file-brain 0.1.5__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- file_brain-0.1.5/PKG-INFO +136 -0
- file_brain-0.1.5/README.md +94 -0
- file_brain-0.1.5/file_brain/__init__.py +11 -0
- file_brain-0.1.5/file_brain/api/__init__.py +0 -0
- file_brain-0.1.5/file_brain/api/models/__init__.py +32 -0
- file_brain-0.1.5/file_brain/api/models/crawler.py +108 -0
- file_brain-0.1.5/file_brain/api/models/file_event.py +14 -0
- file_brain-0.1.5/file_brain/api/models/operations.py +39 -0
- file_brain-0.1.5/file_brain/api/v1/__init__.py +3 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/__init__.py +3 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/config.py +29 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/crawler.py +621 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/files.py +485 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/fs.py +205 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/settings.py +56 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/stats_extended.py +493 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/system.py +145 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/system_stream.py +108 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/watch_paths.py +208 -0
- file_brain-0.1.5/file_brain/api/v1/endpoints/wizard.py +997 -0
- file_brain-0.1.5/file_brain/api/v1/router.py +20 -0
- file_brain-0.1.5/file_brain/core/__init__.py +3 -0
- file_brain-0.1.5/file_brain/core/app_info.py +49 -0
- file_brain-0.1.5/file_brain/core/config.py +103 -0
- file_brain-0.1.5/file_brain/core/exceptions.py +55 -0
- file_brain-0.1.5/file_brain/core/factory.py +38 -0
- file_brain-0.1.5/file_brain/core/frontend.py +121 -0
- file_brain-0.1.5/file_brain/core/initialization.py +288 -0
- file_brain-0.1.5/file_brain/core/logging.py +50 -0
- file_brain-0.1.5/file_brain/core/paths.py +93 -0
- file_brain-0.1.5/file_brain/core/telemetry.py +284 -0
- file_brain-0.1.5/file_brain/core/typesense_schema.py +106 -0
- file_brain-0.1.5/file_brain/database/__init__.py +5 -0
- file_brain-0.1.5/file_brain/database/models/__init__.py +23 -0
- file_brain-0.1.5/file_brain/database/models/base.py +86 -0
- file_brain-0.1.5/file_brain/database/models/crawler_state.py +41 -0
- file_brain-0.1.5/file_brain/database/models/setting.py +22 -0
- file_brain-0.1.5/file_brain/database/models/watch_path.py +23 -0
- file_brain-0.1.5/file_brain/database/models/wizard_state.py +39 -0
- file_brain-0.1.5/file_brain/database/repositories/__init__.py +17 -0
- file_brain-0.1.5/file_brain/database/repositories/base.py +55 -0
- file_brain-0.1.5/file_brain/database/repositories/crawler_state.py +75 -0
- file_brain-0.1.5/file_brain/database/repositories/settings.py +78 -0
- file_brain-0.1.5/file_brain/database/repositories/watch_path.py +67 -0
- file_brain-0.1.5/file_brain/database/repositories/wizard_state_repository.py +98 -0
- file_brain-0.1.5/file_brain/docker-compose.yml +41 -0
- file_brain-0.1.5/file_brain/frontend/__init__.py +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/auto-CquwA8NN.js +3 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/fa-brands-400-BfBXV7Mm.woff2 +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/fa-regular-400-BVHPE7da.woff2 +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/fa-solid-900-8GirhLYJ.woff2 +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/index-B2nunFub.js +1698 -0
- file_brain-0.1.5/file_brain/frontend/dist/assets/index-V-udL-B1.css +1 -0
- file_brain-0.1.5/file_brain/frontend/dist/icon.svg +1 -0
- file_brain-0.1.5/file_brain/frontend/dist/index.html +25 -0
- file_brain-0.1.5/file_brain/frontend/dist/themes/fonts/InterVariable-Italic.woff2 +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/themes/fonts/InterVariable.woff2 +0 -0
- file_brain-0.1.5/file_brain/frontend/dist/themes/lara-dark-cyan-theme.css +7078 -0
- file_brain-0.1.5/file_brain/frontend/dist/themes/lara-light-cyan-theme.css +7068 -0
- file_brain-0.1.5/file_brain/lib/__init__.py +0 -0
- file_brain-0.1.5/file_brain/lib/flaskwebgui.py +313 -0
- file_brain-0.1.5/file_brain/main.py +262 -0
- file_brain-0.1.5/file_brain/services/__init__.py +0 -0
- file_brain-0.1.5/file_brain/services/chunker.py +92 -0
- file_brain-0.1.5/file_brain/services/crawler/__init__.py +3 -0
- file_brain-0.1.5/file_brain/services/crawler/discoverer.py +117 -0
- file_brain-0.1.5/file_brain/services/crawler/indexer.py +144 -0
- file_brain-0.1.5/file_brain/services/crawler/manager.py +432 -0
- file_brain-0.1.5/file_brain/services/crawler/monitor.py +193 -0
- file_brain-0.1.5/file_brain/services/crawler/path_utils.py +89 -0
- file_brain-0.1.5/file_brain/services/crawler/progress.py +136 -0
- file_brain-0.1.5/file_brain/services/crawler/queue.py +62 -0
- file_brain-0.1.5/file_brain/services/crawler/stoppable.py +61 -0
- file_brain-0.1.5/file_brain/services/crawler/verification.py +145 -0
- file_brain-0.1.5/file_brain/services/docker_manager.py +903 -0
- file_brain-0.1.5/file_brain/services/extraction/__init__.py +18 -0
- file_brain-0.1.5/file_brain/services/extraction/basic_strategy.py +93 -0
- file_brain-0.1.5/file_brain/services/extraction/extractor.py +98 -0
- file_brain-0.1.5/file_brain/services/extraction/protocol.py +37 -0
- file_brain-0.1.5/file_brain/services/extraction/tika_strategy.py +93 -0
- file_brain-0.1.5/file_brain/services/model_downloader.py +307 -0
- file_brain-0.1.5/file_brain/services/service_manager.py +530 -0
- file_brain-0.1.5/file_brain/services/startup_checker.py +425 -0
- file_brain-0.1.5/file_brain/services/typesense_client.py +596 -0
- file_brain-0.1.5/pyproject.toml +106 -0
|
@@ -0,0 +1,136 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
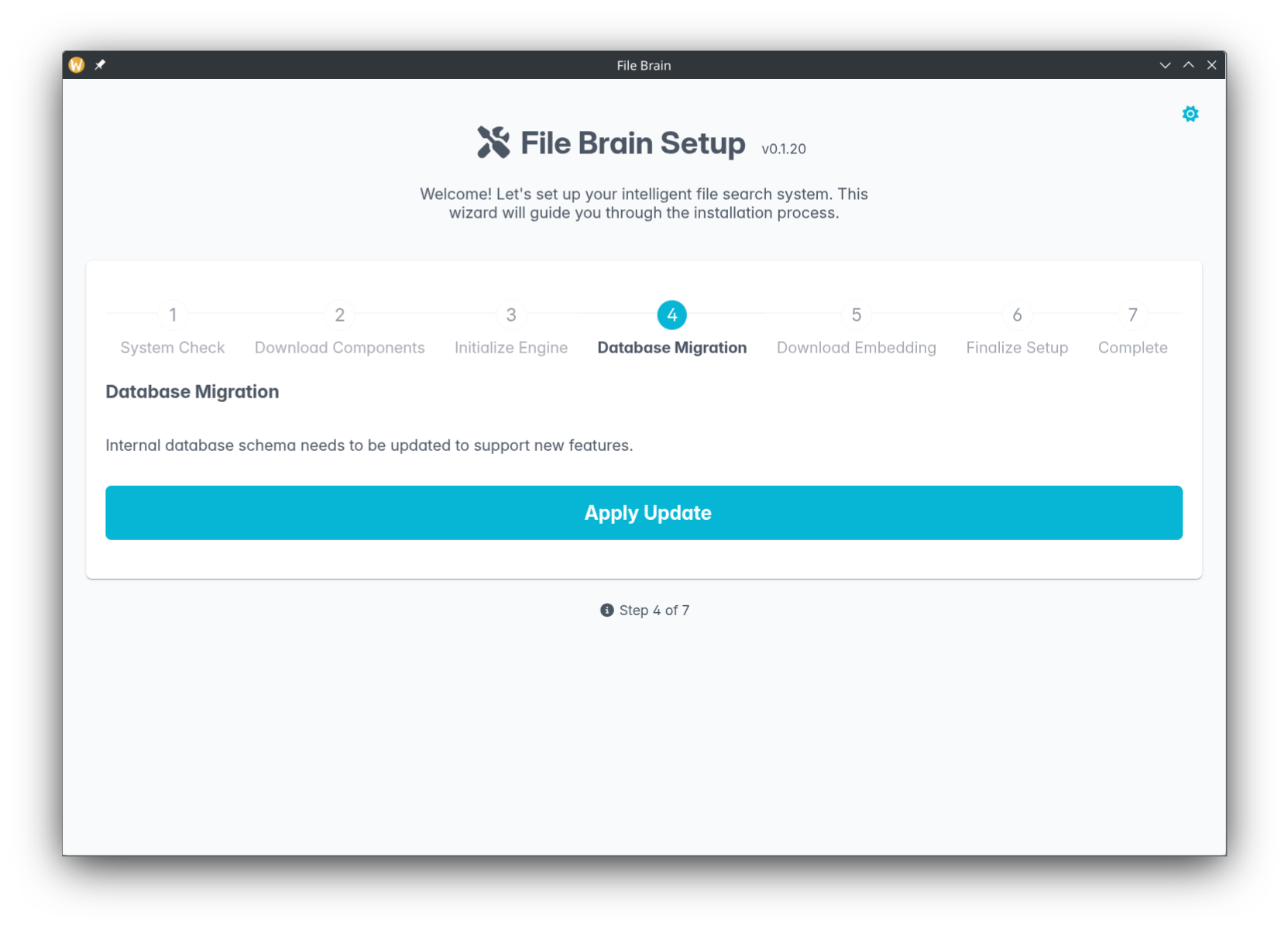
+
Name: file-brain
|
|
3
|
+
Version: 0.1.5
|
|
4
|
+
Summary: Advanced file search engine powered by AI
|
|
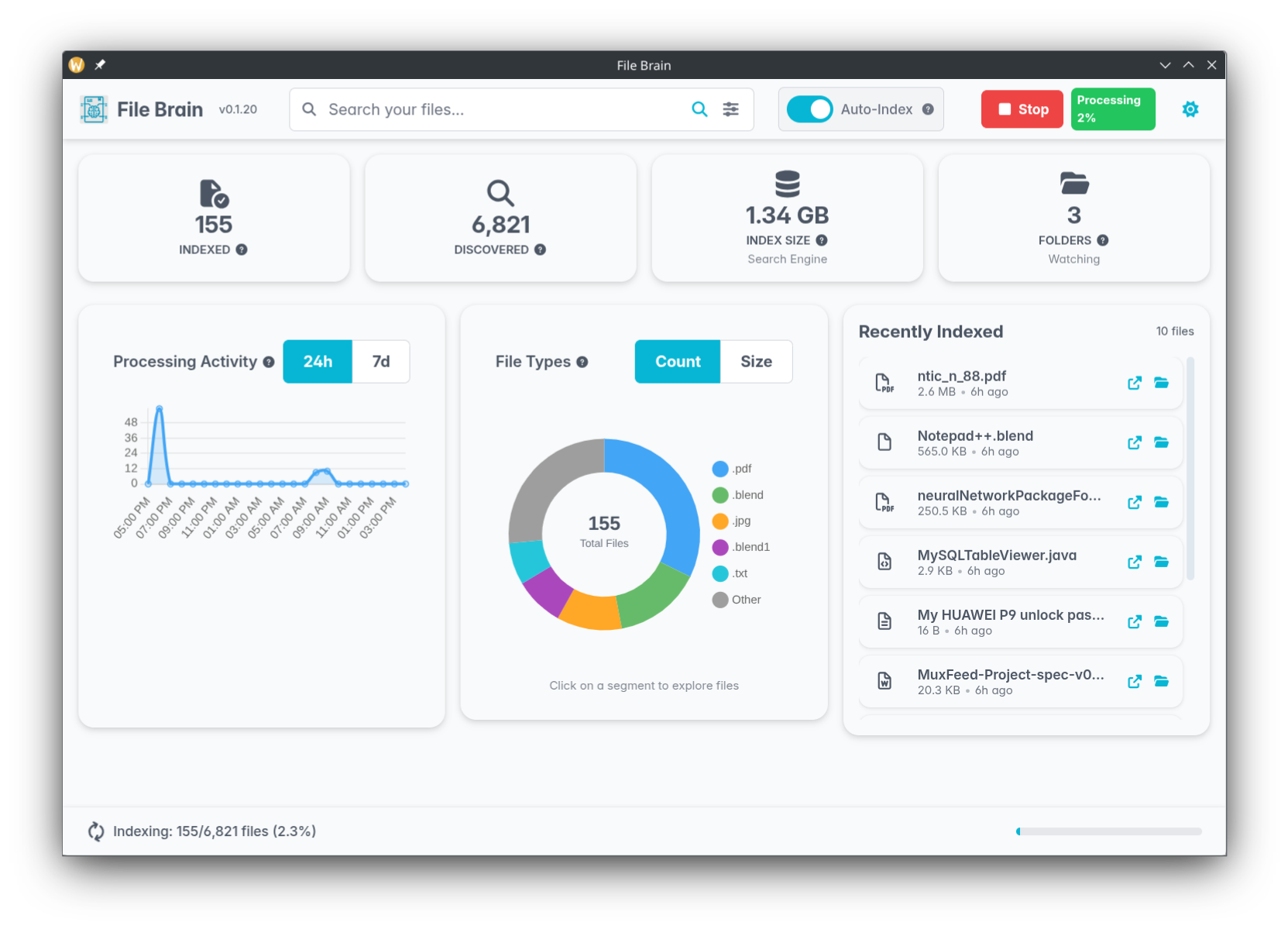
5
|
+
License: GPL-3.0-or-later
|
|
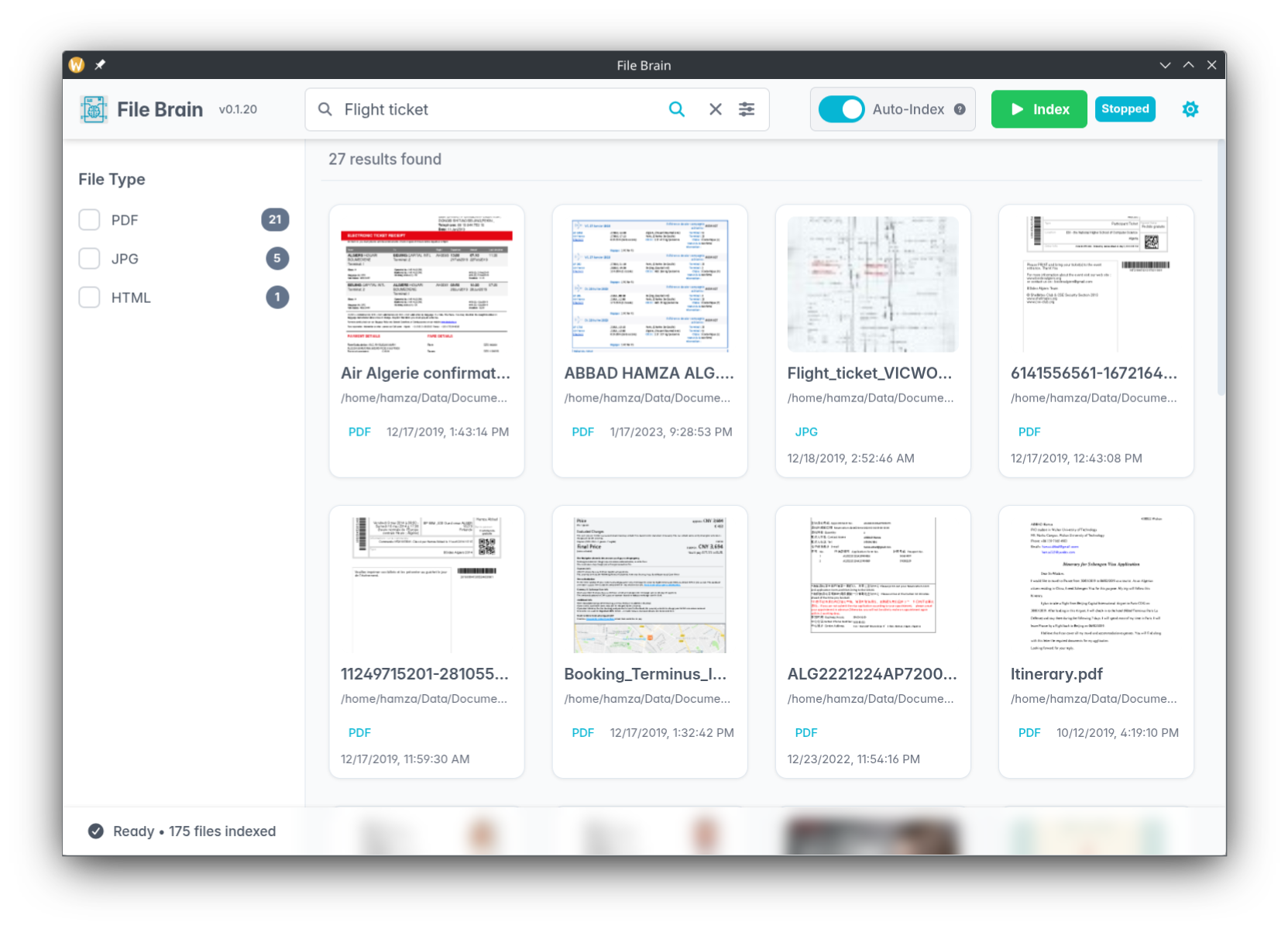
6
|
+
Keywords: search,file-indexing,semantic-search,local-search,search-engine,gui,filesystem,fuzzy-search,file,artificial-intelligence,desktop-application,image-search,file-management,embedding,apache-tika,filesystem-indexer,document-search,typesense,archive-search,ocr
|
|
7
|
+
Author: Hamza Abbad
|
|
8
|
+
Author-email: contact@file-brain.com
|
|
9
|
+
Requires-Python: >=3.11,<3.15
|
|
10
|
+
Classifier: Development Status :: 4 - Beta
|
|
11
|
+
Classifier: Intended Audience :: End Users/Desktop
|
|
12
|
+
Classifier: License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)
|
|
13
|
+
Classifier: Programming Language :: Python :: 3.11
|
|
14
|
+
Classifier: Programming Language :: Python :: 3.12
|
|
15
|
+
Classifier: Programming Language :: Python :: 3.13
|
|
16
|
+
Classifier: Programming Language :: Python :: 3.14
|
|
17
|
+
Classifier: Topic :: Desktop Environment :: File Managers
|
|
18
|
+
Classifier: Topic :: Text Processing :: Indexing
|
|
19
|
+
Classifier: Environment :: GPU :: NVIDIA CUDA
|
|
20
|
+
Requires-Dist: aiohttp (>=3.13.2,<4.0.0)
|
|
21
|
+
Requires-Dist: chardet (>=5.2.0,<6.0.0)
|
|
22
|
+
Requires-Dist: docker (>=7.1.0,<8.0.0)
|
|
23
|
+
Requires-Dist: fastapi[standard-no-fastapi-cloud-cli] (>=0.121.0,<0.122.0)
|
|
24
|
+
Requires-Dist: huggingface-hub (>=1.2.4,<2.0.0)
|
|
25
|
+
Requires-Dist: platformdirs (>=4.5.1,<5.0.0)
|
|
26
|
+
Requires-Dist: podman (>=5.6.0,<6.0.0)
|
|
27
|
+
Requires-Dist: posthog (>=7.5.1,<8.0.0)
|
|
28
|
+
Requires-Dist: psutil (>=6.0.0,<7.0.0)
|
|
29
|
+
Requires-Dist: py-machineid (>=1.0.0,<2.0.0)
|
|
30
|
+
Requires-Dist: pydantic (>=2.12.4,<3.0.0)
|
|
31
|
+
Requires-Dist: pydantic-settings (>=2.11.0,<3.0.0)
|
|
32
|
+
Requires-Dist: python-magic (>=0.4.27,<0.5.0)
|
|
33
|
+
Requires-Dist: sqlalchemy (>=2.0.44,<3.0.0)
|
|
34
|
+
Requires-Dist: tika (>=3.1.0,<4.0.0)
|
|
35
|
+
Requires-Dist: typesense (>=1.1.1,<2.0.0)
|
|
36
|
+
Requires-Dist: watchdog (>=6.0.0,<7.0.0)
|
|
37
|
+
Project-URL: Homepage, https://file-brain.com
|
|
38
|
+
Project-URL: Issues, https://github.com/Hamza5/file-brain/issues
|
|
39
|
+
Project-URL: Repository, https://github.com/Hamza5/file-brain
|
|
40
|
+
Description-Content-Type: text/markdown
|
|
41
|
+
|
|
42
|
+
<div align="center">
|
|
43
|
+
<img src="https://raw.githubusercontent.com/hamza5/file-brain/main/docs/images/logo.svg" alt="File Brain Logo" width="120" />
|
|
44
|
+
<h1>File Brain</h1>
|
|
45
|
+
<p><strong>Your Local AI Search Engine</strong></p>
|
|
46
|
+
|
|
47
|
+
[](https://github.com/hamza5/file-brain/actions/workflows/ci.yml)
|
|
48
|
+
[](https://github.com/hamza5/file-brain/actions/workflows/release.yml)
|
|
49
|
+
|
|
50
|
+
</div>
|
|
51
|
+
|
|
52
|
+
<p align="center">
|
|
53
|
+
Find what you mean, not just what you say. File Brain runs locally on your machine to index and understand your files.
|
|
54
|
+
</p>
|
|
55
|
+
|
|
56
|
+
## What is File Brain?
|
|
57
|
+
|
|
58
|
+
File Brain is a desktop application that helps you find files instantly using natural language. Instead of remembering exact filenames, you can ask questions like "flight ticket invoice", and File Brain uses AI to understand the meaning and show the relevant files.
|
|
59
|
+
|
|
60
|
+
## Key Features
|
|
61
|
+
|
|
62
|
+
- **🧠 Find what you mean**: Uses advanced Semantic Search -in addition to full text search- to understand the intent behind your query (e.g., search for "worker", find documents mentioning "employee").
|
|
63
|
+
- **📝 Typo Resistance**: Robust against typos. Search for "iphone" even if you typed "ipnone".
|
|
64
|
+
- **📄 Supports Everything**: Extracts the content of over 1400+ file formats (PDF, Word, Excel, PowerPoint, images, archives, and more).
|
|
65
|
+
- **🌍 Cross-Language Search**: Search in one language to find documents written in another (e.g., search for "Chair", find documents mentioning "Silla" -in Spanish-).
|
|
66
|
+
- **🚀 Fast Matching**: Search results are shown within milliseconds, not minutes.
|
|
67
|
+
- **👁️ OCR Support**: Automatically extracts text from screenshots, and scanned documents.
|
|
68
|
+
- **⚡ Auto-Indexing**: Detects changes in real-time and updates the index instantly.
|
|
69
|
+
- **🔒 Privacy First**: All indexing and AI processing happens 100% locally on your machine. Your data never leaves your computer.
|
|
70
|
+
|
|
71
|
+
## Prerequisites
|
|
72
|
+
|
|
73
|
+
- **Python 3.11** or higher
|
|
74
|
+
- **Docker** or **Podman** (Must be installed and ready to run)
|
|
75
|
+
|
|
76
|
+
## Installation
|
|
77
|
+
|
|
78
|
+
Install File Brain easily using pip:
|
|
79
|
+
|
|
80
|
+
```bash
|
|
81
|
+
pip install -U file-brain
|
|
82
|
+
```
|
|
83
|
+
|
|
84
|
+
## Getting Started
|
|
85
|
+
|
|
86
|
+
1. **Run the App**:
|
|
87
|
+
|
|
88
|
+
```bash
|
|
89
|
+
file-brain
|
|
90
|
+
```
|
|
91
|
+
|
|
92
|
+
2. **Initialization Wizard**:
|
|
93
|
+
On the first run, a simple wizard will guide you:
|
|
94
|
+
1. **System Check**: Verifies Docker is running.
|
|
95
|
+
2. **Download Components**: Downloads the necessary search services.
|
|
96
|
+
3. **Initialize Engine**: Starts the background search components.
|
|
97
|
+
4. **Download AI Model**: Fetches the AI model for intelligent search.
|
|
98
|
+
5. **Finalize Setup**: Initializes the search engine database.
|
|
99
|
+
|
|
100
|
+
|
|
101
|
+
_The easy-to-use setup wizard that guides you through downloading models and initializing the search database._
|
|
102
|
+
|
|
103
|
+
3. **Select Folders**:
|
|
104
|
+
Choose the folders you want to index via the dashboard settings.
|
|
105
|
+
|
|
106
|
+
4. **Indexing**:
|
|
107
|
+
- **Manual Indexing**: Performs a deep scan of all files. Great for initial setup.
|
|
108
|
+
- **Auto-Indexing**: Watches for new or changed files and processes them instantly.
|
|
109
|
+
|
|
110
|
+
> **Note**: File Brain must be running for the background indexing to process your files.
|
|
111
|
+
|
|
112
|
+
## Visualizing the Interaction
|
|
113
|
+
|
|
114
|
+
### Dashboard
|
|
115
|
+
|
|
116
|
+
See all your indexed files, storage usage, and recently indexed files at a glance.
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
|
|
120
|
+
### Semantic Search
|
|
121
|
+
|
|
122
|
+
Search naturally, like "Airplane ticket" to find relevant documents even if the filename is different.
|
|
123
|
+
|
|
124
|
+
|
|
125
|
+
|
|
126
|
+
## **PRO** Version
|
|
127
|
+
|
|
128
|
+
Want more power? The **PRO** version is on the way with advanced capabilities:
|
|
129
|
+
|
|
130
|
+
- **Chat with Files**: Ask questions and get answers from your documents.
|
|
131
|
+
- **Search by File**: Find semantically similar files.
|
|
132
|
+
- **Video Search**: Find scenes in your videos.
|
|
133
|
+
- **Cloud & Network Drives**: Connect Google Drive, Dropbox, Box, and network drives.
|
|
134
|
+
|
|
135
|
+
[Check out the website](https://file-brain.com/) to learn more.
|
|
136
|
+
|
|
@@ -0,0 +1,94 @@
|
|
|
1
|
+
<div align="center">
|
|
2
|
+
<img src="https://raw.githubusercontent.com/hamza5/file-brain/main/docs/images/logo.svg" alt="File Brain Logo" width="120" />
|
|
3
|
+
<h1>File Brain</h1>
|
|
4
|
+
<p><strong>Your Local AI Search Engine</strong></p>
|
|
5
|
+
|
|
6
|
+
[](https://github.com/hamza5/file-brain/actions/workflows/ci.yml)
|
|
7
|
+
[](https://github.com/hamza5/file-brain/actions/workflows/release.yml)
|
|
8
|
+
|
|
9
|
+
</div>
|
|
10
|
+
|
|
11
|
+
<p align="center">
|
|
12
|
+
Find what you mean, not just what you say. File Brain runs locally on your machine to index and understand your files.
|
|
13
|
+
</p>
|
|
14
|
+
|
|
15
|
+
## What is File Brain?
|
|
16
|
+
|
|
17
|
+
File Brain is a desktop application that helps you find files instantly using natural language. Instead of remembering exact filenames, you can ask questions like "flight ticket invoice", and File Brain uses AI to understand the meaning and show the relevant files.
|
|
18
|
+
|
|
19
|
+
## Key Features
|
|
20
|
+
|
|
21
|
+
- **🧠 Find what you mean**: Uses advanced Semantic Search -in addition to full text search- to understand the intent behind your query (e.g., search for "worker", find documents mentioning "employee").
|
|
22
|
+
- **📝 Typo Resistance**: Robust against typos. Search for "iphone" even if you typed "ipnone".
|
|
23
|
+
- **📄 Supports Everything**: Extracts the content of over 1400+ file formats (PDF, Word, Excel, PowerPoint, images, archives, and more).
|
|
24
|
+
- **🌍 Cross-Language Search**: Search in one language to find documents written in another (e.g., search for "Chair", find documents mentioning "Silla" -in Spanish-).
|
|
25
|
+
- **🚀 Fast Matching**: Search results are shown within milliseconds, not minutes.
|
|
26
|
+
- **👁️ OCR Support**: Automatically extracts text from screenshots, and scanned documents.
|
|
27
|
+
- **⚡ Auto-Indexing**: Detects changes in real-time and updates the index instantly.
|
|
28
|
+
- **🔒 Privacy First**: All indexing and AI processing happens 100% locally on your machine. Your data never leaves your computer.
|
|
29
|
+
|
|
30
|
+
## Prerequisites
|
|
31
|
+
|
|
32
|
+
- **Python 3.11** or higher
|
|
33
|
+
- **Docker** or **Podman** (Must be installed and ready to run)
|
|
34
|
+
|
|
35
|
+
## Installation
|
|
36
|
+
|
|
37
|
+
Install File Brain easily using pip:
|
|
38
|
+
|
|
39
|
+
```bash
|
|
40
|
+
pip install -U file-brain
|
|
41
|
+
```
|
|
42
|
+
|
|
43
|
+
## Getting Started
|
|
44
|
+
|
|
45
|
+
1. **Run the App**:
|
|
46
|
+
|
|
47
|
+
```bash
|
|
48
|
+
file-brain
|
|
49
|
+
```
|
|
50
|
+
|
|
51
|
+
2. **Initialization Wizard**:
|
|
52
|
+
On the first run, a simple wizard will guide you:
|
|
53
|
+
1. **System Check**: Verifies Docker is running.
|
|
54
|
+
2. **Download Components**: Downloads the necessary search services.
|
|
55
|
+
3. **Initialize Engine**: Starts the background search components.
|
|
56
|
+
4. **Download AI Model**: Fetches the AI model for intelligent search.
|
|
57
|
+
5. **Finalize Setup**: Initializes the search engine database.
|
|
58
|
+
|
|
59
|
+

|
|
60
|
+
_The easy-to-use setup wizard that guides you through downloading models and initializing the search database._
|
|
61
|
+
|
|
62
|
+
3. **Select Folders**:
|
|
63
|
+
Choose the folders you want to index via the dashboard settings.
|
|
64
|
+
|
|
65
|
+
4. **Indexing**:
|
|
66
|
+
- **Manual Indexing**: Performs a deep scan of all files. Great for initial setup.
|
|
67
|
+
- **Auto-Indexing**: Watches for new or changed files and processes them instantly.
|
|
68
|
+
|
|
69
|
+
> **Note**: File Brain must be running for the background indexing to process your files.
|
|
70
|
+
|
|
71
|
+
## Visualizing the Interaction
|
|
72
|
+
|
|
73
|
+
### Dashboard
|
|
74
|
+
|
|
75
|
+
See all your indexed files, storage usage, and recently indexed files at a glance.
|
|
76
|
+
|
|
77
|
+

|
|
78
|
+
|
|
79
|
+
### Semantic Search
|
|
80
|
+
|
|
81
|
+
Search naturally, like "Airplane ticket" to find relevant documents even if the filename is different.
|
|
82
|
+
|
|
83
|
+

|
|
84
|
+
|
|
85
|
+
## **PRO** Version
|
|
86
|
+
|
|
87
|
+
Want more power? The **PRO** version is on the way with advanced capabilities:
|
|
88
|
+
|
|
89
|
+
- **Chat with Files**: Ask questions and get answers from your documents.
|
|
90
|
+
- **Search by File**: Find semantically similar files.
|
|
91
|
+
- **Video Search**: Find scenes in your videos.
|
|
92
|
+
- **Cloud & Network Drives**: Connect Google Drive, Dropbox, Box, and network drives.
|
|
93
|
+
|
|
94
|
+
[Check out the website](https://file-brain.com/) to learn more.
|
|
@@ -0,0 +1,11 @@
|
|
|
1
|
+
"""
|
|
2
|
+
File Brain - Advanced file search engine powered by AI
|
|
3
|
+
"""
|
|
4
|
+
|
|
5
|
+
from file_brain.core.app_info import get_app_description, get_app_name, get_app_version
|
|
6
|
+
|
|
7
|
+
__version__ = get_app_version()
|
|
8
|
+
__app_name__ = get_app_name()
|
|
9
|
+
__description__ = get_app_description()
|
|
10
|
+
|
|
11
|
+
__all__ = ["__version__", "__app_name__", "__description__"]
|
|
File without changes
|
|
@@ -0,0 +1,32 @@
|
|
|
1
|
+
"""
|
|
2
|
+
API models package
|
|
3
|
+
"""
|
|
4
|
+
|
|
5
|
+
from .crawler import (
|
|
6
|
+
ClearIndexesResponse,
|
|
7
|
+
CrawlerStats,
|
|
8
|
+
# Backward compatibility
|
|
9
|
+
CrawlerStatus,
|
|
10
|
+
CrawlerStatusResponse,
|
|
11
|
+
# Enhanced models
|
|
12
|
+
CrawlStatus,
|
|
13
|
+
CrawlStatusResponse,
|
|
14
|
+
JobControlRequest,
|
|
15
|
+
MessageResponse,
|
|
16
|
+
)
|
|
17
|
+
from .file_event import DocumentContent
|
|
18
|
+
|
|
19
|
+
__all__ = [
|
|
20
|
+
# Backward compatibility
|
|
21
|
+
"CrawlerStatus",
|
|
22
|
+
"CrawlerStats",
|
|
23
|
+
"CrawlerStatusResponse",
|
|
24
|
+
"MessageResponse",
|
|
25
|
+
# Enhanced models
|
|
26
|
+
"CrawlStatus",
|
|
27
|
+
"CrawlStatusResponse",
|
|
28
|
+
"ClearIndexesResponse",
|
|
29
|
+
"JobControlRequest",
|
|
30
|
+
# Content models
|
|
31
|
+
"DocumentContent",
|
|
32
|
+
]
|
|
@@ -0,0 +1,108 @@
|
|
|
1
|
+
"""
|
|
2
|
+
API request/response models for crawl functionality
|
|
3
|
+
"""
|
|
4
|
+
|
|
5
|
+
from typing import Any, Dict, Optional
|
|
6
|
+
|
|
7
|
+
from pydantic import BaseModel, Field
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
# Backward compatibility models
|
|
11
|
+
class CrawlerStatus(BaseModel):
|
|
12
|
+
"""Crawl status information"""
|
|
13
|
+
|
|
14
|
+
running: bool
|
|
15
|
+
job_type: Optional[str] = None # "crawl", "monitor", or "crawl+monitor"
|
|
16
|
+
start_time: Optional[int] = None # Unix timestamp in ms
|
|
17
|
+
elapsed_time: Optional[int] = None # Seconds
|
|
18
|
+
discovery_progress: int = 0 # 0-100
|
|
19
|
+
indexing_progress: int = 0 # 0-100
|
|
20
|
+
verification_progress: int = 0 # 0-100
|
|
21
|
+
files_discovered: int = 0
|
|
22
|
+
files_indexed: int = 0
|
|
23
|
+
files_skipped: int = 0
|
|
24
|
+
files_error: int = 0
|
|
25
|
+
orphan_count: int = 0
|
|
26
|
+
queue_size: int = 0
|
|
27
|
+
estimated_completion: Optional[int] = None # Unix timestamp in ms
|
|
28
|
+
|
|
29
|
+
|
|
30
|
+
class CrawlerStats(BaseModel):
|
|
31
|
+
"""Crawler statistics"""
|
|
32
|
+
|
|
33
|
+
files_discovered: int = 0
|
|
34
|
+
files_indexed: int = 0
|
|
35
|
+
files_error: int = 0
|
|
36
|
+
files_deleted: int = 0
|
|
37
|
+
files_orphaned: int = 0
|
|
38
|
+
queue_size: int = 0
|
|
39
|
+
last_activity: Optional[int] = None
|
|
40
|
+
|
|
41
|
+
|
|
42
|
+
class CrawlerStatusResponse(BaseModel):
|
|
43
|
+
"""Response for crawl status endpoint"""
|
|
44
|
+
|
|
45
|
+
status: Dict[str, Any] # Can be CrawlerStatus or dictionary
|
|
46
|
+
stats: Optional[CrawlerStats] = None
|
|
47
|
+
timestamp: int
|
|
48
|
+
|
|
49
|
+
|
|
50
|
+
# Enhanced models
|
|
51
|
+
class CrawlStatus(BaseModel):
|
|
52
|
+
"""Enhanced crawl status information"""
|
|
53
|
+
|
|
54
|
+
running: bool
|
|
55
|
+
job_type: Optional[str] = None # "crawl", "monitor", or "crawl+monitor"
|
|
56
|
+
start_time: Optional[int] = None # Unix timestamp in ms
|
|
57
|
+
elapsed_time: Optional[int] = None # Seconds
|
|
58
|
+
discovery_progress: int = 0 # 0-100
|
|
59
|
+
indexing_progress: int = 0 # 0-100
|
|
60
|
+
verification_progress: int = 0 # 0-100
|
|
61
|
+
files_discovered: int = 0
|
|
62
|
+
files_indexed: int = 0
|
|
63
|
+
files_skipped: int = 0
|
|
64
|
+
files_error: int = 0
|
|
65
|
+
orphan_count: int = 0
|
|
66
|
+
queue_size: int = 0
|
|
67
|
+
estimated_completion: Optional[int] = None # Unix timestamp in ms
|
|
68
|
+
|
|
69
|
+
|
|
70
|
+
class CrawlStatusResponse(BaseModel):
|
|
71
|
+
"""Response for crawl status endpoint"""
|
|
72
|
+
|
|
73
|
+
status: Dict[str, Any] # Can be CrawlStatus or dictionary
|
|
74
|
+
timestamp: int
|
|
75
|
+
|
|
76
|
+
|
|
77
|
+
class WatchPathCreateRequest(BaseModel):
|
|
78
|
+
"""Request to add a single watch path"""
|
|
79
|
+
|
|
80
|
+
path: str = Field(..., description="Path to add")
|
|
81
|
+
include_subdirectories: bool = Field(
|
|
82
|
+
default=True,
|
|
83
|
+
description="Whether to include subdirectories",
|
|
84
|
+
)
|
|
85
|
+
enabled: bool = Field(default=True, description="Whether path should be enabled")
|
|
86
|
+
is_excluded: bool = Field(default=False, description="Whether path should be excluded from indexing")
|
|
87
|
+
|
|
88
|
+
|
|
89
|
+
class ClearIndexesResponse(BaseModel):
|
|
90
|
+
"""Response for clear indexes operation"""
|
|
91
|
+
|
|
92
|
+
success: bool
|
|
93
|
+
message: str
|
|
94
|
+
timestamp: int
|
|
95
|
+
|
|
96
|
+
|
|
97
|
+
class MessageResponse(BaseModel):
|
|
98
|
+
"""Generic message response"""
|
|
99
|
+
|
|
100
|
+
message: str
|
|
101
|
+
success: bool = True
|
|
102
|
+
timestamp: int
|
|
103
|
+
|
|
104
|
+
|
|
105
|
+
class JobControlRequest(BaseModel):
|
|
106
|
+
"""Request for job control operations"""
|
|
107
|
+
|
|
108
|
+
force: bool = Field(default=False, description="Force operation even if risky")
|
|
@@ -0,0 +1,14 @@
|
|
|
1
|
+
"""
|
|
2
|
+
Document content model for extraction results
|
|
3
|
+
"""
|
|
4
|
+
|
|
5
|
+
from typing import Any, Dict
|
|
6
|
+
|
|
7
|
+
from pydantic import BaseModel, Field
|
|
8
|
+
|
|
9
|
+
|
|
10
|
+
class DocumentContent(BaseModel):
|
|
11
|
+
"""Extracted document content"""
|
|
12
|
+
|
|
13
|
+
content: str = Field(description="Document content")
|
|
14
|
+
metadata: Dict[str, Any] = Field(default_factory=dict, description="Document metadata")
|
|
@@ -0,0 +1,39 @@
|
|
|
1
|
+
"""
|
|
2
|
+
Enhanced operation queue with operation types
|
|
3
|
+
"""
|
|
4
|
+
|
|
5
|
+
from enum import Enum
|
|
6
|
+
from typing import Optional
|
|
7
|
+
|
|
8
|
+
from pydantic import BaseModel, Field
|
|
9
|
+
|
|
10
|
+
|
|
11
|
+
class OperationType(str, Enum):
|
|
12
|
+
"""Type of file operation"""
|
|
13
|
+
|
|
14
|
+
CREATE = "create" # New file discovered
|
|
15
|
+
EDIT = "edit" # File modified
|
|
16
|
+
DELETE = "delete" # File deleted
|
|
17
|
+
|
|
18
|
+
|
|
19
|
+
class CrawlOperation(BaseModel):
|
|
20
|
+
"""
|
|
21
|
+
Enhanced operation for the queue
|
|
22
|
+
Includes operation type, file info, and metadata
|
|
23
|
+
"""
|
|
24
|
+
|
|
25
|
+
operation: OperationType
|
|
26
|
+
file_path: str
|
|
27
|
+
file_hash: Optional[str] = None
|
|
28
|
+
file_size: Optional[int] = None
|
|
29
|
+
modified_time: Optional[int] = None # Unix timestamp in ms
|
|
30
|
+
created_time: Optional[int] = None # Unix timestamp in ms
|
|
31
|
+
discovered_at: Optional[int] = None # When file was discovered (for initial crawl ordering)
|
|
32
|
+
|
|
33
|
+
# Additional metadata
|
|
34
|
+
source: str = Field(description="Source of operation: 'crawl' or 'watch'")
|
|
35
|
+
retry_count: int = 0 # For failed operations
|
|
36
|
+
priority: int = 0 # Higher numbers = higher priority
|
|
37
|
+
|
|
38
|
+
class Config:
|
|
39
|
+
use_enum_values = True
|
|
@@ -0,0 +1,29 @@
|
|
|
1
|
+
from fastapi import APIRouter
|
|
2
|
+
from pydantic import BaseModel
|
|
3
|
+
|
|
4
|
+
from file_brain.core.config import settings
|
|
5
|
+
|
|
6
|
+
router = APIRouter()
|
|
7
|
+
|
|
8
|
+
|
|
9
|
+
class AppConfig(BaseModel):
|
|
10
|
+
"""Configuration exposed to the frontend"""
|
|
11
|
+
|
|
12
|
+
typesense: dict
|
|
13
|
+
|
|
14
|
+
|
|
15
|
+
@router.get("", response_model=AppConfig)
|
|
16
|
+
async def get_config():
|
|
17
|
+
"""
|
|
18
|
+
Get application configuration required for the frontend.
|
|
19
|
+
This allows dynamic configuration (like API keys) to be passed to the UI.
|
|
20
|
+
"""
|
|
21
|
+
return {
|
|
22
|
+
"typesense": {
|
|
23
|
+
"api_key": settings.typesense_api_key,
|
|
24
|
+
"host": settings.typesense_host,
|
|
25
|
+
"port": settings.typesense_port,
|
|
26
|
+
"protocol": settings.typesense_protocol,
|
|
27
|
+
"collection_name": settings.typesense_collection_name,
|
|
28
|
+
}
|
|
29
|
+
}
|