gsg 0.6.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- gsg-0.6.0/GSG/__init__.py +4 -0
- gsg-0.6.0/GSG/models/__init__.py +46 -0
- gsg-0.6.0/GSG/models/edcoder.py +197 -0
- gsg-0.6.0/GSG/models/gin.py +202 -0
- gsg-0.6.0/GSG/models/loss_func.py +11 -0
- gsg-0.6.0/GSG/models/utils.py +177 -0
- gsg-0.6.0/GSG/preprocess.py +183 -0
- gsg-0.6.0/GSG/train.py +21 -0
- gsg-0.6.0/GSG/utils.py +32 -0
- gsg-0.6.0/LICENSE.txt +21 -0
- gsg-0.6.0/PKG-INFO +64 -0
- gsg-0.6.0/README.md +54 -0
- gsg-0.6.0/gsg.egg-info/PKG-INFO +64 -0
- gsg-0.6.0/gsg.egg-info/SOURCES.txt +17 -0
- gsg-0.6.0/gsg.egg-info/dependency_links.txt +1 -0
- gsg-0.6.0/gsg.egg-info/requires.txt +10 -0
- gsg-0.6.0/gsg.egg-info/top_level.txt +1 -0
- gsg-0.6.0/pyproject.toml +31 -0
- gsg-0.6.0/setup.cfg +4 -0
|
@@ -0,0 +1,46 @@
|
|
|
1
|
+
from .edcoder import PreModel
|
|
2
|
+
|
|
3
|
+
#####################################################################################################################################
|
|
4
|
+
# Adapted from: #
|
|
5
|
+
# @inproceedings{hou2022graphmae, #
|
|
6
|
+
# title={GraphMAE: Self-Supervised Masked Graph Autoencoders}, #
|
|
7
|
+
# author={Hou, Zhenyu and Liu, Xiao and Cen, Yukuo and Dong, Yuxiao and Yang, Hongxia and Wang, Chunjie and Tang, Jie}, #
|
|
8
|
+
# booktitle={Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining}, #
|
|
9
|
+
# pages={594--604}, #
|
|
10
|
+
# year={2022} #
|
|
11
|
+
# } #
|
|
12
|
+
#####################################################################################################################################
|
|
13
|
+
|
|
14
|
+
def build_model(args):
|
|
15
|
+
num_hidden = args.num_hidden
|
|
16
|
+
num_layers = args.num_layers
|
|
17
|
+
in_drop = args.in_drop
|
|
18
|
+
norm = args.norm
|
|
19
|
+
encoder_type = "gin"
|
|
20
|
+
if args.imputation:
|
|
21
|
+
decoder_type = "mlp"
|
|
22
|
+
else:
|
|
23
|
+
decoder_type = 'gin'
|
|
24
|
+
mask_rate = args.mask_rate
|
|
25
|
+
replace_rate = args.replace_rate
|
|
26
|
+
|
|
27
|
+
|
|
28
|
+
activation = args.activation
|
|
29
|
+
alpha_l = args.alpha_l
|
|
30
|
+
num_features = args.num_features
|
|
31
|
+
|
|
32
|
+
|
|
33
|
+
model = PreModel(
|
|
34
|
+
in_dim=num_features,
|
|
35
|
+
num_hidden=num_hidden,
|
|
36
|
+
num_layers=num_layers,
|
|
37
|
+
activation=activation,
|
|
38
|
+
feat_drop=in_drop,
|
|
39
|
+
encoder_type=encoder_type,
|
|
40
|
+
decoder_type=decoder_type,
|
|
41
|
+
mask_rate=mask_rate,
|
|
42
|
+
norm=norm,
|
|
43
|
+
replace_rate=replace_rate,
|
|
44
|
+
alpha_l=alpha_l,
|
|
45
|
+
)
|
|
46
|
+
return model
|
|
@@ -0,0 +1,197 @@
|
|
|
1
|
+
from typing import Optional
|
|
2
|
+
from itertools import chain
|
|
3
|
+
from functools import partial
|
|
4
|
+
|
|
5
|
+
import torch
|
|
6
|
+
import torch.nn as nn
|
|
7
|
+
|
|
8
|
+
from .gin import GIN
|
|
9
|
+
from .loss_func import sce_loss
|
|
10
|
+
from .utils import drop_edge
|
|
11
|
+
|
|
12
|
+
|
|
13
|
+
def setup_module(m_type, enc_dec, in_dim, num_hidden, out_dim, num_layers, dropout, activation, residual, norm) -> nn.Module:
|
|
14
|
+
if m_type == "gin":
|
|
15
|
+
mod = GIN(
|
|
16
|
+
in_dim=in_dim,
|
|
17
|
+
num_hidden=num_hidden,
|
|
18
|
+
out_dim=out_dim,
|
|
19
|
+
num_layers=num_layers,
|
|
20
|
+
dropout=dropout,
|
|
21
|
+
activation=activation,
|
|
22
|
+
residual=residual,
|
|
23
|
+
norm=norm,
|
|
24
|
+
encoding=(enc_dec == "encoding"),
|
|
25
|
+
)
|
|
26
|
+
|
|
27
|
+
elif m_type == "mlp":
|
|
28
|
+
# * just for decoder
|
|
29
|
+
mod = nn.Sequential(
|
|
30
|
+
nn.Linear(in_dim, num_hidden),
|
|
31
|
+
nn.PReLU(),
|
|
32
|
+
nn.Dropout(0.2),
|
|
33
|
+
nn.Linear(num_hidden, out_dim)
|
|
34
|
+
)
|
|
35
|
+
elif m_type == "linear":
|
|
36
|
+
mod = nn.Linear(in_dim, out_dim)
|
|
37
|
+
else:
|
|
38
|
+
raise NotImplementedError
|
|
39
|
+
|
|
40
|
+
return mod
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
class PreModel(nn.Module):
|
|
44
|
+
def __init__(
|
|
45
|
+
self,
|
|
46
|
+
in_dim: int,
|
|
47
|
+
num_hidden: int,
|
|
48
|
+
num_layers: int,
|
|
49
|
+
activation: str,
|
|
50
|
+
feat_drop: float,
|
|
51
|
+
norm: Optional[str],
|
|
52
|
+
mask_rate: float = 0.3,
|
|
53
|
+
encoder_type: str = "gin",
|
|
54
|
+
decoder_type: str = "gin",
|
|
55
|
+
loss_fn: str = "sce",
|
|
56
|
+
drop_edge_rate: float = 0.0,
|
|
57
|
+
replace_rate: float = 0.1,
|
|
58
|
+
alpha_l: float = 2,
|
|
59
|
+
residual: bool = False,
|
|
60
|
+
concat_hidden: bool = False,
|
|
61
|
+
):
|
|
62
|
+
super(PreModel, self).__init__()
|
|
63
|
+
self._mask_rate = mask_rate
|
|
64
|
+
|
|
65
|
+
self._encoder_type = encoder_type
|
|
66
|
+
self._decoder_type = decoder_type
|
|
67
|
+
self._drop_edge_rate = drop_edge_rate
|
|
68
|
+
self._output_hidden_size = num_hidden
|
|
69
|
+
self._concat_hidden = concat_hidden
|
|
70
|
+
|
|
71
|
+
self._replace_rate = replace_rate
|
|
72
|
+
self._mask_token_rate = 1 - self._replace_rate
|
|
73
|
+
|
|
74
|
+
enc_num_hidden = num_hidden
|
|
75
|
+
dec_in_dim = num_hidden
|
|
76
|
+
dec_num_hidden = num_hidden
|
|
77
|
+
|
|
78
|
+
# build encoder
|
|
79
|
+
self.encoder = setup_module(
|
|
80
|
+
m_type=encoder_type,
|
|
81
|
+
enc_dec="encoding",
|
|
82
|
+
in_dim=in_dim,
|
|
83
|
+
num_hidden=enc_num_hidden,
|
|
84
|
+
out_dim=enc_num_hidden,
|
|
85
|
+
num_layers=num_layers,
|
|
86
|
+
activation=activation,
|
|
87
|
+
dropout=feat_drop,
|
|
88
|
+
residual=residual,
|
|
89
|
+
norm=norm,
|
|
90
|
+
)
|
|
91
|
+
|
|
92
|
+
# build decoder for attribute prediction
|
|
93
|
+
self.decoder = setup_module(
|
|
94
|
+
m_type=decoder_type,
|
|
95
|
+
enc_dec="decoding",
|
|
96
|
+
in_dim=dec_in_dim,
|
|
97
|
+
num_hidden=dec_num_hidden,
|
|
98
|
+
out_dim=in_dim,
|
|
99
|
+
num_layers=1,
|
|
100
|
+
activation=activation,
|
|
101
|
+
dropout=feat_drop,
|
|
102
|
+
residual=residual,
|
|
103
|
+
norm=norm,
|
|
104
|
+
)
|
|
105
|
+
|
|
106
|
+
self.enc_mask_token = nn.Parameter(torch.zeros(1, in_dim))
|
|
107
|
+
if concat_hidden:
|
|
108
|
+
self.encoder_to_decoder = nn.Linear(dec_in_dim * num_layers, dec_in_dim, bias=False)
|
|
109
|
+
else:
|
|
110
|
+
self.encoder_to_decoder = nn.Linear(dec_in_dim, dec_in_dim, bias=False)
|
|
111
|
+
|
|
112
|
+
# * setup loss function
|
|
113
|
+
self.criterion = partial(sce_loss, alpha=alpha_l)
|
|
114
|
+
|
|
115
|
+
@property
|
|
116
|
+
def output_hidden_dim(self):
|
|
117
|
+
return self._output_hidden_size
|
|
118
|
+
|
|
119
|
+
def encoding_mask_noise(self, g, x, mask_rate=0.3):
|
|
120
|
+
num_nodes = g.num_nodes()
|
|
121
|
+
perm = torch.randperm(num_nodes, device=x.device)
|
|
122
|
+
num_mask_nodes = int(mask_rate * num_nodes)
|
|
123
|
+
|
|
124
|
+
# random masking
|
|
125
|
+
num_mask_nodes = int(mask_rate * num_nodes)
|
|
126
|
+
mask_nodes = perm[: num_mask_nodes]
|
|
127
|
+
keep_nodes = perm[num_mask_nodes: ]
|
|
128
|
+
|
|
129
|
+
if self._replace_rate > 0:
|
|
130
|
+
num_noise_nodes = int(self._replace_rate * num_mask_nodes)
|
|
131
|
+
perm_mask = torch.randperm(num_mask_nodes, device=x.device)
|
|
132
|
+
token_nodes = mask_nodes[perm_mask[: int(self._mask_token_rate * num_mask_nodes)]]
|
|
133
|
+
noise_nodes = mask_nodes[perm_mask[-int(self._replace_rate * num_mask_nodes):]]
|
|
134
|
+
noise_to_be_chosen = torch.randperm(num_nodes, device=x.device)[:num_noise_nodes]
|
|
135
|
+
|
|
136
|
+
out_x = x.clone()
|
|
137
|
+
out_x[token_nodes] = 0.0
|
|
138
|
+
out_x[noise_nodes] = x[noise_to_be_chosen]
|
|
139
|
+
else:
|
|
140
|
+
out_x = x.clone()
|
|
141
|
+
token_nodes = mask_nodes
|
|
142
|
+
out_x[mask_nodes] = 0.0
|
|
143
|
+
|
|
144
|
+
out_x[token_nodes] += self.enc_mask_token
|
|
145
|
+
use_g = g.clone()
|
|
146
|
+
|
|
147
|
+
return use_g, out_x, (mask_nodes, keep_nodes)
|
|
148
|
+
|
|
149
|
+
def forward(self, g, x):
|
|
150
|
+
# ---- attribute reconstruction ----
|
|
151
|
+
loss = self.mask_attr_prediction(g, x)
|
|
152
|
+
loss_item = {"loss": loss.item()}
|
|
153
|
+
return loss, loss_item
|
|
154
|
+
|
|
155
|
+
def mask_attr_prediction(self, g, x, test=False):
|
|
156
|
+
pre_use_g, use_x, (mask_nodes, keep_nodes) = self.encoding_mask_noise(g, x, self._mask_rate)
|
|
157
|
+
|
|
158
|
+
if self._drop_edge_rate > 0:
|
|
159
|
+
use_g, masked_edges = drop_edge(pre_use_g, self._drop_edge_rate, return_edges=True)
|
|
160
|
+
else:
|
|
161
|
+
use_g = pre_use_g
|
|
162
|
+
|
|
163
|
+
enc_rep, all_hidden = self.encoder(use_g, use_x, return_hidden=True)
|
|
164
|
+
if self._concat_hidden:
|
|
165
|
+
enc_rep = torch.cat(all_hidden, dim=1)
|
|
166
|
+
|
|
167
|
+
# ---- attribute reconstruction ----
|
|
168
|
+
rep = self.encoder_to_decoder(enc_rep)
|
|
169
|
+
if self._decoder_type not in ("mlp", "linear"):
|
|
170
|
+
rep[mask_nodes] = 0
|
|
171
|
+
|
|
172
|
+
if self._decoder_type in ("mlp", "linear") :
|
|
173
|
+
recon = self.decoder(rep)
|
|
174
|
+
else:
|
|
175
|
+
recon = self.decoder(pre_use_g, rep)
|
|
176
|
+
|
|
177
|
+
x_init = x[mask_nodes]
|
|
178
|
+
x_rec = recon[mask_nodes]
|
|
179
|
+
# x_init = x
|
|
180
|
+
# x_rec = recon
|
|
181
|
+
|
|
182
|
+
if not test:
|
|
183
|
+
loss = self.criterion(x_rec, x_init)
|
|
184
|
+
return loss
|
|
185
|
+
return recon.detach().cpu().numpy()
|
|
186
|
+
|
|
187
|
+
def embed(self, g, x):
|
|
188
|
+
rep = self.encoder(g, x)
|
|
189
|
+
return rep
|
|
190
|
+
|
|
191
|
+
@property
|
|
192
|
+
def enc_params(self):
|
|
193
|
+
return self.encoder.parameters()
|
|
194
|
+
|
|
195
|
+
@property
|
|
196
|
+
def dec_params(self):
|
|
197
|
+
return chain(*[self.encoder_to_decoder.parameters(), self.decoder.parameters()])
|
|
@@ -0,0 +1,202 @@
|
|
|
1
|
+
import torch
|
|
2
|
+
import torch.nn as nn
|
|
3
|
+
import torch.nn.functional as F
|
|
4
|
+
import dgl.function as fn
|
|
5
|
+
from dgl.utils import expand_as_pair
|
|
6
|
+
|
|
7
|
+
from .utils import create_activation, create_norm
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
class GIN(nn.Module):
|
|
11
|
+
def __init__(self,
|
|
12
|
+
in_dim,
|
|
13
|
+
num_hidden,
|
|
14
|
+
out_dim,
|
|
15
|
+
num_layers,
|
|
16
|
+
dropout,
|
|
17
|
+
activation,
|
|
18
|
+
residual,
|
|
19
|
+
norm,
|
|
20
|
+
encoding=False,
|
|
21
|
+
learn_eps=False,
|
|
22
|
+
aggr="sum",
|
|
23
|
+
):
|
|
24
|
+
super(GIN, self).__init__()
|
|
25
|
+
self.out_dim = out_dim
|
|
26
|
+
self.num_layers = num_layers
|
|
27
|
+
self.layers = nn.ModuleList()
|
|
28
|
+
self.activation = activation
|
|
29
|
+
self.dropout = dropout
|
|
30
|
+
|
|
31
|
+
last_activation = create_activation(activation) if encoding else None
|
|
32
|
+
last_residual = encoding and residual
|
|
33
|
+
last_norm = norm if encoding else None
|
|
34
|
+
|
|
35
|
+
if num_layers == 1:
|
|
36
|
+
apply_func = MLP(2, in_dim, num_hidden, out_dim, activation=activation, norm=norm)
|
|
37
|
+
if last_norm:
|
|
38
|
+
apply_func = ApplyNodeFunc(apply_func, norm=norm, activation=activation)
|
|
39
|
+
self.layers.append(GINConv(in_dim, out_dim, apply_func, init_eps=0, learn_eps=learn_eps, residual=last_residual))
|
|
40
|
+
else:
|
|
41
|
+
# input projection (no residual)
|
|
42
|
+
self.layers.append(GINConv(
|
|
43
|
+
in_dim,
|
|
44
|
+
num_hidden,
|
|
45
|
+
ApplyNodeFunc(MLP(2, in_dim, num_hidden, num_hidden, activation=activation, norm=norm), activation=activation, norm=norm),
|
|
46
|
+
init_eps=0,
|
|
47
|
+
learn_eps=learn_eps,
|
|
48
|
+
residual=residual)
|
|
49
|
+
)
|
|
50
|
+
# hidden layers
|
|
51
|
+
for l in range(1, num_layers - 1):
|
|
52
|
+
# due to multi-head, the in_dim = num_hidden * num_heads
|
|
53
|
+
self.layers.append(GINConv(
|
|
54
|
+
num_hidden, num_hidden,
|
|
55
|
+
ApplyNodeFunc(MLP(2, num_hidden, num_hidden, num_hidden, activation=activation, norm=norm), activation=activation, norm=norm),
|
|
56
|
+
init_eps=0,
|
|
57
|
+
learn_eps=learn_eps,
|
|
58
|
+
residual=residual)
|
|
59
|
+
)
|
|
60
|
+
# output projection
|
|
61
|
+
apply_func = MLP(2, num_hidden, num_hidden, out_dim, activation=activation, norm=norm)
|
|
62
|
+
if last_norm:
|
|
63
|
+
apply_func = ApplyNodeFunc(apply_func, activation=activation, norm=norm)
|
|
64
|
+
|
|
65
|
+
self.layers.append(GINConv(num_hidden, out_dim, apply_func, init_eps=0, learn_eps=learn_eps, residual=last_residual))
|
|
66
|
+
|
|
67
|
+
self.head = nn.Identity()
|
|
68
|
+
|
|
69
|
+
def forward(self, g, inputs, return_hidden=False):
|
|
70
|
+
h = inputs
|
|
71
|
+
hidden_list = []
|
|
72
|
+
for l in range(self.num_layers):
|
|
73
|
+
h = F.dropout(h, p=self.dropout, training=self.training)
|
|
74
|
+
h = self.layers[l](g, h)
|
|
75
|
+
hidden_list.append(h)
|
|
76
|
+
# output projection
|
|
77
|
+
if return_hidden:
|
|
78
|
+
return self.head(h), hidden_list
|
|
79
|
+
else:
|
|
80
|
+
return self.head(h)
|
|
81
|
+
|
|
82
|
+
def reset_classifier(self, num_classes):
|
|
83
|
+
self.head = nn.Linear(self.out_dim, num_classes)
|
|
84
|
+
|
|
85
|
+
|
|
86
|
+
class GINConv(nn.Module):
|
|
87
|
+
def __init__(self,
|
|
88
|
+
in_dim,
|
|
89
|
+
out_dim,
|
|
90
|
+
apply_func,
|
|
91
|
+
aggregator_type="sum",
|
|
92
|
+
init_eps=0,
|
|
93
|
+
learn_eps=False,
|
|
94
|
+
residual=False,
|
|
95
|
+
):
|
|
96
|
+
super().__init__()
|
|
97
|
+
self._in_feats = in_dim
|
|
98
|
+
self._out_feats = out_dim
|
|
99
|
+
self.apply_func = apply_func
|
|
100
|
+
|
|
101
|
+
self._aggregator_type = aggregator_type
|
|
102
|
+
if aggregator_type == 'sum':
|
|
103
|
+
self._reducer = fn.sum
|
|
104
|
+
elif aggregator_type == 'max':
|
|
105
|
+
self._reducer = fn.max
|
|
106
|
+
elif aggregator_type == 'mean':
|
|
107
|
+
self._reducer = fn.mean
|
|
108
|
+
else:
|
|
109
|
+
raise KeyError('Aggregator type {} not recognized.'.format(aggregator_type))
|
|
110
|
+
|
|
111
|
+
if learn_eps:
|
|
112
|
+
self.eps = torch.nn.Parameter(torch.FloatTensor([init_eps]))
|
|
113
|
+
else:
|
|
114
|
+
self.register_buffer('eps', torch.FloatTensor([init_eps]))
|
|
115
|
+
|
|
116
|
+
if residual:
|
|
117
|
+
if self._in_feats != self._out_feats:
|
|
118
|
+
self.res_fc = nn.Linear(
|
|
119
|
+
self._in_feats, self._out_feats, bias=False)
|
|
120
|
+
print("! Linear Residual !")
|
|
121
|
+
else:
|
|
122
|
+
print("Identity Residual ")
|
|
123
|
+
self.res_fc = nn.Identity()
|
|
124
|
+
else:
|
|
125
|
+
self.register_buffer('res_fc', None)
|
|
126
|
+
|
|
127
|
+
def forward(self, graph, feat):
|
|
128
|
+
with graph.local_scope():
|
|
129
|
+
aggregate_fn = fn.copy_src('h', 'm')
|
|
130
|
+
|
|
131
|
+
feat_src, feat_dst = expand_as_pair(feat, graph)
|
|
132
|
+
graph.srcdata['h'] = feat_src
|
|
133
|
+
graph.update_all(aggregate_fn, self._reducer('m', 'neigh'))
|
|
134
|
+
rst = (1 + self.eps) * feat_dst + graph.dstdata['neigh']
|
|
135
|
+
if self.apply_func is not None:
|
|
136
|
+
rst = self.apply_func(rst)
|
|
137
|
+
|
|
138
|
+
if self.res_fc is not None:
|
|
139
|
+
rst = rst + self.res_fc(feat_dst)
|
|
140
|
+
|
|
141
|
+
return rst
|
|
142
|
+
|
|
143
|
+
|
|
144
|
+
class ApplyNodeFunc(nn.Module):
|
|
145
|
+
"""Update the node feature hv with MLP, BN and ReLU."""
|
|
146
|
+
def __init__(self, mlp, norm="batchnorm", activation="relu"):
|
|
147
|
+
super(ApplyNodeFunc, self).__init__()
|
|
148
|
+
self.mlp = mlp
|
|
149
|
+
norm_func = create_norm(norm)
|
|
150
|
+
if norm_func is None:
|
|
151
|
+
self.norm = nn.Identity()
|
|
152
|
+
else:
|
|
153
|
+
self.norm = norm_func(self.mlp.output_dim)
|
|
154
|
+
self.act = create_activation(activation)
|
|
155
|
+
|
|
156
|
+
def forward(self, h):
|
|
157
|
+
h = self.mlp(h)
|
|
158
|
+
h = self.norm(h)
|
|
159
|
+
h = self.act(h)
|
|
160
|
+
return h
|
|
161
|
+
|
|
162
|
+
|
|
163
|
+
class MLP(nn.Module):
|
|
164
|
+
"""MLP with linear output"""
|
|
165
|
+
def __init__(self, num_layers, input_dim, hidden_dim, output_dim, activation="relu", norm="batchnorm"):
|
|
166
|
+
super(MLP, self).__init__()
|
|
167
|
+
self.linear_or_not = True # default is linear model
|
|
168
|
+
self.num_layers = num_layers
|
|
169
|
+
self.output_dim = output_dim
|
|
170
|
+
|
|
171
|
+
if num_layers < 1:
|
|
172
|
+
raise ValueError("number of layers should be positive!")
|
|
173
|
+
elif num_layers == 1:
|
|
174
|
+
# Linear model
|
|
175
|
+
self.linear = nn.Linear(input_dim, output_dim)
|
|
176
|
+
else:
|
|
177
|
+
# Multi-layer model
|
|
178
|
+
self.linear_or_not = False
|
|
179
|
+
self.linears = torch.nn.ModuleList()
|
|
180
|
+
self.norms = torch.nn.ModuleList()
|
|
181
|
+
self.activations = torch.nn.ModuleList()
|
|
182
|
+
|
|
183
|
+
self.linears.append(nn.Linear(input_dim, hidden_dim))
|
|
184
|
+
for layer in range(num_layers - 2):
|
|
185
|
+
self.linears.append(nn.Linear(hidden_dim, hidden_dim))
|
|
186
|
+
self.linears.append(nn.Linear(hidden_dim, output_dim))
|
|
187
|
+
|
|
188
|
+
for layer in range(num_layers - 1):
|
|
189
|
+
self.norms.append(create_norm(norm)(hidden_dim))
|
|
190
|
+
self.activations.append(create_activation(activation))
|
|
191
|
+
|
|
192
|
+
def forward(self, x):
|
|
193
|
+
if self.linear_or_not:
|
|
194
|
+
# If linear model
|
|
195
|
+
return self.linear(x)
|
|
196
|
+
else:
|
|
197
|
+
# If MLP
|
|
198
|
+
h = x
|
|
199
|
+
for i in range(self.num_layers - 1):
|
|
200
|
+
h = self.norms[i](self.linears[i](h))
|
|
201
|
+
h = self.activations[i](h)
|
|
202
|
+
return self.linears[-1](h)
|
|
@@ -0,0 +1,177 @@
|
|
|
1
|
+
import random
|
|
2
|
+
import logging
|
|
3
|
+
|
|
4
|
+
import dgl
|
|
5
|
+
import torch
|
|
6
|
+
import numpy as np
|
|
7
|
+
import torch.nn as nn
|
|
8
|
+
from tqdm import tqdm
|
|
9
|
+
from functools import partial
|
|
10
|
+
from torch import optim as optim
|
|
11
|
+
|
|
12
|
+
|
|
13
|
+
|
|
14
|
+
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(message)s", level=logging.INFO)
|
|
15
|
+
|
|
16
|
+
def accuracy(y_pred, y_true):
|
|
17
|
+
y_true = y_true.squeeze().long()
|
|
18
|
+
preds = y_pred.max(1)[1].type_as(y_true)
|
|
19
|
+
correct = preds.eq(y_true).double()
|
|
20
|
+
correct = correct.sum().item()
|
|
21
|
+
return correct / len(y_true)
|
|
22
|
+
|
|
23
|
+
|
|
24
|
+
def set_random_seed(seed):
|
|
25
|
+
random.seed(seed)
|
|
26
|
+
np.random.seed(seed)
|
|
27
|
+
torch.manual_seed(seed)
|
|
28
|
+
torch.cuda.manual_seed(seed)
|
|
29
|
+
torch.cuda.manual_seed_all(seed)
|
|
30
|
+
torch.backends.cudnn.determinstic = True
|
|
31
|
+
|
|
32
|
+
|
|
33
|
+
def get_current_lr(optimizer):
|
|
34
|
+
return optimizer.state_dict()["param_groups"][0]["lr"]
|
|
35
|
+
|
|
36
|
+
|
|
37
|
+
def create_activation(name):
|
|
38
|
+
if name == "relu":
|
|
39
|
+
return nn.ReLU()
|
|
40
|
+
elif name == "gelu":
|
|
41
|
+
return nn.GELU()
|
|
42
|
+
elif name == "prelu":
|
|
43
|
+
return nn.PReLU()
|
|
44
|
+
elif name is None:
|
|
45
|
+
return nn.Identity()
|
|
46
|
+
elif name == "elu":
|
|
47
|
+
return nn.ELU()
|
|
48
|
+
else:
|
|
49
|
+
raise NotImplementedError(f"{name} is not implemented.")
|
|
50
|
+
|
|
51
|
+
|
|
52
|
+
def create_norm(name):
|
|
53
|
+
if name == "layernorm":
|
|
54
|
+
return nn.LayerNorm
|
|
55
|
+
elif name == "batchnorm":
|
|
56
|
+
return nn.BatchNorm1d
|
|
57
|
+
elif name == "graphnorm":
|
|
58
|
+
return partial(NormLayer, norm_type="groupnorm")
|
|
59
|
+
else:
|
|
60
|
+
return None
|
|
61
|
+
|
|
62
|
+
|
|
63
|
+
def create_optimizer(opt, model, lr, weight_decay, get_num_layer=None, get_layer_scale=None):
|
|
64
|
+
opt_lower = opt.lower()
|
|
65
|
+
|
|
66
|
+
parameters = model.parameters()
|
|
67
|
+
opt_args = dict(lr=lr, weight_decay=weight_decay)
|
|
68
|
+
|
|
69
|
+
opt_split = opt_lower.split("_")
|
|
70
|
+
opt_lower = opt_split[-1]
|
|
71
|
+
if opt_lower == "adam":
|
|
72
|
+
optimizer = optim.Adam(parameters, **opt_args)
|
|
73
|
+
elif opt_lower == "adamw":
|
|
74
|
+
optimizer = optim.AdamW(parameters, **opt_args)
|
|
75
|
+
elif opt_lower == "adadelta":
|
|
76
|
+
optimizer = optim.Adadelta(parameters, **opt_args)
|
|
77
|
+
elif opt_lower == "radam":
|
|
78
|
+
optimizer = optim.RAdam(parameters, **opt_args)
|
|
79
|
+
elif opt_lower == "sgd":
|
|
80
|
+
opt_args["momentum"] = 0.9
|
|
81
|
+
return optim.SGD(parameters, **opt_args)
|
|
82
|
+
else:
|
|
83
|
+
assert False and "Invalid optimizer"
|
|
84
|
+
|
|
85
|
+
return optimizer
|
|
86
|
+
|
|
87
|
+
|
|
88
|
+
# -------------------
|
|
89
|
+
def pretrain(model, graph, feat, optimizer, max_epoch, device):
|
|
90
|
+
logging.info("start training..")
|
|
91
|
+
graph = graph.to(device)
|
|
92
|
+
x = feat.to(device)
|
|
93
|
+
|
|
94
|
+
epoch_iter = tqdm(range(max_epoch))
|
|
95
|
+
for epoch in epoch_iter:
|
|
96
|
+
model.train()
|
|
97
|
+
|
|
98
|
+
loss, loss_dict = model(graph, x)
|
|
99
|
+
|
|
100
|
+
optimizer.zero_grad()
|
|
101
|
+
loss.backward()
|
|
102
|
+
optimizer.step()
|
|
103
|
+
|
|
104
|
+
epoch_iter.set_description(f"# Epoch {epoch}: train_loss: {loss.item():.4f}")
|
|
105
|
+
return model
|
|
106
|
+
|
|
107
|
+
|
|
108
|
+
def mask_edge(graph, mask_prob):
|
|
109
|
+
E = graph.num_edges()
|
|
110
|
+
|
|
111
|
+
mask_rates = torch.FloatTensor(np.ones(E) * mask_prob)
|
|
112
|
+
masks = torch.bernoulli(1 - mask_rates)
|
|
113
|
+
mask_idx = masks.nonzero().squeeze(1)
|
|
114
|
+
return mask_idx
|
|
115
|
+
|
|
116
|
+
|
|
117
|
+
def drop_edge(graph, drop_rate, return_edges=False):
|
|
118
|
+
if drop_rate <= 0:
|
|
119
|
+
return graph
|
|
120
|
+
|
|
121
|
+
n_node = graph.num_nodes()
|
|
122
|
+
edge_mask = mask_edge(graph, drop_rate)
|
|
123
|
+
src = graph.edges()[0]
|
|
124
|
+
dst = graph.edges()[1]
|
|
125
|
+
|
|
126
|
+
nsrc = src[edge_mask]
|
|
127
|
+
ndst = dst[edge_mask]
|
|
128
|
+
|
|
129
|
+
ng = dgl.graph((nsrc, ndst), num_nodes=n_node)
|
|
130
|
+
ng = ng.add_self_loop()
|
|
131
|
+
|
|
132
|
+
dsrc = src[~edge_mask]
|
|
133
|
+
ddst = dst[~edge_mask]
|
|
134
|
+
|
|
135
|
+
if return_edges:
|
|
136
|
+
return ng, (dsrc, ddst)
|
|
137
|
+
return ng
|
|
138
|
+
|
|
139
|
+
|
|
140
|
+
|
|
141
|
+
class NormLayer(nn.Module):
|
|
142
|
+
def __init__(self, hidden_dim, norm_type):
|
|
143
|
+
super().__init__()
|
|
144
|
+
if norm_type == "batchnorm":
|
|
145
|
+
self.norm = nn.BatchNorm1d(hidden_dim)
|
|
146
|
+
elif norm_type == "layernorm":
|
|
147
|
+
self.norm = nn.LayerNorm(hidden_dim)
|
|
148
|
+
elif norm_type == "graphnorm":
|
|
149
|
+
self.norm = norm_type
|
|
150
|
+
self.weight = nn.Parameter(torch.ones(hidden_dim))
|
|
151
|
+
self.bias = nn.Parameter(torch.zeros(hidden_dim))
|
|
152
|
+
|
|
153
|
+
self.mean_scale = nn.Parameter(torch.ones(hidden_dim))
|
|
154
|
+
else:
|
|
155
|
+
raise NotImplementedError
|
|
156
|
+
|
|
157
|
+
def forward(self, graph, x):
|
|
158
|
+
tensor = x
|
|
159
|
+
if self.norm is not None and type(self.norm) != str:
|
|
160
|
+
return self.norm(tensor)
|
|
161
|
+
elif self.norm is None:
|
|
162
|
+
return tensor
|
|
163
|
+
batch_list = graph.batch_num_nodes
|
|
164
|
+
batch_size = len(batch_list)
|
|
165
|
+
batch_list = torch.Tensor(batch_list).long().to(tensor.device)
|
|
166
|
+
batch_index = torch.arange(batch_size).to(tensor.device).repeat_interleave(batch_list)
|
|
167
|
+
batch_index = batch_index.view((-1,) + (1,) * (tensor.dim() - 1)).expand_as(tensor)
|
|
168
|
+
mean = torch.zeros(batch_size, *tensor.shape[1:]).to(tensor.device)
|
|
169
|
+
mean = mean.scatter_add_(0, batch_index, tensor)
|
|
170
|
+
mean = (mean.T / batch_list).T
|
|
171
|
+
mean = mean.repeat_interleave(batch_list, dim=0)
|
|
172
|
+
sub = tensor - mean * self.mean_scale
|
|
173
|
+
std = torch.zeros(batch_size, *tensor.shape[1:]).to(tensor.device)
|
|
174
|
+
std = std.scatter_add_(0, batch_index, sub.pow(2))
|
|
175
|
+
std = ((std.T / batch_list).T + 1e-6).sqrt()
|
|
176
|
+
std = std.repeat_interleave(batch_list, dim=0)
|
|
177
|
+
return self.weight * sub / std + self.bias
|
|
@@ -0,0 +1,183 @@
|
|
|
1
|
+
import os
|
|
2
|
+
import warnings
|
|
3
|
+
import itertools
|
|
4
|
+
warnings.filterwarnings("ignore")
|
|
5
|
+
|
|
6
|
+
import dgl
|
|
7
|
+
import torch
|
|
8
|
+
import anndata as ad
|
|
9
|
+
import scanpy as sc
|
|
10
|
+
import pandas as pd
|
|
11
|
+
import numpy as np
|
|
12
|
+
import matplotlib.pyplot as plt
|
|
13
|
+
from tqdm import tqdm
|
|
14
|
+
from scipy import sparse
|
|
15
|
+
from sklearn.cluster import KMeans
|
|
16
|
+
from sklearn.neighbors import BallTree
|
|
17
|
+
from scipy.spatial.distance import pdist, squareform
|
|
18
|
+
|
|
19
|
+
from . import utils
|
|
20
|
+
|
|
21
|
+
|
|
22
|
+
def read_10X_Visium(path,
|
|
23
|
+
genome=None,
|
|
24
|
+
count_file='filtered_feature_bc_matrix.h5',
|
|
25
|
+
library_id=None,
|
|
26
|
+
load_images=True,
|
|
27
|
+
quality='hires',
|
|
28
|
+
image_path = None):
|
|
29
|
+
adata = sc.read_visium(path,
|
|
30
|
+
genome=genome,
|
|
31
|
+
count_file=count_file,
|
|
32
|
+
library_id=library_id,
|
|
33
|
+
load_images=load_images,)
|
|
34
|
+
adata.var_names_make_unique()
|
|
35
|
+
if library_id is None:
|
|
36
|
+
library_id = list(adata.uns["spatial"].keys())[0]
|
|
37
|
+
if quality == "fulres":
|
|
38
|
+
image_coor = adata.obsm["spatial"]
|
|
39
|
+
img = plt.imread(image_path, 0)
|
|
40
|
+
adata.uns["spatial"][library_id]["images"]["fulres"] = img
|
|
41
|
+
else:
|
|
42
|
+
scale = adata.uns["spatial"][library_id]["scalefactors"][
|
|
43
|
+
"tissue_" + quality + "_scalef"]
|
|
44
|
+
image_coor = adata.obsm["spatial"] * scale
|
|
45
|
+
adata.obs["imagecol"] = image_coor[:, 0]
|
|
46
|
+
adata.obs["imagerow"] = image_coor[:, 1]
|
|
47
|
+
adata.uns["spatial"][library_id]["use_quality"] = quality
|
|
48
|
+
return adata
|
|
49
|
+
|
|
50
|
+
def read_10X_Visium_with_label(path,
|
|
51
|
+
genome=None,
|
|
52
|
+
count_file='filtered_feature_bc_matrix.h5',
|
|
53
|
+
library_id=None,
|
|
54
|
+
load_images=True,
|
|
55
|
+
quality='hires',
|
|
56
|
+
image_path = None):
|
|
57
|
+
adata = sc.read_visium(path,
|
|
58
|
+
genome=genome,
|
|
59
|
+
count_file=count_file,
|
|
60
|
+
library_id=library_id,
|
|
61
|
+
load_images=load_images,)
|
|
62
|
+
adata.var_names_make_unique()
|
|
63
|
+
if library_id is None:
|
|
64
|
+
library_id = list(adata.uns["spatial"].keys())[0]
|
|
65
|
+
if quality == "fulres":
|
|
66
|
+
image_coor = adata.obsm["spatial"]
|
|
67
|
+
img = plt.imread(image_path, 0)
|
|
68
|
+
adata.uns["spatial"][library_id]["images"]["fulres"] = img
|
|
69
|
+
else:
|
|
70
|
+
scale = adata.uns["spatial"][library_id]["scalefactors"][
|
|
71
|
+
"tissue_" + quality + "_scalef"]
|
|
72
|
+
image_coor = adata.obsm["spatial"] * scale
|
|
73
|
+
if(os.path.exists(path + "/metadata.tsv")):
|
|
74
|
+
adata.obs = pd.read_table(path + "/metadata.tsv",sep="\t",index_col=0)
|
|
75
|
+
adata.obs["imagecol"] = image_coor[:, 0]
|
|
76
|
+
adata.obs["imagerow"] = image_coor[:, 1]
|
|
77
|
+
adata.uns["spatial"][library_id]["use_quality"] = quality
|
|
78
|
+
return adata
|
|
79
|
+
|
|
80
|
+
|
|
81
|
+
def read_stereo_seq(counts_data_path, position_path):
|
|
82
|
+
counts_file = os.path.join(counts_data_path)
|
|
83
|
+
coor_file = os.path.join(position_path)
|
|
84
|
+
coor_df = pd.read_csv(coor_file, sep='\t')
|
|
85
|
+
counts = pd.read_csv(counts_file, sep='\t', index_col=0)
|
|
86
|
+
counts.columns = ['Spot_' + str(x) for x in counts.columns]
|
|
87
|
+
coor_df.index = coor_df['label'].map(lambda x: 'Spot_' + str(x))
|
|
88
|
+
adata = sc.AnnData(counts.T)
|
|
89
|
+
adata.obs = coor_df
|
|
90
|
+
adata.var_names_make_unique()
|
|
91
|
+
coor_df = coor_df.loc[adata.obs_names, ['y', 'x']]
|
|
92
|
+
adata.obsm["spatial"] = coor_df.to_numpy()
|
|
93
|
+
sc.pp.calculate_qc_metrics(adata, inplace=True)
|
|
94
|
+
adata.obs['imagecol'] = coor_df.iloc[:, 1]
|
|
95
|
+
adata.obs['imagerow'] = coor_df.iloc[:, 0]
|
|
96
|
+
return adata
|
|
97
|
+
|
|
98
|
+
def read_slide_seq(path,
|
|
99
|
+
library_id=None,
|
|
100
|
+
scale=None,
|
|
101
|
+
quality="hires",
|
|
102
|
+
spot_diameter_fullres=50,
|
|
103
|
+
background_color="white",):
|
|
104
|
+
count = pd.read_csv(os.path.join(path, "count_matrix.count"))
|
|
105
|
+
meta = pd.read_csv(os.path.join(path, "spatial.idx"))
|
|
106
|
+
adata = AnnData(count.iloc[:, 1:].set_index("gene").T)
|
|
107
|
+
adata.var["ENSEMBL"] = count["ENSEMBL"].values
|
|
108
|
+
adata.obs["index"] = meta["index"].values
|
|
109
|
+
if scale == None:
|
|
110
|
+
max_coor = np.max(meta[["x", "y"]].values)
|
|
111
|
+
scale = 2000 / max_coor
|
|
112
|
+
adata.obs["imagecol"] = meta["x"].values * scale
|
|
113
|
+
adata.obs["imagerow"] = meta["y"].values * scale
|
|
114
|
+
# Create image
|
|
115
|
+
max_size = np.max([adata.obs["imagecol"].max(), adata.obs["imagerow"].max()])
|
|
116
|
+
max_size = int(max_size + 0.1 * max_size)
|
|
117
|
+
if background_color == "black":
|
|
118
|
+
image = Image.new("RGBA", (max_size, max_size), (0, 0, 0, 0))
|
|
119
|
+
else:
|
|
120
|
+
image = Image.new("RGBA", (max_size, max_size), (255, 255, 255, 255))
|
|
121
|
+
imgarr = np.array(image)
|
|
122
|
+
if library_id is None:
|
|
123
|
+
library_id = "Slide-seq"
|
|
124
|
+
adata.uns["spatial"] = {}
|
|
125
|
+
adata.uns["spatial"][library_id] = {}
|
|
126
|
+
adata.uns["spatial"][library_id]["images"] = {}
|
|
127
|
+
adata.uns["spatial"][library_id]["images"][quality] = imgarr
|
|
128
|
+
adata.uns["spatial"][library_id]["use_quality"] = quality
|
|
129
|
+
adata.uns["spatial"][library_id]["scalefactors"] = {}
|
|
130
|
+
adata.uns["spatial"][library_id]["scalefactors"][
|
|
131
|
+
"tissue_" + quality + "_scalef"] = scale
|
|
132
|
+
adata.uns["spatial"][library_id]["scalefactors"][
|
|
133
|
+
"spot_diameter_fullres"
|
|
134
|
+
] = spot_diameter_fullres
|
|
135
|
+
adata.obsm["spatial"] = meta[["x", "y"]].values
|
|
136
|
+
return adata
|
|
137
|
+
|
|
138
|
+
|
|
139
|
+
def Graph_10X(adata, args):
|
|
140
|
+
cell_loc = adata.obs[["imagerow", "imagecol"]].values
|
|
141
|
+
if args.graph == 'radius':
|
|
142
|
+
distance_np = pdist(cell_loc, metric = "euclidean")
|
|
143
|
+
distance_np_X = squareform(distance_np)
|
|
144
|
+
threshold = args.threshold_radius
|
|
145
|
+
num_big = np.where((0< distance_np_X)&(distance_np_X < threshold))[0].shape[0]
|
|
146
|
+
adj_matrix = np.zeros(distance_np_X.shape)
|
|
147
|
+
non_zero_point = np.where((0< distance_np_X)&(distance_np_X<threshold))
|
|
148
|
+
for i in tqdm(range(num_big)):
|
|
149
|
+
x = non_zero_point[0][i]
|
|
150
|
+
y = non_zero_point[1][i]
|
|
151
|
+
adj_matrix[x][y] = 1
|
|
152
|
+
adj_matrix = adj_matrix + np.eye(distance_np_X.shape[0])
|
|
153
|
+
adj_matrix = np.float32(adj_matrix)
|
|
154
|
+
adj_matrix_crs = sparse.csr_matrix(adj_matrix)
|
|
155
|
+
elif args.graph == 'knn':
|
|
156
|
+
tree = BallTree(cell_loc)
|
|
157
|
+
distances, tail_list = tree.query(cell_loc, k=args.num_neighbors)
|
|
158
|
+
head_list = []
|
|
159
|
+
head_list = [head_list + [i] * len(tail_list[i]) for i in range(len(tail_list))]
|
|
160
|
+
head_list = list(itertools.chain.from_iterable(head_list))
|
|
161
|
+
tail_list = list(itertools.chain.from_iterable(tail_list))
|
|
162
|
+
distances = np.ones_like(head_list)
|
|
163
|
+
adj_matrix_crs = sparse.coo_matrix((distances, (head_list, tail_list)), shape=(cell_loc.shape[0], cell_loc.shape[0])).tocsr()
|
|
164
|
+
graph = dgl.from_scipy(adj_matrix_crs, eweight_name='w')
|
|
165
|
+
|
|
166
|
+
adata.var_names=[i.upper() for i in list(adata.var_names)]
|
|
167
|
+
adata.var["genename"] = adata.var.index.astype("str")
|
|
168
|
+
adata.var_names_make_unique()
|
|
169
|
+
if(args.feature_dim_method == "PCA"):
|
|
170
|
+
sc.pp.filter_genes(adata, min_cells=5)
|
|
171
|
+
adata_X = sc.pp.normalize_total(adata, target_sum=1, exclude_highly_expressed=True, inplace=False)['X']
|
|
172
|
+
adata_X = sc.pp.scale(adata_X)
|
|
173
|
+
adata_X = sc.pp.pca(adata_X, n_comps=args.num_features)
|
|
174
|
+
else:
|
|
175
|
+
sc.pp.filter_genes(adata, min_cells=5)
|
|
176
|
+
sc.pp.highly_variable_genes(adata, flavor="seurat_v3", n_top_genes=args.num_features)
|
|
177
|
+
sc.pp.normalize_total(adata, target_sum=1e4)
|
|
178
|
+
sc.pp.log1p(adata)
|
|
179
|
+
adata_Vars = adata[:, adata.var['highly_variable']]
|
|
180
|
+
adata_X = adata_Vars.X.todense()
|
|
181
|
+
graph.ndata["feat"] = torch.tensor(adata_X.copy())
|
|
182
|
+
return adata,graph
|
|
183
|
+
|
gsg-0.6.0/GSG/train.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
from . import models
|
|
2
|
+
from . import utils
|
|
3
|
+
|
|
4
|
+
def GSG_train(adata, graph, args):
|
|
5
|
+
device = args.device if args.device >= 0 else "cpu"
|
|
6
|
+
utils.set_random_seed(args.seeds)
|
|
7
|
+
model = models.build_model(args)
|
|
8
|
+
model.to(device)
|
|
9
|
+
optimizer = models.utils.create_optimizer(args.optimizer, model, args.lr, args.weight_decay)
|
|
10
|
+
x = graph.ndata["feat"]
|
|
11
|
+
if not args.load_model:
|
|
12
|
+
model = models.utils.pretrain(model, graph, x, optimizer, args.max_epoch, device)
|
|
13
|
+
model.train(False)
|
|
14
|
+
x = graph.ndata["feat"]
|
|
15
|
+
embedding = model.embed(graph.to(device), x.to(device))
|
|
16
|
+
adata.obsm["GSG_embedding"] = embedding.cpu().detach().numpy()
|
|
17
|
+
if args.imputation:
|
|
18
|
+
latten_embedding = model.encoder_to_decoder(embedding)
|
|
19
|
+
imputation_embedding = model.decoder(graph.to(device),latten_embedding)
|
|
20
|
+
adata.obsm["GSG_imputation"] = imputation_embedding.cpu().detach().numpy()
|
|
21
|
+
return adata, model
|
gsg-0.6.0/GSG/utils.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
1
|
+
import os
|
|
2
|
+
import random
|
|
3
|
+
|
|
4
|
+
import torch
|
|
5
|
+
import numpy as np
|
|
6
|
+
from scipy import sparse
|
|
7
|
+
from sklearn.cluster import KMeans
|
|
8
|
+
|
|
9
|
+
def mkdir(path):
|
|
10
|
+
folder = os.path.exists(path)
|
|
11
|
+
if not folder:
|
|
12
|
+
os.makedirs(path)
|
|
13
|
+
print("--- new folder... ---")
|
|
14
|
+
print("--- OK ---")
|
|
15
|
+
else:
|
|
16
|
+
print("--- There is this folder! ---")
|
|
17
|
+
|
|
18
|
+
def KMeans_use(embedding,cluster_number):
|
|
19
|
+
kmeans = KMeans(n_clusters=cluster_number,
|
|
20
|
+
init="k-means++",
|
|
21
|
+
random_state=0)
|
|
22
|
+
pred = kmeans.fit_predict(embedding)
|
|
23
|
+
return pred
|
|
24
|
+
|
|
25
|
+
|
|
26
|
+
def set_random_seed(seed):
|
|
27
|
+
random.seed(seed)
|
|
28
|
+
np.random.seed(seed)
|
|
29
|
+
torch.manual_seed(seed)
|
|
30
|
+
torch.cuda.manual_seed(seed)
|
|
31
|
+
torch.cuda.manual_seed_all(seed)
|
|
32
|
+
torch.backends.cudnn.determinstic = True
|
gsg-0.6.0/LICENSE.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2023 keaml-Guan
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
gsg-0.6.0/PKG-INFO
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
1
|
+
Metadata-Version: 2.1
|
|
2
|
+
Name: gsg
|
|
3
|
+
Version: 0.6.0
|
|
4
|
+
Summary: GSG: A generative self-supervised graph learning framework for spatial transcriptomics
|
|
5
|
+
Author-email: Chuyao Wang <chuyao25@mails.jlu.edu.cn>
|
|
6
|
+
License: MIT
|
|
7
|
+
Requires-Python: >=3.7
|
|
8
|
+
Description-Content-Type: text/markdown
|
|
9
|
+
License-File: LICENSE.txt
|
|
10
|
+
|
|
11
|
+
# A masked generative graph representation learning framework empowering precise spatial domain identification
|
|
12
|
+
  
|
|
13
|
+
#
|
|
14
|
+
|
|
15
|
+
<br>
|
|
16
|
+
|
|
17
|
+
## ✨ Overview
|
|
18
|
+
|
|
19
|
+
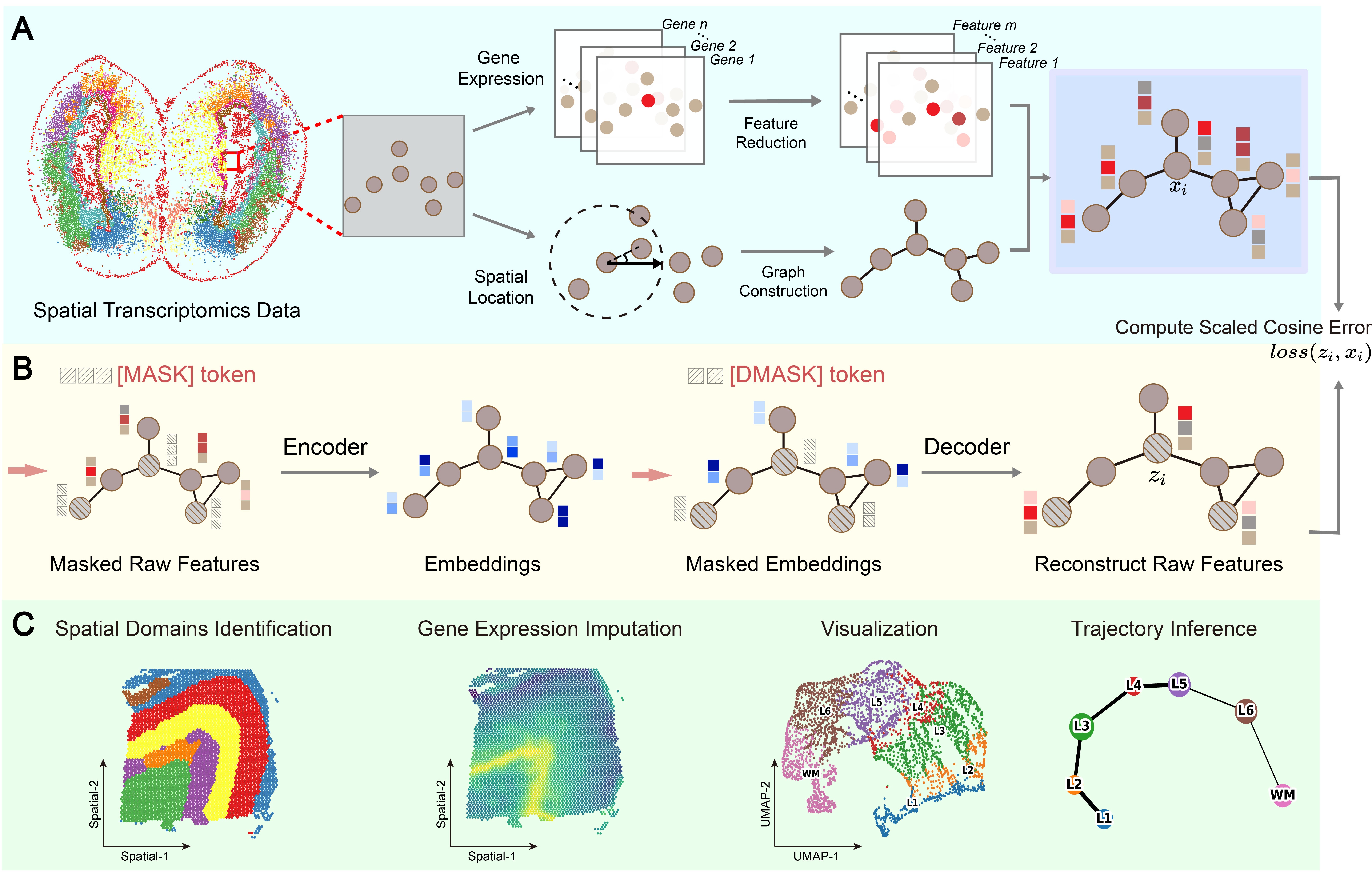
Recent advances in spatial transcriptomics (ST) have opened new avenues for preserving spatial information while measuring gene expression. Yet, the challenge of seamlessly integrating this data into accurate and transferable representation remains. Here, we introduce a generative self-supervised graph (GSG) learning framework to achieve an effective joint embedding of location and gene expression within ST data. Our approach surpasses existing methods in identifying spatial domains within the human dorsolateral prefrontal cortex. Moreover, it can offer reliable analyses across various techniques, including Stereo-seq, Slide-seq, and seqFISH, irrespective of spatial resolution. Furthermore, GSG addresses dropout defects, enhancing gene expression by smoothing spatial patterns, extracting critical features, reducing batch effects, and enabling the integration of disparate datasets. Additionally, we performed spatial transcriptomic analysis on fetal human hearts, and applied GSG to extract biological insights. These experiments highlight GSG's accuracy in identifying spatial domains, uncovering specific *APCDD1* expression in fetal endocardium, and implicating its role in congenital heart disease. Our results showcase GSG's superiority and underscore its valuable contributions to advancing spatial-omics analysis.
|
|
20
|
+
|
|
21
|
+
## 🛠️ Installation
|
|
22
|
+
|
|
23
|
+
> [!NOTE]
|
|
24
|
+
> **!!! The recommended operating system is Ubuntu 18.04 LTS.** Some packages may not download correctly on Windows.
|
|
25
|
+
|
|
26
|
+
### Use python virutal environment with conda
|
|
27
|
+
|
|
28
|
+
```sh
|
|
29
|
+
conda create -n gsg python=3.8
|
|
30
|
+
conda activate gsg
|
|
31
|
+
# Need install cudnn based on your CUDA version.Refer to https://developer.nvidia.com/cudnn-archive
|
|
32
|
+
# conda install cudnn[=version]
|
|
33
|
+
```
|
|
34
|
+
|
|
35
|
+
### Install GSG
|
|
36
|
+
|
|
37
|
+
Install GSG and dgl(for gpu) from PyPi:
|
|
38
|
+
|
|
39
|
+
```sh
|
|
40
|
+
pip install GSG==0.5.8
|
|
41
|
+
pip install dgl-cu110 -f https://data.dgl.ai/wheels/repo.html
|
|
42
|
+
```
|
|
43
|
+
|
|
44
|
+
Required packages include:
|
|
45
|
+
|
|
46
|
+
```sh
|
|
47
|
+
torch==1.9.0, cudnn==8.4, numpy==1.22.0, scanpy==1.8.2, anndata==0.8.0, dgl==0.9.0,
|
|
48
|
+
pandas==1.2.4, scipy==1.7.3, scikit-learn==1.0.1, tqdm==4.64.1, matplotlib==3.5.3,
|
|
49
|
+
tensorboardX==2.5.1, pyyaml==6.0.1, plotly==5.21.0, kaleido==0.2.1, igraph==0.9.8
|
|
50
|
+
```
|
|
51
|
+
|
|
52
|
+
## 🚀 Quick Start
|
|
53
|
+
|
|
54
|
+
See our model document details from [Docs](https://keaml-guan.github.io/GSG/).
|
|
55
|
+
|
|
56
|
+
We provide the scripts for reproducing the quantitative and visualization results of the paper in [/docs/tutorials/](https://github.com/keaml-Guan/GSG/tree/main/docs/tutorials/).
|
|
57
|
+
|
|
58
|
+
## 📚 Citation
|
|
59
|
+
|
|
60
|
+
Wang C, Zhang T, Sun H, et al. A masked generative graph representation learning framework empowering precise spatial domain identification[J]. *Bioinformatics*, 2026, 42(6). ++[https://doi.org/10.1093/bioinformatics/btag333.](https://doi.org/10.1093/bioinformatics/btag333)++
|
|
61
|
+
|
|
62
|
+
## 📩 Contact
|
|
63
|
+
|
|
64
|
+
If you have any questions, feel free to contact [chuyao25@mails.jlu.edu.cn](mailto:chuyao25@mails.jlu.edu.cn).
|
gsg-0.6.0/README.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
1
|
+
# A masked generative graph representation learning framework empowering precise spatial domain identification
|
|
2
|
+
  
|
|
3
|
+
#
|
|
4
|
+

|
|
5
|
+
<br>
|
|
6
|
+
|
|
7
|
+
## ✨ Overview
|
|
8
|
+
|
|
9
|
+
Recent advances in spatial transcriptomics (ST) have opened new avenues for preserving spatial information while measuring gene expression. Yet, the challenge of seamlessly integrating this data into accurate and transferable representation remains. Here, we introduce a generative self-supervised graph (GSG) learning framework to achieve an effective joint embedding of location and gene expression within ST data. Our approach surpasses existing methods in identifying spatial domains within the human dorsolateral prefrontal cortex. Moreover, it can offer reliable analyses across various techniques, including Stereo-seq, Slide-seq, and seqFISH, irrespective of spatial resolution. Furthermore, GSG addresses dropout defects, enhancing gene expression by smoothing spatial patterns, extracting critical features, reducing batch effects, and enabling the integration of disparate datasets. Additionally, we performed spatial transcriptomic analysis on fetal human hearts, and applied GSG to extract biological insights. These experiments highlight GSG's accuracy in identifying spatial domains, uncovering specific *APCDD1* expression in fetal endocardium, and implicating its role in congenital heart disease. Our results showcase GSG's superiority and underscore its valuable contributions to advancing spatial-omics analysis.
|
|
10
|
+
|
|
11
|
+
## 🛠️ Installation
|
|
12
|
+
|
|
13
|
+
> [!NOTE]
|
|
14
|
+
> **!!! The recommended operating system is Ubuntu 18.04 LTS.** Some packages may not download correctly on Windows.
|
|
15
|
+
|
|
16
|
+
### Use python virutal environment with conda
|
|
17
|
+
|
|
18
|
+
```sh
|
|
19
|
+
conda create -n gsg python=3.8
|
|
20
|
+
conda activate gsg
|
|
21
|
+
# Need install cudnn based on your CUDA version.Refer to https://developer.nvidia.com/cudnn-archive
|
|
22
|
+
# conda install cudnn[=version]
|
|
23
|
+
```
|
|
24
|
+
|
|
25
|
+
### Install GSG
|
|
26
|
+
|
|
27
|
+
Install GSG and dgl(for gpu) from PyPi:
|
|
28
|
+
|
|
29
|
+
```sh
|
|
30
|
+
pip install GSG==0.5.8
|
|
31
|
+
pip install dgl-cu110 -f https://data.dgl.ai/wheels/repo.html
|
|
32
|
+
```
|
|
33
|
+
|
|
34
|
+
Required packages include:
|
|
35
|
+
|
|
36
|
+
```sh
|
|
37
|
+
torch==1.9.0, cudnn==8.4, numpy==1.22.0, scanpy==1.8.2, anndata==0.8.0, dgl==0.9.0,
|
|
38
|
+
pandas==1.2.4, scipy==1.7.3, scikit-learn==1.0.1, tqdm==4.64.1, matplotlib==3.5.3,
|
|
39
|
+
tensorboardX==2.5.1, pyyaml==6.0.1, plotly==5.21.0, kaleido==0.2.1, igraph==0.9.8
|
|
40
|
+
```
|
|
41
|
+
|
|
42
|
+
## 🚀 Quick Start
|
|
43
|
+
|
|
44
|
+
See our model document details from [Docs](https://keaml-guan.github.io/GSG/).
|
|
45
|
+
|
|
46
|
+
We provide the scripts for reproducing the quantitative and visualization results of the paper in [/docs/tutorials/](https://github.com/keaml-Guan/GSG/tree/main/docs/tutorials/).
|
|
47
|
+
|
|
48
|
+
## 📚 Citation
|
|
49
|
+
|
|
50
|
+
Wang C, Zhang T, Sun H, et al. A masked generative graph representation learning framework empowering precise spatial domain identification[J]. *Bioinformatics*, 2026, 42(6). ++[https://doi.org/10.1093/bioinformatics/btag333.](https://doi.org/10.1093/bioinformatics/btag333)++
|
|
51
|
+
|
|
52
|
+
## 📩 Contact
|
|
53
|
+
|
|
54
|
+
If you have any questions, feel free to contact [chuyao25@mails.jlu.edu.cn](mailto:chuyao25@mails.jlu.edu.cn).
|
|
@@ -0,0 +1,64 @@
|
|
|
1
|
+
Metadata-Version: 2.1
|
|
2
|
+
Name: gsg
|
|
3
|
+
Version: 0.6.0
|
|
4
|
+
Summary: GSG: A generative self-supervised graph learning framework for spatial transcriptomics
|
|
5
|
+
Author-email: Chuyao Wang <chuyao25@mails.jlu.edu.cn>
|
|
6
|
+
License: MIT
|
|
7
|
+
Requires-Python: >=3.7
|
|
8
|
+
Description-Content-Type: text/markdown
|
|
9
|
+
License-File: LICENSE.txt
|
|
10
|
+
|
|
11
|
+
# A masked generative graph representation learning framework empowering precise spatial domain identification
|
|
12
|
+
  
|
|
13
|
+
#
|
|
14
|
+

|
|
15
|
+
<br>
|
|
16
|
+
|
|
17
|
+
## ✨ Overview
|
|
18
|
+
|
|
19
|
+
Recent advances in spatial transcriptomics (ST) have opened new avenues for preserving spatial information while measuring gene expression. Yet, the challenge of seamlessly integrating this data into accurate and transferable representation remains. Here, we introduce a generative self-supervised graph (GSG) learning framework to achieve an effective joint embedding of location and gene expression within ST data. Our approach surpasses existing methods in identifying spatial domains within the human dorsolateral prefrontal cortex. Moreover, it can offer reliable analyses across various techniques, including Stereo-seq, Slide-seq, and seqFISH, irrespective of spatial resolution. Furthermore, GSG addresses dropout defects, enhancing gene expression by smoothing spatial patterns, extracting critical features, reducing batch effects, and enabling the integration of disparate datasets. Additionally, we performed spatial transcriptomic analysis on fetal human hearts, and applied GSG to extract biological insights. These experiments highlight GSG's accuracy in identifying spatial domains, uncovering specific *APCDD1* expression in fetal endocardium, and implicating its role in congenital heart disease. Our results showcase GSG's superiority and underscore its valuable contributions to advancing spatial-omics analysis.
|
|
20
|
+
|
|
21
|
+
## 🛠️ Installation
|
|
22
|
+
|
|
23
|
+
> [!NOTE]
|
|
24
|
+
> **!!! The recommended operating system is Ubuntu 18.04 LTS.** Some packages may not download correctly on Windows.
|
|
25
|
+
|
|
26
|
+
### Use python virutal environment with conda
|
|
27
|
+
|
|
28
|
+
```sh
|
|
29
|
+
conda create -n gsg python=3.8
|
|
30
|
+
conda activate gsg
|
|
31
|
+
# Need install cudnn based on your CUDA version.Refer to https://developer.nvidia.com/cudnn-archive
|
|
32
|
+
# conda install cudnn[=version]
|
|
33
|
+
```
|
|
34
|
+
|
|
35
|
+
### Install GSG
|
|
36
|
+
|
|
37
|
+
Install GSG and dgl(for gpu) from PyPi:
|
|
38
|
+
|
|
39
|
+
```sh
|
|
40
|
+
pip install GSG==0.5.8
|
|
41
|
+
pip install dgl-cu110 -f https://data.dgl.ai/wheels/repo.html
|
|
42
|
+
```
|
|
43
|
+
|
|
44
|
+
Required packages include:
|
|
45
|
+
|
|
46
|
+
```sh
|
|
47
|
+
torch==1.9.0, cudnn==8.4, numpy==1.22.0, scanpy==1.8.2, anndata==0.8.0, dgl==0.9.0,
|
|
48
|
+
pandas==1.2.4, scipy==1.7.3, scikit-learn==1.0.1, tqdm==4.64.1, matplotlib==3.5.3,
|
|
49
|
+
tensorboardX==2.5.1, pyyaml==6.0.1, plotly==5.21.0, kaleido==0.2.1, igraph==0.9.8
|
|
50
|
+
```
|
|
51
|
+
|
|
52
|
+
## 🚀 Quick Start
|
|
53
|
+
|
|
54
|
+
See our model document details from [Docs](https://keaml-guan.github.io/GSG/).
|
|
55
|
+
|
|
56
|
+
We provide the scripts for reproducing the quantitative and visualization results of the paper in [/docs/tutorials/](https://github.com/keaml-Guan/GSG/tree/main/docs/tutorials/).
|
|
57
|
+
|
|
58
|
+
## 📚 Citation
|
|
59
|
+
|
|
60
|
+
Wang C, Zhang T, Sun H, et al. A masked generative graph representation learning framework empowering precise spatial domain identification[J]. *Bioinformatics*, 2026, 42(6). ++[https://doi.org/10.1093/bioinformatics/btag333.](https://doi.org/10.1093/bioinformatics/btag333)++
|
|
61
|
+
|
|
62
|
+
## 📩 Contact
|
|
63
|
+
|
|
64
|
+
If you have any questions, feel free to contact [chuyao25@mails.jlu.edu.cn](mailto:chuyao25@mails.jlu.edu.cn).
|
|
@@ -0,0 +1,17 @@
|
|
|
1
|
+
LICENSE.txt
|
|
2
|
+
README.md
|
|
3
|
+
pyproject.toml
|
|
4
|
+
GSG/__init__.py
|
|
5
|
+
GSG/preprocess.py
|
|
6
|
+
GSG/train.py
|
|
7
|
+
GSG/utils.py
|
|
8
|
+
GSG/models/__init__.py
|
|
9
|
+
GSG/models/edcoder.py
|
|
10
|
+
GSG/models/gin.py
|
|
11
|
+
GSG/models/loss_func.py
|
|
12
|
+
GSG/models/utils.py
|
|
13
|
+
gsg.egg-info/PKG-INFO
|
|
14
|
+
gsg.egg-info/SOURCES.txt
|
|
15
|
+
gsg.egg-info/dependency_links.txt
|
|
16
|
+
gsg.egg-info/requires.txt
|
|
17
|
+
gsg.egg-info/top_level.txt
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
GSG
|
gsg-0.6.0/pyproject.toml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
1
|
+
[build-system]
|
|
2
|
+
requires = ["setuptools>=59.0", "wheel"]
|
|
3
|
+
build-backend = "setuptools.build_meta"
|
|
4
|
+
|
|
5
|
+
[project]
|
|
6
|
+
name = "gsg"
|
|
7
|
+
version = "0.6.0"
|
|
8
|
+
description = "GSG: A generative self-supervised graph learning framework for spatial transcriptomics"
|
|
9
|
+
readme = "README.md"
|
|
10
|
+
requires-python = ">=3.7"
|
|
11
|
+
authors = [
|
|
12
|
+
{name = "Chuyao Wang", email = "chuyao25@mails.jlu.edu.cn"}
|
|
13
|
+
]
|
|
14
|
+
license = {text = "MIT"}
|
|
15
|
+
|
|
16
|
+
dependencies = [
|
|
17
|
+
"numpy==1.21.6",
|
|
18
|
+
"pandas==1.2.4",
|
|
19
|
+
"scipy",
|
|
20
|
+
"scikit-learn",
|
|
21
|
+
"torch==1.9.0",
|
|
22
|
+
"dgl==0.9.0",
|
|
23
|
+
"scanpy==1.8.2",
|
|
24
|
+
"anndata==0.8.0",
|
|
25
|
+
"squidpy==1.1.2",
|
|
26
|
+
"leidenalg>=0.8.2,<0.11",
|
|
27
|
+
]
|
|
28
|
+
|
|
29
|
+
[tool.setuptools.packages.find]
|
|
30
|
+
where = ["."]
|
|
31
|
+
include = ["GSG*"]
|
gsg-0.6.0/setup.cfg
ADDED