
|
+
- Uses `setuptools-scm` for version management (from git tags matching `v*`)
|
|
200
|
+
- Declares a single Cython extension: `jntajis._jntajis` from `src/jntajis/_jntajis.pyx`
|
|
201
|
+
- Requires Cython >= 0.29 at build time
|
|
202
|
+
- No runtime dependencies
|
|
203
|
+
|
|
204
|
+
### Makefile
|
|
205
|
+
|
|
206
|
+
Defines the data pipeline with proper dependency tracking:
|
|
207
|
+
|
|
208
|
+
```
|
|
209
|
+
_jntajis.h <-- gen.py + jissyukutaimap1_0_0.xlsx + mji.00601.xlsx + MJShrinkMap.1.2.0.json
|
|
210
|
+
jissyukutaimap1_0_0.xlsx <-- syukutaimap1_0_0.zip (curl from NTA)
|
|
211
|
+
mji.00601.xlsx <-- mji.00601-xlsx.zip (curl from CITPC)
|
|
212
|
+
MJShrinkMap.1.2.0.json <-- MJShrinkMapVer.1.2.0.zip (curl from CITPC)
|
|
213
|
+
```
|
|
214
|
+
|
|
215
|
+
### CI/CD
|
|
216
|
+
|
|
217
|
+
- Lint + test runs on every PR and push to main
|
|
218
|
+
- Wheel builds only on tag push (`v*`)
|
|
219
|
+
- Wheels built via `cibuildwheel` on: Ubuntu 20.04, Windows 2019, macOS 11/12/13
|
|
220
|
+
- PyPy wheels are skipped (`CIBW_SKIP: pp*`)
|
|
221
|
+
|
|
222
|
+
## Testing
|
|
223
|
+
|
|
224
|
+
Two test modules using pytest:
|
|
225
|
+
|
|
226
|
+
- **`test_encoder.py`**: Tests `jnta_encode()` and `IncrementalEncoder` across all `ConversionMode` values. Covers:
|
|
227
|
+
- Unmapped character encoding errors
|
|
228
|
+
- Single and multi-codepoint sequences (e.g. katakana with combining marks)
|
|
229
|
+
- Transliteration fallback (JISX0208_TRANSLIT mode)
|
|
230
|
+
- Incremental encoding with flush behavior
|
|
231
|
+
- SISO mode with plane switching
|
|
232
|
+
- Supplementary plane characters
|
|
233
|
+
|
|
234
|
+
- **`test_mj_translit.py`**: Tests `mj_shrink_candidates()` with various:
|
|
235
|
+
- Characters with/without IVS
|
|
236
|
+
- Different shrink scheme combinations
|
|
237
|
+
- Characters with multiple shrink candidates
|
|
238
|
+
- Supplementary plane characters (e.g. U+2AC2A)
|
|
@@ -0,0 +1,117 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: jntajis-python
|
|
3
|
+
Version: 0.0.16
|
|
4
|
+
Summary: A fast character conversion and transliteration library based on the scheme defined for Japan National Tax Agency's corporate number system.
|
|
5
|
+
Project-URL: Homepage, https://github.com/opencollector/jntajis-python
|
|
6
|
+
Author-email: "Open Collector, inc." <info@opencollector.co.jp>
|
|
7
|
+
License-Expression: BSD-3-Clause
|
|
8
|
+
License-File: LICENSE
|
|
9
|
+
Keywords: JIS,Japanese,Unicode,conversion,encoding,transliteration
|
|
10
|
+
Classifier: Programming Language :: Python :: 3
|
|
11
|
+
Classifier: Programming Language :: Python :: 3.10
|
|
12
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
13
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
14
|
+
Classifier: Programming Language :: Python :: 3.13
|
|
15
|
+
Classifier: Topic :: Text Processing :: Filters
|
|
16
|
+
Requires-Python: >=3.10
|
|
17
|
+
Provides-Extra: dev
|
|
18
|
+
Requires-Dist: click>=8.3; extra == 'dev'
|
|
19
|
+
Requires-Dist: jinja2>=3; extra == 'dev'
|
|
20
|
+
Requires-Dist: mypy>=1.19; extra == 'dev'
|
|
21
|
+
Requires-Dist: pytest>=6.2; extra == 'dev'
|
|
22
|
+
Requires-Dist: ruff>=0.4; extra == 'dev'
|
|
23
|
+
Requires-Dist: sphinx-rtd-theme>=0.5; extra == 'dev'
|
|
24
|
+
Requires-Dist: sphinx>=4; extra == 'dev'
|
|
25
|
+
Description-Content-Type: text/markdown
|
|
26
|
+
|
|
27
|
+
# jntajis-python
|
|
28
|
+
|
|
29
|
+
Documentation: https://jntajis-python.readthedocs.io/
|
|
30
|
+
|
|
31
|
+
## What's JNTAJIS-python?
|
|
32
|
+
|
|
33
|
+
JNTAJIS-python is a transliteration library, specifically designed for dealing with three different character sets; JIS X 0208, JIS X 0213, and Unicode.
|
|
34
|
+
|
|
35
|
+
```python
|
|
36
|
+
import jntajis
|
|
37
|
+
|
|
38
|
+
print(jntajis.mj_shrink_candidates("髙島屋", jntajis.MJShrinkSchemeCombo.JIS_INCORPORATION_UCS_UNIFICATION_RULE)) # outputs ["高島屋", "髙島屋"]
|
|
39
|
+
print(jntajis.jnta_shrink_translit("麴町")) # outputs "麹町"
|
|
40
|
+
```
|
|
41
|
+
|
|
42
|
+
To that end, this library refers to three different character tables; MJ character table, MJ shrink conversion map, and NTA shrink conversion map.
|
|
43
|
+
|
|
44
|
+
The MJ character table (*MJ文字一覧表*) defines a vast set of kanji (*漢字*) characters used in information processing of Japanese texts initially developed by Information-technology Promotion Agency.
|
|
45
|
+
|
|
46
|
+
The MJ shrink conversion map (*MJ縮退マップ*) was also developed alongside for the sake of interoperability between MJ-aware systems and systems based on Unicode, which is used to transliterate complex, less-frequently-used character variants to commonly-used, more-used ones.
|
|
47
|
+
|
|
48
|
+
The NTA shrink conversion map (*国税庁JIS縮退マップ*) was developed by Japan National Tax Agency to canonicalize user inputs for its corporation number search service provided as a public web API. This maps JIS level 3 and 4 characters to JIS level 1 and 2 characters (i.e. characters defined in JIS X 0208.) Note that not all level 3 and level 4 characters have level 1 and 2 counterparts. Also note that some of level 3 and 4 characters don't map to a single character one by each. Instead, they map to sequences of two or more characters.
|
|
49
|
+
|
|
50
|
+
The table below shows some examples of transliteration by the MJ character table suite and NTA shrink conversion map.
|
|
51
|
+
|
|
52
|
+
| Glyph | MJ code | Unicode | JIS X 0213 | Glyph\* | MJ code\* | JIS X 0208\* | Transliterator |
|
|
53
|
+
| ----- | ------- | ------- | ---------- | ------ | ------- | ---------- | -------------- |
|
|
54
|
+
|  | MJ014031 | U+68C3 | 2-14-90 |  | MJ014007 | 1-45-92 | MJ / JNTA |
|
|
55
|
+
|  | MJ030196 | U+FA11 | 1-47-82 |  | MJ010541 | 1-26-74 | MJ / JNTA |
|
|
56
|
+
|  | MJ028902 | U+9AD9 | N/A | 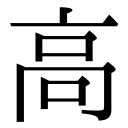 | MJ028901 | 1-25-66 | MJ |
|
|
57
|
+
|
|
58
|
+
The conversion schematics is shown below:
|
|
59
|
+
|
|
60
|
+

|
|
61
|
+
|
|
62
|
+
* JNTA transliteration
|
|
63
|
+
|
|
64
|
+
As every JIS X 0213 characters maps to its Unicode counterpart, the conversion is done only with the single JNTA character mappings table.
|
|
65
|
+
|
|
66
|
+
* MJ transliteration
|
|
67
|
+
|
|
68
|
+
Transliteration is done in two phases:
|
|
69
|
+
|
|
70
|
+
1. Conversion from Unicode to MJ character mappings.
|
|
71
|
+
|
|
72
|
+
While not all characters in the MJ characters table map to Unicode, each MJ code has different shrink mappings. Because of this, the transliterator tries to convert Unicode codepoints to MJ codes first.
|
|
73
|
+
|
|
74
|
+
2. Transliteration by MJ shrink mappings.
|
|
75
|
+
|
|
76
|
+
The transliteration result as a string isn't necessarily single as some MJ codes have more than one transliteration candidate. This happens because a) a Unicode codepoint may map to multiple MJ codes and b) multiple transliteration schemes are designated to a single MJ code.
|
|
77
|
+
|
|
78
|
+
|
|
79
|
+
Relationship between Unicode, MJ character mappings, JIS X 0213, and JIS X 0208 can be depicted as follows:
|
|
80
|
+
|
|
81
|
+

|
|
82
|
+
|
|
83
|
+
## License
|
|
84
|
+
|
|
85
|
+
The source code except `src/jntajis/_jntajis.h` is published under the BSD 3-clause license.
|
|
86
|
+
|
|
87
|
+
`src/jntajis/_jntajis.h` contains the data from the following entities:
|
|
88
|
+
|
|
89
|
+
* JIS shrink conversion mappings (国税庁: JIS縮退マップ)
|
|
90
|
+
|
|
91
|
+
Publisher: National Tax Agency
|
|
92
|
+
|
|
93
|
+
Author: National Tax Agency
|
|
94
|
+
|
|
95
|
+
Source: https://www.houjin-bangou.nta.go.jp/download/
|
|
96
|
+
|
|
97
|
+
License: CC BY 4.0
|
|
98
|
+
|
|
99
|
+
* MJ character table (文字情報技術促進協議会: MJ文字一覧表)
|
|
100
|
+
|
|
101
|
+
Publisher: Character Information Technology Promotion Council (CITPC)
|
|
102
|
+
|
|
103
|
+
Author: Information-technology Promotion Agency (IPA)
|
|
104
|
+
|
|
105
|
+
Source: https://moji.or.jp/mojikiban/mjlist/
|
|
106
|
+
|
|
107
|
+
License: CC BY-SA 2.1 JP
|
|
108
|
+
|
|
109
|
+
* MJ shrink conversion mappings (文字情報技術促進協議会: MJ縮退マップ)
|
|
110
|
+
|
|
111
|
+
Publisher: Character Information Technology Promotion Council (CITPC)
|
|
112
|
+
|
|
113
|
+
Author: Information-technology Promotion Agency (IPA)
|
|
114
|
+
|
|
115
|
+
Source: https://moji.or.jp/mojikiban/map/
|
|
116
|
+
|
|
117
|
+
License: CC BY-SA 2.1 JP
|
|
@@ -0,0 +1,107 @@
|
|
|
1
|
+
[build-system]
|
|
2
|
+
requires = [
|
|
3
|
+
"hatchling",
|
|
4
|
+
"hatch-cython>=0.5.0",
|
|
5
|
+
"hatch-vcs",
|
|
6
|
+
"Cython>=3.0.0",
|
|
7
|
+
]
|
|
8
|
+
build-backend = "hatchling.build"
|
|
9
|
+
|
|
10
|
+
[project]
|
|
11
|
+
name = "jntajis-python"
|
|
12
|
+
description = "A fast character conversion and transliteration library based on the scheme defined for Japan National Tax Agency's corporate number system."
|
|
13
|
+
readme = "README.md"
|
|
14
|
+
license = "BSD-3-Clause"
|
|
15
|
+
requires-python = ">= 3.10"
|
|
16
|
+
authors = [
|
|
17
|
+
{ name = "Open Collector, inc.", email = "info@opencollector.co.jp" },
|
|
18
|
+
]
|
|
19
|
+
keywords = ["Unicode", "JIS", "encoding", "conversion", "transliteration", "Japanese"]
|
|
20
|
+
classifiers = [
|
|
21
|
+
"Programming Language :: Python :: 3",
|
|
22
|
+
"Programming Language :: Python :: 3.10",
|
|
23
|
+
"Programming Language :: Python :: 3.11",
|
|
24
|
+
"Programming Language :: Python :: 3.12",
|
|
25
|
+
"Programming Language :: Python :: 3.13",
|
|
26
|
+
"Topic :: Text Processing :: Filters",
|
|
27
|
+
]
|
|
28
|
+
dynamic = ["version"]
|
|
29
|
+
|
|
30
|
+
[project.optional-dependencies]
|
|
31
|
+
dev = [
|
|
32
|
+
"click>=8.3",
|
|
33
|
+
"ruff>=0.4",
|
|
34
|
+
"jinja2>=3",
|
|
35
|
+
"mypy>=1.19",
|
|
36
|
+
"pytest>=6.2",
|
|
37
|
+
"sphinx>=4",
|
|
38
|
+
"sphinx-rtd-theme>=0.5",
|
|
39
|
+
]
|
|
40
|
+
|
|
41
|
+
[project.urls]
|
|
42
|
+
Homepage = "https://github.com/opencollector/jntajis-python"
|
|
43
|
+
|
|
44
|
+
[tool.hatch.version]
|
|
45
|
+
source = "vcs"
|
|
46
|
+
|
|
47
|
+
[tool.hatch.version.raw-options]
|
|
48
|
+
tag_regex = "^(?P<version>[vV]?\\d+(?:\\.\\d+){0,2}[^\\+]*)(?:\\+.*)?$"
|
|
49
|
+
|
|
50
|
+
[tool.hatch.build.targets.wheel]
|
|
51
|
+
packages = ["src/jntajis"]
|
|
52
|
+
|
|
53
|
+
[tool.hatch.build.targets.wheel.hooks.cython]
|
|
54
|
+
dependencies = ["hatch-cython>=0.5.0"]
|
|
55
|
+
|
|
56
|
+
[tool.hatch.build.targets.wheel.hooks.cython.options]
|
|
57
|
+
src = "jntajis"
|
|
58
|
+
includes = ["pythoncapi-compat", "src/jntajis"]
|
|
59
|
+
compile_py = false
|
|
60
|
+
directives = { language_level = 3, cdivision = true, boundscheck = false, wraparound = false, embedsignature = true }
|
|
61
|
+
|
|
62
|
+
[tool.hatch.build.targets.sdist]
|
|
63
|
+
include = [
|
|
64
|
+
"src/",
|
|
65
|
+
"docs/",
|
|
66
|
+
"README.md",
|
|
67
|
+
"LICENSE",
|
|
68
|
+
]
|
|
69
|
+
|
|
70
|
+
[tool.hatch.build.hooks.vcs]
|
|
71
|
+
version-file = "src/jntajis/_version.py"
|
|
72
|
+
|
|
73
|
+
[tool.ruff]
|
|
74
|
+
line-length = 99
|
|
75
|
+
target-version = "py310"
|
|
76
|
+
src = ["src"]
|
|
77
|
+
|
|
78
|
+
[tool.ruff.lint]
|
|
79
|
+
select = ["E", "F", "I", "W"]
|
|
80
|
+
ignore = ["E501"]
|
|
81
|
+
|
|
82
|
+
[tool.hatch.envs.lint]
|
|
83
|
+
features = ["dev"]
|
|
84
|
+
|
|
85
|
+
[tool.hatch.envs.lint.scripts]
|
|
86
|
+
fix = ["ruff format {args:src}", "ruff check --fix {args:src}"]
|
|
87
|
+
check = ["ruff format --check {args:src}", "ruff check {args:src}", "mypy -p jntajis"]
|
|
88
|
+
|
|
89
|
+
[tool.hatch.envs.wheels]
|
|
90
|
+
dependencies = ["cibuildwheel>=2"]
|
|
91
|
+
detached = true
|
|
92
|
+
|
|
93
|
+
[tool.hatch.envs.wheels.scripts]
|
|
94
|
+
build = ["cibuildwheel --output-dir {args:dist}"]
|
|
95
|
+
|
|
96
|
+
[[tool.hatch.envs.hatch-test.matrix]]
|
|
97
|
+
python = ["3.13", "3.12", "3.11", "3.10"]
|
|
98
|
+
|
|
99
|
+
[tool.mypy]
|
|
100
|
+
files = "src/"
|
|
101
|
+
|
|
102
|
+
[tool.cibuildwheel]
|
|
103
|
+
build = ["cp310-*", "cp311-*", "cp312-*", "cp313-*"]
|
|
104
|
+
# skip = "pp*"
|
|
105
|
+
|
|
106
|
+
[tool.cibuildwheel.macos]
|
|
107
|
+
archs = ["universal2"]
|
|
@@ -0,0 +1,20 @@
|
|
|
1
|
+
# Minimal makefile for Sphinx documentation
|
|
2
|
+
#
|
|
3
|
+
|
|
4
|
+
# You can set these variables from the command line, and also
|
|
5
|
+
# from the environment for the first two.
|
|
6
|
+
SPHINXOPTS ?=
|
|
7
|
+
SPHINXBUILD ?= sphinx-build
|
|
8
|
+
SOURCEDIR = .
|
|
9
|
+
BUILDDIR = build
|
|
10
|
+
|
|
11
|
+
# Put it first so that "make" without argument is like "make help".
|
|
12
|
+
help:
|
|
13
|
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
|
14
|
+
|
|
15
|
+
.PHONY: help Makefile
|
|
16
|
+
|
|
17
|
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
|
18
|
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
|
19
|
+
%: Makefile
|
|
20
|
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|