diveq 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- diveq-0.1.0/LICENSE.txt +21 -0
- diveq-0.1.0/PKG-INFO +146 -0
- diveq-0.1.0/README.md +111 -0
- diveq-0.1.0/pyproject.toml +30 -0
- diveq-0.1.0/src/diveq/__init__.py +8 -0
- diveq-0.1.0/src/diveq/diveq.py +241 -0
- diveq-0.1.0/src/diveq/diveq_detach.py +223 -0
- diveq-0.1.0/src/diveq/product_diveq.py +291 -0
- diveq-0.1.0/src/diveq/product_sf_diveq.py +478 -0
- diveq-0.1.0/src/diveq/residual_diveq.py +295 -0
- diveq-0.1.0/src/diveq/residual_sf_diveq.py +482 -0
- diveq-0.1.0/src/diveq/sf_diveq.py +292 -0
- diveq-0.1.0/src/diveq/sf_diveq_detach.py +267 -0
diveq-0.1.0/LICENSE.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026-present AaltoML
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
diveq-0.1.0/PKG-INFO
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
1
|
+
Metadata-Version: 2.3
|
|
2
|
+
Name: diveq
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: A PyTorch class for end-to-end training of vector quantization codebook in a deep neural network.
|
|
5
|
+
Keywords: deep-learning,pytorch,vector-quantization,machine-learning,vq-vae,tokenization,representation-learning
|
|
6
|
+
Author: Mohammad Hassan Vali
|
|
7
|
+
Author-email: Mohammad Hassan Vali <mohammad.vali@aalto.fi>
|
|
8
|
+
License: MIT License
|
|
9
|
+
|
|
10
|
+
Copyright (c) 2026-present AaltoML
|
|
11
|
+
|
|
12
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
13
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
14
|
+
in the Software without restriction, including without limitation the rights
|
|
15
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
16
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
17
|
+
furnished to do so, subject to the following conditions:
|
|
18
|
+
|
|
19
|
+
The above copyright notice and this permission notice shall be included in all
|
|
20
|
+
copies or substantial portions of the Software.
|
|
21
|
+
|
|
22
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
23
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
24
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
25
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
26
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
27
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
28
|
+
SOFTWARE.
|
|
29
|
+
Requires-Dist: torch>=2.0.0
|
|
30
|
+
Requires-Python: >=3.11
|
|
31
|
+
Project-URL: Repository, https://github.com/AaltoML/DiVeQ_package
|
|
32
|
+
Project-URL: Issues, https://github.com/AaltoML/DiVeQ_package/issues
|
|
33
|
+
Project-URL: Paper, https://arxiv.org/pdf/2509.26469
|
|
34
|
+
Description-Content-Type: text/markdown
|
|
35
|
+
|
|
36
|
+
# Welcome to diveq
|
|
37
|
+
`diveq` (short for differentiable vector quantization) is a tool for implementing and training vector quantization (VQ) in deep neural networks (DNNs), such as a VQ-VAE. It allows end-to-end training of DNNs that contain the non-differentiable VQ module, without any auxiliary losses and hyperparameter tunings. `diveq` is implemented via PyTorch, and it requires `python >= 3.11` and `torch >= 2.0.0` .
|
|
38
|
+
|
|
39
|
+
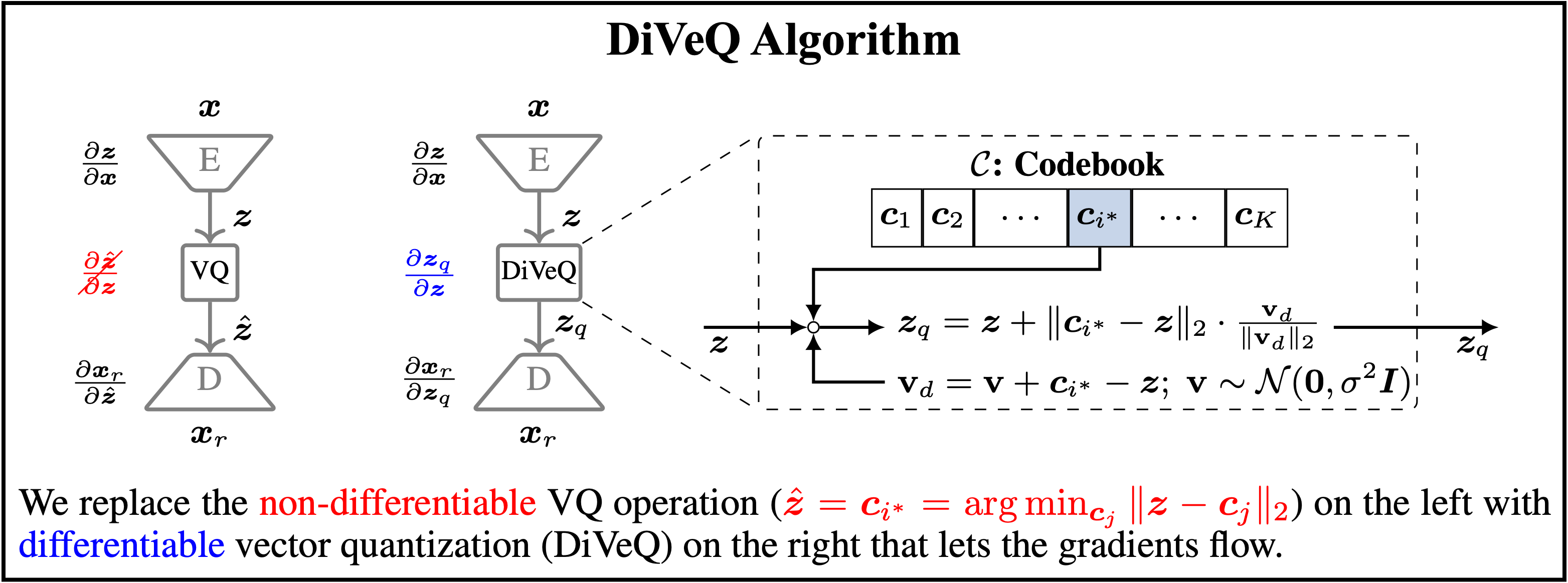
|
|
40
|
+
|
|
41
|
+
`diveq` method is published as a research paper entitled [*"DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick"*](https://arxiv.org/pdf/2509.26469) in the International Conference on Learning Representations (ICLR) in 2026. You can find the original GitHub repository of the paper at [https://github.com/AaltoML/DiVeQ](https://github.com/AaltoML/DiVeQ).
|
|
42
|
+
|
|
43
|
+
`diveq` package includes eight different vector quantization (VQ) methods:
|
|
44
|
+
1. `from diveq import DIVEQ` optimizes the VQ codebook via DiVeQ technique. DiVeQ is the first proposed method in the paper that works as an ordinary VQ by mapping the input to codebook vectors.
|
|
45
|
+
2. `from diveq import SFDIVEQ` optimizes the VQ codebook via Space-Filling DiVeQ technique. SF-DiVeQ is the second proposed method in the paper, different from ordinary VQ in a way that it maps the input to a space-filling curve constructed from codebook vectors.
|
|
46
|
+
|
|
47
|
+
VQ variants that use multiple codebooks for vector quantization, i.e., Residual VQ and Product VQ:
|
|
48
|
+
|
|
49
|
+
3. `from diveq import ResidualDIVEQ` optimizes the Residual VQ codebooks via DiVeQ technique.
|
|
50
|
+
4. `from diveq import ResidualSFDIVEQ` optimizes the Residual VQ codebooks via SF-DiVeQ technique.
|
|
51
|
+
5. `from diveq import ProductDIVEQ` optimizes the Product VQ codebooks via DiVeQ technique.
|
|
52
|
+
6. `from diveq import ProductSFDIVEQ` optimizes the Product VQ codebooks via SF-DiVeQ technique.
|
|
53
|
+
|
|
54
|
+
Variants of DiVeQ and SF-DiVeQ techniques that use deterministic quantization instead of stochastic quantization:
|
|
55
|
+
|
|
56
|
+
7. `from diveq import DIVEQDetach` optimizes the VQ codebook via DiVeQ_Detach technique.
|
|
57
|
+
8. `from diveq import SFDIVEQDetach` optimizes the VQ codebook via SF-DiVeQ_Detach technique.
|
|
58
|
+
|
|
59
|
+
For more details on these eight different VQ methods, please see [the paper](https://arxiv.org/pdf/2509.26469).
|
|
60
|
+
|
|
61
|
+
# Installation
|
|
62
|
+
|
|
63
|
+
You can install `diveq` through `pip` by running:
|
|
64
|
+
|
|
65
|
+
```bash
|
|
66
|
+
pip install diveq
|
|
67
|
+
```
|
|
68
|
+
|
|
69
|
+
After installing `diveq`, you can verify the installation and package details by running:
|
|
70
|
+
|
|
71
|
+
```bash
|
|
72
|
+
python -m pip show diveq
|
|
73
|
+
```
|
|
74
|
+
|
|
75
|
+
# Usage Example
|
|
76
|
+
|
|
77
|
+
Before using `diveq`, you have to install it using `pip install diveq`.
|
|
78
|
+
|
|
79
|
+
Below you see a minimal example of how to import and use the `DIVEQ` optimization method as a vector quantizer in a model.
|
|
80
|
+
|
|
81
|
+
```bash
|
|
82
|
+
from diveq import DIVEQ
|
|
83
|
+
vector_quantizer = DIVEQ(num_embeddings, embedding_dim)
|
|
84
|
+
```
|
|
85
|
+
|
|
86
|
+
- `vector_quantizer` is the vector quantization module that will be used for building the model.
|
|
87
|
+
- `num_embeddings` and `embedding_dim` are the codebook size and dimension of each codebook entry, respectively. In the following, you can find the list of all parameters used in different vector quantization modules incorporated in `diveq` package.
|
|
88
|
+
|
|
89
|
+
In the `example` directory of the [GitHub for `diveq` package](https://github.com/AaltoML/DiVeQ_package), we provide a code example of how vector quantization modules in `diveq` can be used in a vector quantized variational autoencoder (VQ-VAE). You can create the required environment to run the code by running:
|
|
90
|
+
|
|
91
|
+
```bash
|
|
92
|
+
cd example #change directory to the example folder
|
|
93
|
+
conda create --name diveq_example python=3.11
|
|
94
|
+
conda activate diveq_example
|
|
95
|
+
pip install -r requirements.txt
|
|
96
|
+
```
|
|
97
|
+
|
|
98
|
+
Then, you can train the VQ-VAE model by running:
|
|
99
|
+
|
|
100
|
+
```bash
|
|
101
|
+
python train.py
|
|
102
|
+
```
|
|
103
|
+
|
|
104
|
+
# List of Parameters
|
|
105
|
+
Here, we provide the list of parameters that are used as inputs to eight different vector quantization methods included in `diveq` package.
|
|
106
|
+
|
|
107
|
+
- `num_embeddings` (integer): Codebook size or the number of codewords in the codebook.
|
|
108
|
+
- `embedding_dim` (integer): Dimensionality of each codebook entry or codeword.
|
|
109
|
+
- `noise_var` (float): Variance of the directional noise for stochastic *DiVeQ*- and *SF-DiVeQ*-based methods.
|
|
110
|
+
- `replacement_iters` (integer): Number of training iterations to apply codebook replacement.
|
|
111
|
+
- `discard_threshold` (float): Threshold to discard the codebook entries that are used less than this threshold after *replacement_iters* iterations.
|
|
112
|
+
- `perturb_eps` (float): Adjusts perturbation/shift magnitude from used codewords for codebook replacement.
|
|
113
|
+
- `uniform_init` (bool): Whether to use uniform initialization. If False, codebook is initialized from a normal distribution.
|
|
114
|
+
- `verbose` (bool): Whether to print codebook replacement status, i.e., to print how many unused codewords are replaced.
|
|
115
|
+
- `skip_iters` (integer): Number of training iterations to skip quantization (for *SF-DiVeQ* and *SF-DiVeQ_Detach*) or to use *DiVeQ* quantization (for *Residual_SF-DiVeQ* and *Product_SF-DiVeQ*) in the custom initialization.
|
|
116
|
+
- `avg_iters` (integer): Number of recent training iterations to extract latents for custom codebook initialization in Space-Filling Versions.
|
|
117
|
+
- `latents_on_cpu` (bool): Whether to collect latents for custom initialization on CPU. If running out of CUDA memory, set it to True.
|
|
118
|
+
- `allow_warning` (bool): Whether to print the warnings. The warnings will warn if the user inserts unusual values for the parameters.
|
|
119
|
+
- `num_codebooks` (integer): Number of codebooks to be used for quantization in VQ variants of Residual VQ and Product VQ. All the codebooks will have the same size and dimensionality.
|
|
120
|
+
|
|
121
|
+
# Important Notes about Parameters
|
|
122
|
+
|
|
123
|
+
1. **Codebook Replacement:** Note that to prevent *codebook collapse*, we include a codebook replacement function (in cases where it is required) inside different quantization modules. Codebook replacement function is called after each `replacement_iters` training iterations, and it replaces the codewords which are used less than `discard_threshold` with perturbation of actively used codewords which are shifted by `perturb_eps` magnitude. If `verbose=True`, the status of how many unused codewords are replaced will be printed by the module. Note that the number of unused codewords should decrease over training, and it might take a while.
|
|
124
|
+
|
|
125
|
+
2. **Variants of Vector Quantization:** Residual VQ and Product VQ are two variants of vector quantization, which are included in the `diveq` package. These variants utilize multiple codebooks for quantization, where `num_codebooks` determines the number of codebooks used in these VQ variants.
|
|
126
|
+
|
|
127
|
+
3. **Space-Filling Methods:** Quantization methods based on Space-Filling (i.e., *SF-DiVeQ*, *SF-DiVeQ_Detach*, *Residual_SF-DiVeQ*, *Product_SF-DiVeQ*) use a custom initilization. *SF-DiVeQ* and *SF-DiVeQ_Detach* skip quantizing the latents for `skip_iters` training iterations, and initialize the codebook with an average of latents captured from `avg_iters` recent training iterations. After this custom initialization, they start to quantize the latents. *Residual_SF-DiVeQ* and *Product_SF-DiVeQ* work in the same way, but they apply *DiVeQ* for the first `skip_iters` training iterations. Note that if `avg_iters` value is set to a large value, CUDA might run out of memory, as there should be a large pull of latents to be stored for custom initialization. Therefore, the user can set `latents_on_cpu=True` to store the latents on CPU, or set a smaller value for `avg_iters`.
|
|
128
|
+
|
|
129
|
+
4. **Detach Methods:** *DiVeQ_Detach* and *SF-DiVeQ_Detach* methods do not use directional noise. Therefore, they do not need to set the `noise_var` parameter.
|
|
130
|
+
|
|
131
|
+
For further details about different vector quantization methods in the `diveq` package and their corresponding parameters, please see the details provided in the Python codes in `src` directory of the `diveq` package.
|
|
132
|
+
|
|
133
|
+
# Citation
|
|
134
|
+
If this package contributed to your work, please consider citing it:
|
|
135
|
+
|
|
136
|
+
```
|
|
137
|
+
@InProceedings{vali2026diveq,
|
|
138
|
+
title={{DiVeQ}: {D}ifferentiable {V}ector {Q}uantization {U}sing the {R}eparameterization {T}rick},
|
|
139
|
+
author={Vali, Mohammad Hassan and Bäckström, Tom and Solin, Arno},
|
|
140
|
+
booktitle={International Conference on Learning Representations (ICLR)},
|
|
141
|
+
year={2026}
|
|
142
|
+
}
|
|
143
|
+
```
|
|
144
|
+
|
|
145
|
+
# License
|
|
146
|
+
`diveq` was developed by <span property="cc:attributionName">Mohammad Hassan Vali</span>, part of the <a href="https://users.aalto.fi/~asolin/group/" target="_blank">AaltoML research group from Aalto University</a> and is licensed under MIT license.
|
diveq-0.1.0/README.md
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
1
|
+
# Welcome to diveq
|
|
2
|
+
`diveq` (short for differentiable vector quantization) is a tool for implementing and training vector quantization (VQ) in deep neural networks (DNNs), such as a VQ-VAE. It allows end-to-end training of DNNs that contain the non-differentiable VQ module, without any auxiliary losses and hyperparameter tunings. `diveq` is implemented via PyTorch, and it requires `python >= 3.11` and `torch >= 2.0.0` .
|
|
3
|
+
|
|
4
|
+

|
|
5
|
+
|
|
6
|
+
`diveq` method is published as a research paper entitled [*"DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick"*](https://arxiv.org/pdf/2509.26469) in the International Conference on Learning Representations (ICLR) in 2026. You can find the original GitHub repository of the paper at [https://github.com/AaltoML/DiVeQ](https://github.com/AaltoML/DiVeQ).
|
|
7
|
+
|
|
8
|
+
`diveq` package includes eight different vector quantization (VQ) methods:
|
|
9
|
+
1. `from diveq import DIVEQ` optimizes the VQ codebook via DiVeQ technique. DiVeQ is the first proposed method in the paper that works as an ordinary VQ by mapping the input to codebook vectors.
|
|
10
|
+
2. `from diveq import SFDIVEQ` optimizes the VQ codebook via Space-Filling DiVeQ technique. SF-DiVeQ is the second proposed method in the paper, different from ordinary VQ in a way that it maps the input to a space-filling curve constructed from codebook vectors.
|
|
11
|
+
|
|
12
|
+
VQ variants that use multiple codebooks for vector quantization, i.e., Residual VQ and Product VQ:
|
|
13
|
+
|
|
14
|
+
3. `from diveq import ResidualDIVEQ` optimizes the Residual VQ codebooks via DiVeQ technique.
|
|
15
|
+
4. `from diveq import ResidualSFDIVEQ` optimizes the Residual VQ codebooks via SF-DiVeQ technique.
|
|
16
|
+
5. `from diveq import ProductDIVEQ` optimizes the Product VQ codebooks via DiVeQ technique.
|
|
17
|
+
6. `from diveq import ProductSFDIVEQ` optimizes the Product VQ codebooks via SF-DiVeQ technique.
|
|
18
|
+
|
|
19
|
+
Variants of DiVeQ and SF-DiVeQ techniques that use deterministic quantization instead of stochastic quantization:
|
|
20
|
+
|
|
21
|
+
7. `from diveq import DIVEQDetach` optimizes the VQ codebook via DiVeQ_Detach technique.
|
|
22
|
+
8. `from diveq import SFDIVEQDetach` optimizes the VQ codebook via SF-DiVeQ_Detach technique.
|
|
23
|
+
|
|
24
|
+
For more details on these eight different VQ methods, please see [the paper](https://arxiv.org/pdf/2509.26469).
|
|
25
|
+
|
|
26
|
+
# Installation
|
|
27
|
+
|
|
28
|
+
You can install `diveq` through `pip` by running:
|
|
29
|
+
|
|
30
|
+
```bash
|
|
31
|
+
pip install diveq
|
|
32
|
+
```
|
|
33
|
+
|
|
34
|
+
After installing `diveq`, you can verify the installation and package details by running:
|
|
35
|
+
|
|
36
|
+
```bash
|
|
37
|
+
python -m pip show diveq
|
|
38
|
+
```
|
|
39
|
+
|
|
40
|
+
# Usage Example
|
|
41
|
+
|
|
42
|
+
Before using `diveq`, you have to install it using `pip install diveq`.
|
|
43
|
+
|
|
44
|
+
Below you see a minimal example of how to import and use the `DIVEQ` optimization method as a vector quantizer in a model.
|
|
45
|
+
|
|
46
|
+
```bash
|
|
47
|
+
from diveq import DIVEQ
|
|
48
|
+
vector_quantizer = DIVEQ(num_embeddings, embedding_dim)
|
|
49
|
+
```
|
|
50
|
+
|
|
51
|
+
- `vector_quantizer` is the vector quantization module that will be used for building the model.
|
|
52
|
+
- `num_embeddings` and `embedding_dim` are the codebook size and dimension of each codebook entry, respectively. In the following, you can find the list of all parameters used in different vector quantization modules incorporated in `diveq` package.
|
|
53
|
+
|
|
54
|
+
In the `example` directory of the [GitHub for `diveq` package](https://github.com/AaltoML/DiVeQ_package), we provide a code example of how vector quantization modules in `diveq` can be used in a vector quantized variational autoencoder (VQ-VAE). You can create the required environment to run the code by running:
|
|
55
|
+
|
|
56
|
+
```bash
|
|
57
|
+
cd example #change directory to the example folder
|
|
58
|
+
conda create --name diveq_example python=3.11
|
|
59
|
+
conda activate diveq_example
|
|
60
|
+
pip install -r requirements.txt
|
|
61
|
+
```
|
|
62
|
+
|
|
63
|
+
Then, you can train the VQ-VAE model by running:
|
|
64
|
+
|
|
65
|
+
```bash
|
|
66
|
+
python train.py
|
|
67
|
+
```
|
|
68
|
+
|
|
69
|
+
# List of Parameters
|
|
70
|
+
Here, we provide the list of parameters that are used as inputs to eight different vector quantization methods included in `diveq` package.
|
|
71
|
+
|
|
72
|
+
- `num_embeddings` (integer): Codebook size or the number of codewords in the codebook.
|
|
73
|
+
- `embedding_dim` (integer): Dimensionality of each codebook entry or codeword.
|
|
74
|
+
- `noise_var` (float): Variance of the directional noise for stochastic *DiVeQ*- and *SF-DiVeQ*-based methods.
|
|
75
|
+
- `replacement_iters` (integer): Number of training iterations to apply codebook replacement.
|
|
76
|
+
- `discard_threshold` (float): Threshold to discard the codebook entries that are used less than this threshold after *replacement_iters* iterations.
|
|
77
|
+
- `perturb_eps` (float): Adjusts perturbation/shift magnitude from used codewords for codebook replacement.
|
|
78
|
+
- `uniform_init` (bool): Whether to use uniform initialization. If False, codebook is initialized from a normal distribution.
|
|
79
|
+
- `verbose` (bool): Whether to print codebook replacement status, i.e., to print how many unused codewords are replaced.
|
|
80
|
+
- `skip_iters` (integer): Number of training iterations to skip quantization (for *SF-DiVeQ* and *SF-DiVeQ_Detach*) or to use *DiVeQ* quantization (for *Residual_SF-DiVeQ* and *Product_SF-DiVeQ*) in the custom initialization.
|
|
81
|
+
- `avg_iters` (integer): Number of recent training iterations to extract latents for custom codebook initialization in Space-Filling Versions.
|
|
82
|
+
- `latents_on_cpu` (bool): Whether to collect latents for custom initialization on CPU. If running out of CUDA memory, set it to True.
|
|
83
|
+
- `allow_warning` (bool): Whether to print the warnings. The warnings will warn if the user inserts unusual values for the parameters.
|
|
84
|
+
- `num_codebooks` (integer): Number of codebooks to be used for quantization in VQ variants of Residual VQ and Product VQ. All the codebooks will have the same size and dimensionality.
|
|
85
|
+
|
|
86
|
+
# Important Notes about Parameters
|
|
87
|
+
|
|
88
|
+
1. **Codebook Replacement:** Note that to prevent *codebook collapse*, we include a codebook replacement function (in cases where it is required) inside different quantization modules. Codebook replacement function is called after each `replacement_iters` training iterations, and it replaces the codewords which are used less than `discard_threshold` with perturbation of actively used codewords which are shifted by `perturb_eps` magnitude. If `verbose=True`, the status of how many unused codewords are replaced will be printed by the module. Note that the number of unused codewords should decrease over training, and it might take a while.
|
|
89
|
+
|
|
90
|
+
2. **Variants of Vector Quantization:** Residual VQ and Product VQ are two variants of vector quantization, which are included in the `diveq` package. These variants utilize multiple codebooks for quantization, where `num_codebooks` determines the number of codebooks used in these VQ variants.
|
|
91
|
+
|
|
92
|
+
3. **Space-Filling Methods:** Quantization methods based on Space-Filling (i.e., *SF-DiVeQ*, *SF-DiVeQ_Detach*, *Residual_SF-DiVeQ*, *Product_SF-DiVeQ*) use a custom initilization. *SF-DiVeQ* and *SF-DiVeQ_Detach* skip quantizing the latents for `skip_iters` training iterations, and initialize the codebook with an average of latents captured from `avg_iters` recent training iterations. After this custom initialization, they start to quantize the latents. *Residual_SF-DiVeQ* and *Product_SF-DiVeQ* work in the same way, but they apply *DiVeQ* for the first `skip_iters` training iterations. Note that if `avg_iters` value is set to a large value, CUDA might run out of memory, as there should be a large pull of latents to be stored for custom initialization. Therefore, the user can set `latents_on_cpu=True` to store the latents on CPU, or set a smaller value for `avg_iters`.
|
|
93
|
+
|
|
94
|
+
4. **Detach Methods:** *DiVeQ_Detach* and *SF-DiVeQ_Detach* methods do not use directional noise. Therefore, they do not need to set the `noise_var` parameter.
|
|
95
|
+
|
|
96
|
+
For further details about different vector quantization methods in the `diveq` package and their corresponding parameters, please see the details provided in the Python codes in `src` directory of the `diveq` package.
|
|
97
|
+
|
|
98
|
+
# Citation
|
|
99
|
+
If this package contributed to your work, please consider citing it:
|
|
100
|
+
|
|
101
|
+
```
|
|
102
|
+
@InProceedings{vali2026diveq,
|
|
103
|
+
title={{DiVeQ}: {D}ifferentiable {V}ector {Q}uantization {U}sing the {R}eparameterization {T}rick},
|
|
104
|
+
author={Vali, Mohammad Hassan and Bäckström, Tom and Solin, Arno},
|
|
105
|
+
booktitle={International Conference on Learning Representations (ICLR)},
|
|
106
|
+
year={2026}
|
|
107
|
+
}
|
|
108
|
+
```
|
|
109
|
+
|
|
110
|
+
# License
|
|
111
|
+
`diveq` was developed by <span property="cc:attributionName">Mohammad Hassan Vali</span>, part of the <a href="https://users.aalto.fi/~asolin/group/" target="_blank">AaltoML research group from Aalto University</a> and is licensed under MIT license.
|
|
@@ -0,0 +1,30 @@
|
|
|
1
|
+
[project]
|
|
2
|
+
name = "diveq"
|
|
3
|
+
authors = [{name = "Mohammad Hassan Vali", email = "mohammad.vali@aalto.fi"}]
|
|
4
|
+
version = "0.1.0"
|
|
5
|
+
description = "A PyTorch class for end-to-end training of vector quantization codebook in a deep neural network."
|
|
6
|
+
readme = "README.md"
|
|
7
|
+
license = { file = "LICENSE.txt" }
|
|
8
|
+
requires-python = ">=3.11"
|
|
9
|
+
dependencies = [
|
|
10
|
+
"torch>=2.0.0",
|
|
11
|
+
]
|
|
12
|
+
|
|
13
|
+
keywords = [
|
|
14
|
+
"deep-learning",
|
|
15
|
+
"pytorch",
|
|
16
|
+
"vector-quantization",
|
|
17
|
+
"machine-learning",
|
|
18
|
+
"vq-vae",
|
|
19
|
+
"tokenization",
|
|
20
|
+
"representation-learning"
|
|
21
|
+
]
|
|
22
|
+
|
|
23
|
+
[project.urls]
|
|
24
|
+
Repository = "https://github.com/AaltoML/DiVeQ_package"
|
|
25
|
+
Issues = "https://github.com/AaltoML/DiVeQ_package/issues"
|
|
26
|
+
Paper = "https://arxiv.org/pdf/2509.26469"
|
|
27
|
+
|
|
28
|
+
[build-system]
|
|
29
|
+
requires = ["uv_build>=0.9.10,<0.10.0"]
|
|
30
|
+
build-backend = "uv_build"
|
|
@@ -0,0 +1,8 @@
|
|
|
1
|
+
from .diveq import DIVEQ
|
|
2
|
+
from .sf_diveq import SFDIVEQ
|
|
3
|
+
from .diveq_detach import DIVEQDetach
|
|
4
|
+
from .sf_diveq_detach import SFDIVEQDetach
|
|
5
|
+
from .residual_diveq import ResidualDIVEQ
|
|
6
|
+
from .residual_sf_diveq import ResidualSFDIVEQ
|
|
7
|
+
from .product_diveq import ProductDIVEQ
|
|
8
|
+
from .product_sf_diveq import ProductSFDIVEQ
|
|
@@ -0,0 +1,241 @@
|
|
|
1
|
+
import torch
|
|
2
|
+
import torch.nn as nn
|
|
3
|
+
from torch.distributions import normal
|
|
4
|
+
from typing import Tuple
|
|
5
|
+
import warnings
|
|
6
|
+
|
|
7
|
+
class DIVEQ(nn.Module):
|
|
8
|
+
"""
|
|
9
|
+
DiVeQ: Differentiable Vector Quantization (VQ) module that allows end-to-end
|
|
10
|
+
training of VQ-based models without any auxiliary losses or hyperparameter tunings.
|
|
11
|
+
The module encompasses codebook replacement function which discards unused codebook
|
|
12
|
+
entries during training.
|
|
13
|
+
|
|
14
|
+
Args:
|
|
15
|
+
- num_embeddings (int): Codebook size (No. of codewords).
|
|
16
|
+
- embedding_dim (int): Dimensionality of embeddings.
|
|
17
|
+
- noise_var (float): Variance of the directional noise in DiVeQ.
|
|
18
|
+
Recommended noise_var < 1e-2.
|
|
19
|
+
- replacement_iters (int): Replacement interval (number of training iterations
|
|
20
|
+
to apply codebook replacement). Recommended 50 < replacement_iters < 300.
|
|
21
|
+
- discard_threshold (float): Threshold to discard the codebook entries that are
|
|
22
|
+
used less than this threshold after "replacement_iters" iterations.
|
|
23
|
+
Recommended 0.01 < discard_threshold < 0.05. discard_threshold must be in
|
|
24
|
+
the range of [0,1] such that discard_threshold=0.01 means to discard the
|
|
25
|
+
codebook entries which are used less than 1 percent.
|
|
26
|
+
- perturb_eps (float): Adjusts perturbation/shift magnitude from used codewords
|
|
27
|
+
for codebook replacement.
|
|
28
|
+
- uniform_init (bool): Whether to initialize codebook with uniform distribution.
|
|
29
|
+
If False, the codebook is initialized from a normal distribution.
|
|
30
|
+
- allow_warning (bool): Whether to print the warnings.
|
|
31
|
+
- verbose (bool): Whether to print codebook replacement status.
|
|
32
|
+
|
|
33
|
+
Returns:
|
|
34
|
+
- z_q (torch.Tensor): Differentiable quantized input/latent. shape (N, D)
|
|
35
|
+
- indices (torch.Tensor): Selected codebook indices. shape (N, )
|
|
36
|
+
- perplexity (float): Codebook perplexity (average codebook usage)
|
|
37
|
+
"""
|
|
38
|
+
def __init__(
|
|
39
|
+
self,
|
|
40
|
+
num_embeddings: int,
|
|
41
|
+
embedding_dim: int,
|
|
42
|
+
noise_var: float = 0.001,
|
|
43
|
+
replacement_iters: int = 100,
|
|
44
|
+
discard_threshold: float = 0.01,
|
|
45
|
+
perturb_eps: float = 1e-9,
|
|
46
|
+
uniform_init: bool = True,
|
|
47
|
+
allow_warning: bool = True,
|
|
48
|
+
verbose: bool = True,
|
|
49
|
+
):
|
|
50
|
+
super().__init__()
|
|
51
|
+
|
|
52
|
+
self.num_embeddings = num_embeddings
|
|
53
|
+
self.embedding_dim = embedding_dim
|
|
54
|
+
self.noise_var = noise_var
|
|
55
|
+
self.replacement_iters = replacement_iters
|
|
56
|
+
self.discard_threshold = discard_threshold
|
|
57
|
+
self.perturb_eps = perturb_eps
|
|
58
|
+
self.uniform_init = uniform_init
|
|
59
|
+
self.allow_warning = allow_warning
|
|
60
|
+
self.verbose = verbose
|
|
61
|
+
|
|
62
|
+
self._check_constraints()
|
|
63
|
+
|
|
64
|
+
# ---------------- User warnings ----------------
|
|
65
|
+
if allow_warning:
|
|
66
|
+
if noise_var > 0.01:
|
|
67
|
+
warnings.warn(f"`noise_var` is set to {noise_var}, which is"
|
|
68
|
+
f" quite large. Values > 0.01 may overshoot"
|
|
69
|
+
f" nearest-neighbor mapping.", UserWarning)
|
|
70
|
+
if replacement_iters < 50:
|
|
71
|
+
warnings.warn(f"`replacement_iters` is set to"
|
|
72
|
+
f" {replacement_iters}, which is quite small. Values < 50"
|
|
73
|
+
f" may cause too early and frequent codebook"
|
|
74
|
+
f" replacements.", UserWarning)
|
|
75
|
+
elif replacement_iters > 300:
|
|
76
|
+
warnings.warn(f"`replacement_iters` is set to"
|
|
77
|
+
f" {replacement_iters}, which is quite large."
|
|
78
|
+
f" Values > 300 may cause too late and sporadic codebook"
|
|
79
|
+
f" replacements.", UserWarning)
|
|
80
|
+
|
|
81
|
+
if discard_threshold > 0.05:
|
|
82
|
+
warnings.warn(f"`discard_threshold` is set to"
|
|
83
|
+
f" {discard_threshold}, which is quite large."
|
|
84
|
+
f" Values > 0.05 may discard a portion of suitable but"
|
|
85
|
+
f" rarely used codewords.", UserWarning)
|
|
86
|
+
|
|
87
|
+
if perturb_eps > 1e-6:
|
|
88
|
+
warnings.warn(f"`perturb_eps` is set to {perturb_eps}, which"
|
|
89
|
+
f" is quite large. Values > 1e-6 may cause big"
|
|
90
|
+
f" perturbation/shift from used codewords.", UserWarning)
|
|
91
|
+
|
|
92
|
+
# ---------------- Codebook initialization ----------------
|
|
93
|
+
if uniform_init:
|
|
94
|
+
codebook = (torch.rand((self.num_embeddings, self.embedding_dim))
|
|
95
|
+
* (1 / self.num_embeddings))
|
|
96
|
+
else:
|
|
97
|
+
codebook = (torch.randn((self.num_embeddings, self.embedding_dim))
|
|
98
|
+
* (1 / self.num_embeddings))
|
|
99
|
+
|
|
100
|
+
self.codebook = torch.nn.Parameter(codebook, requires_grad=True)
|
|
101
|
+
|
|
102
|
+
# ---------------- Tensors used for codebook replacement ----------------
|
|
103
|
+
self.register_buffer("codebook_usage", torch.zeros(self.num_embeddings,
|
|
104
|
+
dtype=torch.int32))
|
|
105
|
+
self.register_buffer("iter_counter", torch.zeros(1, dtype=torch.int32))
|
|
106
|
+
|
|
107
|
+
# ---------------- Forward pass (Core API) ----------------
|
|
108
|
+
def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, float]:
|
|
109
|
+
"""
|
|
110
|
+
Args:
|
|
111
|
+
- z (torch.Tensor): input/latent. shape (N, D)
|
|
112
|
+
|
|
113
|
+
Returns:
|
|
114
|
+
- z_q (torch.Tensor): Differentiable quantized input/latent. shape (N, D)
|
|
115
|
+
- indices (torch.Tensor): Selected codebook indices. shape (N, )
|
|
116
|
+
- perplexity (float): Codebook perplexity (average codebook usage).
|
|
117
|
+
"""
|
|
118
|
+
self._check_input(z)
|
|
119
|
+
|
|
120
|
+
# Calculate distances
|
|
121
|
+
distances = (torch.sum(z.pow(2), dim=1, keepdim=True)
|
|
122
|
+
+ torch.sum(self.codebook.pow(2), dim=1)
|
|
123
|
+
- 2 * torch.matmul(z, self.codebook.t()))
|
|
124
|
+
|
|
125
|
+
indices = torch.argmin(distances, dim=1)
|
|
126
|
+
|
|
127
|
+
z_hard_quantized = self.codebook[indices] # Non-differentiable quantized input
|
|
128
|
+
|
|
129
|
+
direction = z_hard_quantized - z
|
|
130
|
+
random_vectors = (normal.Normal(0, self.noise_var).sample(z.shape)
|
|
131
|
+
.to(z.device) + direction)
|
|
132
|
+
normalized = random_vectors / torch.linalg.norm(random_vectors, dim=1,
|
|
133
|
+
keepdim=True).clamp_min(1e-12)
|
|
134
|
+
error_magnitude = torch.linalg.norm(z_hard_quantized - z, dim=1, keepdim=True)
|
|
135
|
+
|
|
136
|
+
vq_error = error_magnitude * normalized.detach()
|
|
137
|
+
z_q = z + vq_error # Differentiable quantized input
|
|
138
|
+
|
|
139
|
+
# Perplexity Computation
|
|
140
|
+
perplexity = self._compute_perplexity(indices)
|
|
141
|
+
|
|
142
|
+
# Track used indices for codebook replacement
|
|
143
|
+
with torch.no_grad():
|
|
144
|
+
self.codebook_usage[indices] += 1
|
|
145
|
+
self.iter_counter += 1
|
|
146
|
+
if self.iter_counter.item() % self.replacement_iters == 0:
|
|
147
|
+
self._replace_unused_entries() # Applies codebook replacement
|
|
148
|
+
|
|
149
|
+
return z_q, indices, perplexity
|
|
150
|
+
|
|
151
|
+
# ---------------- Quantization for Inference ----------------
|
|
152
|
+
@torch.no_grad()
|
|
153
|
+
def inference(self, z: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, float]:
|
|
154
|
+
"""
|
|
155
|
+
Deterministic hard quantization by mapping the input to the nearest codeword.
|
|
156
|
+
Args:
|
|
157
|
+
- z (torch.Tensor): input/latent. shape (N, D)
|
|
158
|
+
|
|
159
|
+
Returns:
|
|
160
|
+
- z_q_hard (torch.Tensor): Hard quantized input/latent. shape (N, D)
|
|
161
|
+
- indices (torch.Tensor): Selected codebook indices. shape (N, )
|
|
162
|
+
- perplexity (float): Codebook perplexity (average codebook usage).
|
|
163
|
+
"""
|
|
164
|
+
self._check_input(z)
|
|
165
|
+
distances = (torch.sum(z.pow(2), dim=1, keepdim=True)
|
|
166
|
+
+ torch.sum(self.codebook.pow(2), dim=1)
|
|
167
|
+
- 2.0 * torch.matmul(z, self.codebook.t()))
|
|
168
|
+
indices = torch.argmin(distances, dim=1)
|
|
169
|
+
perplexity = self._compute_perplexity(indices)
|
|
170
|
+
z_q_hard = self.codebook[indices]
|
|
171
|
+
return z_q_hard, indices, perplexity
|
|
172
|
+
|
|
173
|
+
# ---------------- Utility functions ----------------
|
|
174
|
+
def _check_constraints(self,) -> None:
|
|
175
|
+
if self.noise_var <= 0.0:
|
|
176
|
+
raise ValueError("`noise_var` must be a positive float value. To have more"
|
|
177
|
+
" precise nearest-neighbor assignments, it is recommended"
|
|
178
|
+
" that noise_var < 1e-2.")
|
|
179
|
+
if (self.replacement_iters <= 0) or (type(self.replacement_iters) is not int):
|
|
180
|
+
raise ValueError("`replacement_iters` must be a positive integer value."
|
|
181
|
+
" It is recommended that 50 < replacement_iters < 300.")
|
|
182
|
+
if (self.discard_threshold < 0.0) or (self.discard_threshold > 1.0):
|
|
183
|
+
raise ValueError("`discard_threshold` must be in the range of [0,1]. It is"
|
|
184
|
+
" recommended that 0.01 < discard_threshold < 0.05,"
|
|
185
|
+
" such that discard_threshold=0.01 means to discard the"
|
|
186
|
+
" codebook entries which are used less than 1 percent.")
|
|
187
|
+
|
|
188
|
+
def _check_input(self, z: torch.Tensor) -> None:
|
|
189
|
+
if z.ndim != 2:
|
|
190
|
+
raise ValueError("DiVeQ input must have the shape of (N, D), where N is"
|
|
191
|
+
" the No. of input samples,and D is the embedding"
|
|
192
|
+
" dimensionality.")
|
|
193
|
+
if z.size(1) != self.embedding_dim:
|
|
194
|
+
raise ValueError(f"DiVeQ input.shape[1] must match the embedding"
|
|
195
|
+
f" dimensionality that is {self.embedding_dim}.")
|
|
196
|
+
|
|
197
|
+
def _compute_perplexity(self, indices: torch.Tensor) -> float:
|
|
198
|
+
encodings = torch.zeros(indices.shape[0], self.num_embeddings,
|
|
199
|
+
device=indices.device)
|
|
200
|
+
encodings.scatter_(1, indices.unsqueeze(1), 1)
|
|
201
|
+
avg_probs = torch.mean(encodings, dim=0)
|
|
202
|
+
perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
|
|
203
|
+
return perplexity.item()
|
|
204
|
+
|
|
205
|
+
def _replace_unused_entries(self) -> None:
|
|
206
|
+
with torch.no_grad():
|
|
207
|
+
usage_ratio = self.codebook_usage / self.replacement_iters
|
|
208
|
+
unused_indices = torch.where(usage_ratio < self.discard_threshold)[0]
|
|
209
|
+
used_indices = torch.where(usage_ratio >= self.discard_threshold)[0]
|
|
210
|
+
|
|
211
|
+
if unused_indices.numel() == 0 or used_indices.numel() == 0:
|
|
212
|
+
self.codebook_usage.zero_()
|
|
213
|
+
return
|
|
214
|
+
|
|
215
|
+
unused_count = unused_indices.numel()
|
|
216
|
+
used_probs = self.codebook_usage[used_indices] / torch.sum(
|
|
217
|
+
self.codebook_usage[used_indices])
|
|
218
|
+
randomly_sampled_indices = used_probs.multinomial(num_samples=unused_count,
|
|
219
|
+
replacement=True)
|
|
220
|
+
sampled_indices = used_indices[randomly_sampled_indices]
|
|
221
|
+
used_codebooks = self.codebook[sampled_indices].clone()
|
|
222
|
+
|
|
223
|
+
self.codebook[unused_indices] = (used_codebooks +
|
|
224
|
+
self.perturb_eps * torch.randn_like(used_codebooks)).clone()
|
|
225
|
+
self.codebook_usage.zero_()
|
|
226
|
+
|
|
227
|
+
if self.verbose:
|
|
228
|
+
print("\n***** Replaced " + str(unused_count) + " codewords *****")
|
|
229
|
+
|
|
230
|
+
def extra_repr(self) -> str:
|
|
231
|
+
return (
|
|
232
|
+
f"num_embeddings={self.num_embeddings}, "
|
|
233
|
+
f"embedding_dim={self.embedding_dim}, "
|
|
234
|
+
f"noise_var={self.noise_var}, "
|
|
235
|
+
f"replacement_iters={self.replacement_iters}, "
|
|
236
|
+
f"discard_threshold={self.discard_threshold}, "
|
|
237
|
+
f"perturb_eps={self.perturb_eps}, "
|
|
238
|
+
f"uniform_init={self.uniform_init}, "
|
|
239
|
+
f"allow_warning={self.allow_warning}, "
|
|
240
|
+
f"verbose={self.verbose}"
|
|
241
|
+
)
|