coxstream 0.1.0__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- coxstream-0.1.0/LICENSE +21 -0
- coxstream-0.1.0/PKG-INFO +164 -0
- coxstream-0.1.0/README.md +139 -0
- coxstream-0.1.0/pyproject.toml +45 -0
- coxstream-0.1.0/setup.cfg +4 -0
- coxstream-0.1.0/setup.py +38 -0
- coxstream-0.1.0/src/coxstream/__init__.py +18 -0
- coxstream-0.1.0/src/coxstream/_kernel.c +30747 -0
- coxstream-0.1.0/src/coxstream/_kernel.pyi +45 -0
- coxstream-0.1.0/src/coxstream/_kernel.pyx +192 -0
- coxstream-0.1.0/src/coxstream/coxstream.py +298 -0
- coxstream-0.1.0/src/coxstream.egg-info/PKG-INFO +164 -0
- coxstream-0.1.0/src/coxstream.egg-info/SOURCES.txt +15 -0
- coxstream-0.1.0/src/coxstream.egg-info/dependency_links.txt +1 -0
- coxstream-0.1.0/src/coxstream.egg-info/requires.txt +7 -0
- coxstream-0.1.0/src/coxstream.egg-info/top_level.txt +1 -0
- coxstream-0.1.0/tests/test_coxstream.py +176 -0
coxstream-0.1.0/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
1
|
+
MIT License
|
|
2
|
+
|
|
3
|
+
Copyright (c) 2026 Tommy Carstensen
|
|
4
|
+
|
|
5
|
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
6
|
+
of this software and associated documentation files (the "Software"), to deal
|
|
7
|
+
in the Software without restriction, including without limitation the rights
|
|
8
|
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
9
|
+
copies of the Software, and to permit persons to whom the Software is
|
|
10
|
+
furnished to do so, subject to the following conditions:
|
|
11
|
+
|
|
12
|
+
The above copyright notice and this permission notice shall be included in all
|
|
13
|
+
copies or substantial portions of the Software.
|
|
14
|
+
|
|
15
|
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
16
|
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
17
|
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
18
|
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
19
|
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
20
|
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
21
|
+
SOFTWARE.
|
coxstream-0.1.0/PKG-INFO
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
1
|
+
Metadata-Version: 2.4
|
|
2
|
+
Name: coxstream
|
|
3
|
+
Version: 0.1.0
|
|
4
|
+
Summary: Exact out-of-core Cox proportional hazards regression via streaming Newton-Raphson
|
|
5
|
+
Author-email: Tommy Carstensen <zenodo@tommycarstensen.com>
|
|
6
|
+
License-Expression: MIT
|
|
7
|
+
Project-URL: Homepage, https://github.com/tommycarstensen/coxstream
|
|
8
|
+
Project-URL: Repository, https://github.com/tommycarstensen/coxstream
|
|
9
|
+
Project-URL: Issues, https://github.com/tommycarstensen/coxstream/issues
|
|
10
|
+
Keywords: survival analysis,cox proportional hazards,out-of-core,streaming,epidemiology,statistics
|
|
11
|
+
Classifier: Development Status :: 3 - Alpha
|
|
12
|
+
Classifier: Intended Audience :: Science/Research
|
|
13
|
+
Classifier: Programming Language :: Python :: 3
|
|
14
|
+
Classifier: Topic :: Scientific/Engineering :: Bio-Informatics
|
|
15
|
+
Classifier: Topic :: Scientific/Engineering :: Medical Science Apps.
|
|
16
|
+
Requires-Python: >=3.10
|
|
17
|
+
Description-Content-Type: text/markdown
|
|
18
|
+
License-File: LICENSE
|
|
19
|
+
Requires-Dist: numpy>=1.24
|
|
20
|
+
Provides-Extra: parquet
|
|
21
|
+
Requires-Dist: pyarrow>=14; extra == "parquet"
|
|
22
|
+
Provides-Extra: test
|
|
23
|
+
Requires-Dist: pytest>=7; extra == "test"
|
|
24
|
+
Dynamic: license-file
|
|
25
|
+
|
|
26
|
+
# coxstream
|
|
27
|
+
|
|
28
|
+
**Exact out-of-core Cox proportional hazards regression via streaming
|
|
29
|
+
Newton-Raphson.**
|
|
30
|
+
|
|
31
|
+
[](https://pypi.org/project/coxstream/)
|
|
32
|
+
<!-- DOI badge: uncomment once the Zenodo record exists.
|
|
33
|
+
[](https://doi.org/TODO)
|
|
34
|
+
-->
|
|
35
|
+
|
|
36
|
+
Standard CoxPH solvers (`lifelines`, `scikit-survival`, R `survival`) load the
|
|
37
|
+
full cohort into memory before fitting, so on registry-scale data they exhaust
|
|
38
|
+
RAM long before the computation is hard. `coxstream` computes the **exact** Efron
|
|
39
|
+
partial-likelihood estimate by streaming a single time-sorted pass over the data
|
|
40
|
+
per Newton-Raphson iteration, holding only `O(p^2)` state for `p` covariates.
|
|
41
|
+
Working memory is therefore **independent of the number of observations `n`**:
|
|
42
|
+
the model fits on a workstation even when the cohort is far larger than RAM.
|
|
43
|
+
|
|
44
|
+
The streamed estimate *is* the in-memory maximum-likelihood estimate, and the
|
|
45
|
+
Efron tie correction is carried across chunk boundaries, so heavily tied data
|
|
46
|
+
are handled exactly.
|
|
47
|
+
|
|
48
|
+
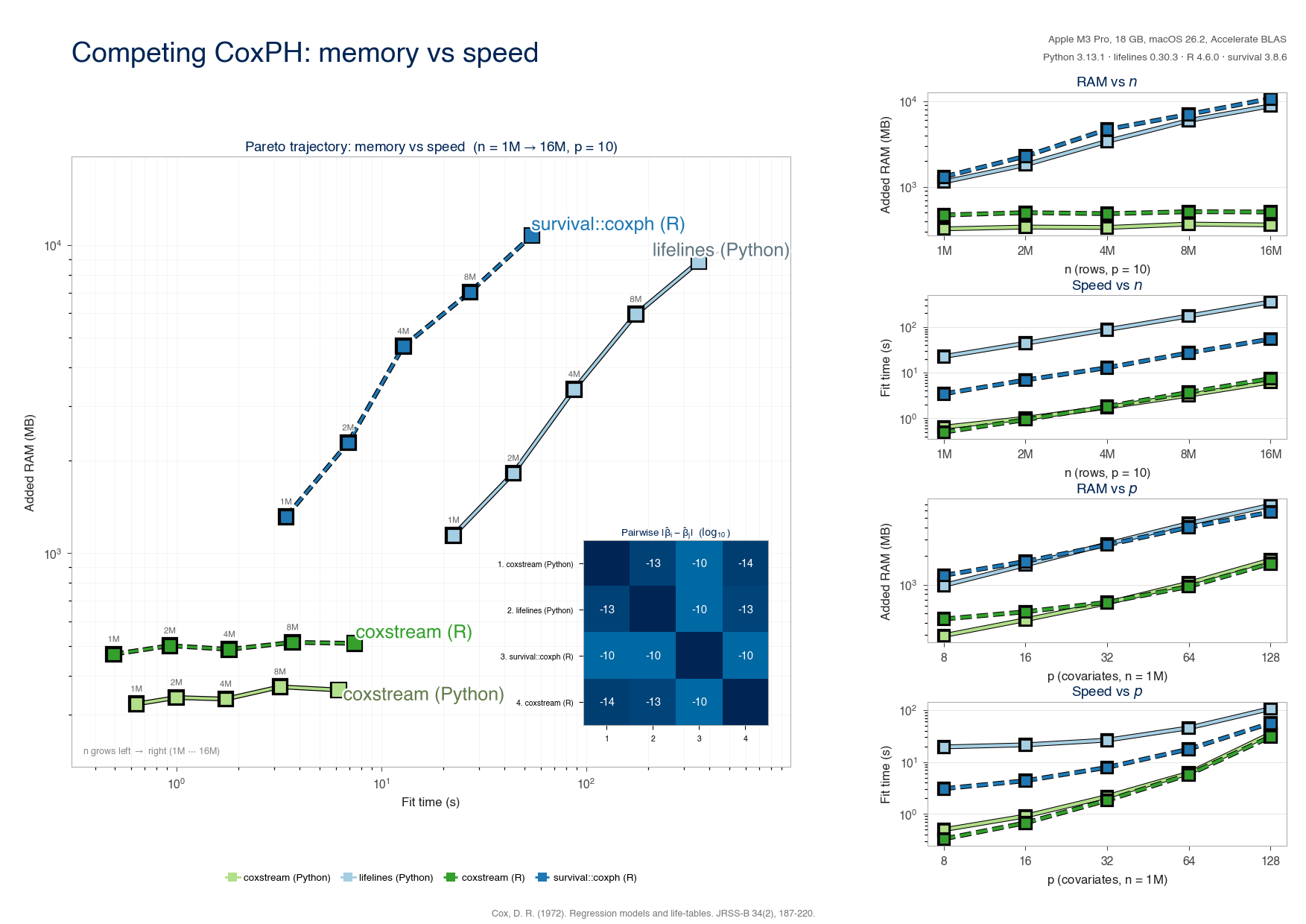
|
|
49
|
+
|
|
50
|
+
*Memory vs. speed against `lifelines` and R `survival::coxph`: coxstream's peak
|
|
51
|
+
RAM stays flat in the number of rows while in-memory solvers grow with the
|
|
52
|
+
cohort, at matching coefficients. See the accompanying paper for the full
|
|
53
|
+
methodology.*
|
|
54
|
+
|
|
55
|
+
## Install
|
|
56
|
+
|
|
57
|
+
```bash
|
|
58
|
+
pip install coxstream # core (numpy only)
|
|
59
|
+
pip install coxstream[parquet] # + out-of-core fit_parquet (pyarrow)
|
|
60
|
+
```
|
|
61
|
+
|
|
62
|
+
The package builds a small Cython kernel, so a C compiler is required.
|
|
63
|
+
|
|
64
|
+
## Usage
|
|
65
|
+
|
|
66
|
+
In memory:
|
|
67
|
+
|
|
68
|
+
```python
|
|
69
|
+
import numpy as np
|
|
70
|
+
from coxstream import CoxStream
|
|
71
|
+
|
|
72
|
+
model = CoxStream().fit(durations, events, X, feature_names=names)
|
|
73
|
+
print(model.coef_, model.n_iter_)
|
|
74
|
+
```
|
|
75
|
+
|
|
76
|
+
Out of core, from a Parquet file **pre-sorted by descending event time** (never
|
|
77
|
+
materialises the cohort):
|
|
78
|
+
|
|
79
|
+
```python
|
|
80
|
+
from coxstream import CoxStream
|
|
81
|
+
|
|
82
|
+
# The file must already be sorted by duration DESC. `fit_parquet` verifies this
|
|
83
|
+
# from the Parquet footer statistics alone (no full pass) and rejects a file
|
|
84
|
+
# that is out of order; pass assume_sorted=True to skip the check.
|
|
85
|
+
#
|
|
86
|
+
# Sort it once with an out-of-core sorter -- both spill to disk, so they handle
|
|
87
|
+
# a cohort larger than RAM (a sort-engine benchmark found these the fastest):
|
|
88
|
+
# duckdb: COPY (SELECT * FROM 'cohort.parquet' ORDER BY duration DESC)
|
|
89
|
+
# TO 'cohort_desc.parquet' (FORMAT PARQUET);
|
|
90
|
+
# polars: (pl.scan_parquet("cohort.parquet")
|
|
91
|
+
# .sort("duration", descending=True)
|
|
92
|
+
# .sink_parquet("cohort_desc.parquet"))
|
|
93
|
+
# R: duckdb via its R client runs the same COPY ... ORDER BY DESC.
|
|
94
|
+
# If the cohort fits in RAM, skip the file and call .fit, which sorts for you.
|
|
95
|
+
|
|
96
|
+
model = CoxStream().fit_parquet(
|
|
97
|
+
"cohort_desc.parquet",
|
|
98
|
+
duration_col="duration",
|
|
99
|
+
event_col="event",
|
|
100
|
+
covariate_cols=["age_std", "sex", "treatment"],
|
|
101
|
+
)
|
|
102
|
+
print(model.coef_)
|
|
103
|
+
```
|
|
104
|
+
|
|
105
|
+
To validate a file's order ahead of time -- a dry run, e.g. a CI or pipeline
|
|
106
|
+
gate right after you sort and before a long fit -- call `check_sorted`, which
|
|
107
|
+
runs the same footer-only check without fitting and raises on a file that is
|
|
108
|
+
provably out of order:
|
|
109
|
+
|
|
110
|
+
```python
|
|
111
|
+
from coxstream import check_sorted
|
|
112
|
+
|
|
113
|
+
check_sorted("cohort_desc.parquet", duration_col="duration") # raises if unsorted
|
|
114
|
+
```
|
|
115
|
+
|
|
116
|
+
It doubles as a shell gate -- it exits non-zero on an out-of-order file, so a
|
|
117
|
+
pipeline step can fail fast without a bespoke CLI:
|
|
118
|
+
|
|
119
|
+
```bash
|
|
120
|
+
python -c "import coxstream; coxstream.check_sorted('cohort_desc.parquet', 'duration')"
|
|
121
|
+
```
|
|
122
|
+
|
|
123
|
+
## Validation
|
|
124
|
+
|
|
125
|
+
`coxstream` is verified against `lifelines` and R `survival::coxph`:
|
|
126
|
+
|
|
127
|
+
- It reproduces the in-memory maximum-likelihood estimate to **machine
|
|
128
|
+
precision** on synthetic data.
|
|
129
|
+
- On the heavily tied Synthea 100K cohort (51 % of event times tied) it matches
|
|
130
|
+
`lifelines` to ~`1e-6`.
|
|
131
|
+
- Peak resident memory is flat in `n` while in-memory solvers grow with the
|
|
132
|
+
cohort and eventually exhaust RAM.
|
|
133
|
+
|
|
134
|
+
The package's own test suite is dependency-free: it checks exactness against a
|
|
135
|
+
self-contained plain-numpy Cox Newton-Raphson reference. The cross-checks
|
|
136
|
+
against `lifelines` and R `survival::coxph` above live in the accompanying
|
|
137
|
+
benchmark and paper.
|
|
138
|
+
|
|
139
|
+
The methodology and full results are in the accompanying paper (see
|
|
140
|
+
[Citation](#citation)).
|
|
141
|
+
|
|
142
|
+
## Scope
|
|
143
|
+
|
|
144
|
+
`coxstream` implements the exact Efron partial likelihood for large-`n`,
|
|
145
|
+
modest-`p` tabular survival data. It is a focused estimator, not a full survival
|
|
146
|
+
suite: it does not provide baseline-hazard estimation, time-varying covariates,
|
|
147
|
+
or proportional-hazards diagnostics.
|
|
148
|
+
|
|
149
|
+
## Testing
|
|
150
|
+
|
|
151
|
+
```bash
|
|
152
|
+
pip install -e '.[test]' # core suite (numpy only)
|
|
153
|
+
pip install -e '.[test,parquet]' # + the out-of-core fit_parquet test
|
|
154
|
+
pytest
|
|
155
|
+
```
|
|
156
|
+
|
|
157
|
+
## Citation
|
|
158
|
+
|
|
159
|
+
If you use `coxstream`, please cite it via the metadata in
|
|
160
|
+
[`CITATION.cff`](CITATION.cff).
|
|
161
|
+
|
|
162
|
+
## License
|
|
163
|
+
|
|
164
|
+
MIT. See [LICENSE](LICENSE).
|
|
@@ -0,0 +1,139 @@
|
|
|
1
|
+
# coxstream
|
|
2
|
+
|
|
3
|
+
**Exact out-of-core Cox proportional hazards regression via streaming
|
|
4
|
+
Newton-Raphson.**
|
|
5
|
+
|
|
6
|
+
[](https://pypi.org/project/coxstream/)
|
|
7
|
+
<!-- DOI badge: uncomment once the Zenodo record exists.
|
|
8
|
+
[](https://doi.org/TODO)
|
|
9
|
+
-->
|
|
10
|
+
|
|
11
|
+
Standard CoxPH solvers (`lifelines`, `scikit-survival`, R `survival`) load the
|
|
12
|
+
full cohort into memory before fitting, so on registry-scale data they exhaust
|
|
13
|
+
RAM long before the computation is hard. `coxstream` computes the **exact** Efron
|
|
14
|
+
partial-likelihood estimate by streaming a single time-sorted pass over the data
|
|
15
|
+
per Newton-Raphson iteration, holding only `O(p^2)` state for `p` covariates.
|
|
16
|
+
Working memory is therefore **independent of the number of observations `n`**:
|
|
17
|
+
the model fits on a workstation even when the cohort is far larger than RAM.
|
|
18
|
+
|
|
19
|
+
The streamed estimate *is* the in-memory maximum-likelihood estimate, and the
|
|
20
|
+
Efron tie correction is carried across chunk boundaries, so heavily tied data
|
|
21
|
+
are handled exactly.
|
|
22
|
+
|
|
23
|
+

|
|
24
|
+
|
|
25
|
+
*Memory vs. speed against `lifelines` and R `survival::coxph`: coxstream's peak
|
|
26
|
+
RAM stays flat in the number of rows while in-memory solvers grow with the
|
|
27
|
+
cohort, at matching coefficients. See the accompanying paper for the full
|
|
28
|
+
methodology.*
|
|
29
|
+
|
|
30
|
+
## Install
|
|
31
|
+
|
|
32
|
+
```bash
|
|
33
|
+
pip install coxstream # core (numpy only)
|
|
34
|
+
pip install coxstream[parquet] # + out-of-core fit_parquet (pyarrow)
|
|
35
|
+
```
|
|
36
|
+
|
|
37
|
+
The package builds a small Cython kernel, so a C compiler is required.
|
|
38
|
+
|
|
39
|
+
## Usage
|
|
40
|
+
|
|
41
|
+
In memory:
|
|
42
|
+
|
|
43
|
+
```python
|
|
44
|
+
import numpy as np
|
|
45
|
+
from coxstream import CoxStream
|
|
46
|
+
|
|
47
|
+
model = CoxStream().fit(durations, events, X, feature_names=names)
|
|
48
|
+
print(model.coef_, model.n_iter_)
|
|
49
|
+
```
|
|
50
|
+
|
|
51
|
+
Out of core, from a Parquet file **pre-sorted by descending event time** (never
|
|
52
|
+
materialises the cohort):
|
|
53
|
+
|
|
54
|
+
```python
|
|
55
|
+
from coxstream import CoxStream
|
|
56
|
+
|
|
57
|
+
# The file must already be sorted by duration DESC. `fit_parquet` verifies this
|
|
58
|
+
# from the Parquet footer statistics alone (no full pass) and rejects a file
|
|
59
|
+
# that is out of order; pass assume_sorted=True to skip the check.
|
|
60
|
+
#
|
|
61
|
+
# Sort it once with an out-of-core sorter -- both spill to disk, so they handle
|
|
62
|
+
# a cohort larger than RAM (a sort-engine benchmark found these the fastest):
|
|
63
|
+
# duckdb: COPY (SELECT * FROM 'cohort.parquet' ORDER BY duration DESC)
|
|
64
|
+
# TO 'cohort_desc.parquet' (FORMAT PARQUET);
|
|
65
|
+
# polars: (pl.scan_parquet("cohort.parquet")
|
|
66
|
+
# .sort("duration", descending=True)
|
|
67
|
+
# .sink_parquet("cohort_desc.parquet"))
|
|
68
|
+
# R: duckdb via its R client runs the same COPY ... ORDER BY DESC.
|
|
69
|
+
# If the cohort fits in RAM, skip the file and call .fit, which sorts for you.
|
|
70
|
+
|
|
71
|
+
model = CoxStream().fit_parquet(
|
|
72
|
+
"cohort_desc.parquet",
|
|
73
|
+
duration_col="duration",
|
|
74
|
+
event_col="event",
|
|
75
|
+
covariate_cols=["age_std", "sex", "treatment"],
|
|
76
|
+
)
|
|
77
|
+
print(model.coef_)
|
|
78
|
+
```
|
|
79
|
+
|
|
80
|
+
To validate a file's order ahead of time -- a dry run, e.g. a CI or pipeline
|
|
81
|
+
gate right after you sort and before a long fit -- call `check_sorted`, which
|
|
82
|
+
runs the same footer-only check without fitting and raises on a file that is
|
|
83
|
+
provably out of order:
|
|
84
|
+
|
|
85
|
+
```python
|
|
86
|
+
from coxstream import check_sorted
|
|
87
|
+
|
|
88
|
+
check_sorted("cohort_desc.parquet", duration_col="duration") # raises if unsorted
|
|
89
|
+
```
|
|
90
|
+
|
|
91
|
+
It doubles as a shell gate -- it exits non-zero on an out-of-order file, so a
|
|
92
|
+
pipeline step can fail fast without a bespoke CLI:
|
|
93
|
+
|
|
94
|
+
```bash
|
|
95
|
+
python -c "import coxstream; coxstream.check_sorted('cohort_desc.parquet', 'duration')"
|
|
96
|
+
```
|
|
97
|
+
|
|
98
|
+
## Validation
|
|
99
|
+
|
|
100
|
+
`coxstream` is verified against `lifelines` and R `survival::coxph`:
|
|
101
|
+
|
|
102
|
+
- It reproduces the in-memory maximum-likelihood estimate to **machine
|
|
103
|
+
precision** on synthetic data.
|
|
104
|
+
- On the heavily tied Synthea 100K cohort (51 % of event times tied) it matches
|
|
105
|
+
`lifelines` to ~`1e-6`.
|
|
106
|
+
- Peak resident memory is flat in `n` while in-memory solvers grow with the
|
|
107
|
+
cohort and eventually exhaust RAM.
|
|
108
|
+
|
|
109
|
+
The package's own test suite is dependency-free: it checks exactness against a
|
|
110
|
+
self-contained plain-numpy Cox Newton-Raphson reference. The cross-checks
|
|
111
|
+
against `lifelines` and R `survival::coxph` above live in the accompanying
|
|
112
|
+
benchmark and paper.
|
|
113
|
+
|
|
114
|
+
The methodology and full results are in the accompanying paper (see
|
|
115
|
+
[Citation](#citation)).
|
|
116
|
+
|
|
117
|
+
## Scope
|
|
118
|
+
|
|
119
|
+
`coxstream` implements the exact Efron partial likelihood for large-`n`,
|
|
120
|
+
modest-`p` tabular survival data. It is a focused estimator, not a full survival
|
|
121
|
+
suite: it does not provide baseline-hazard estimation, time-varying covariates,
|
|
122
|
+
or proportional-hazards diagnostics.
|
|
123
|
+
|
|
124
|
+
## Testing
|
|
125
|
+
|
|
126
|
+
```bash
|
|
127
|
+
pip install -e '.[test]' # core suite (numpy only)
|
|
128
|
+
pip install -e '.[test,parquet]' # + the out-of-core fit_parquet test
|
|
129
|
+
pytest
|
|
130
|
+
```
|
|
131
|
+
|
|
132
|
+
## Citation
|
|
133
|
+
|
|
134
|
+
If you use `coxstream`, please cite it via the metadata in
|
|
135
|
+
[`CITATION.cff`](CITATION.cff).
|
|
136
|
+
|
|
137
|
+
## License
|
|
138
|
+
|
|
139
|
+
MIT. See [LICENSE](LICENSE).
|
|
@@ -0,0 +1,45 @@
|
|
|
1
|
+
[build-system]
|
|
2
|
+
requires = ["setuptools>=64", "Cython>=3.0", "numpy>=1.24"]
|
|
3
|
+
build-backend = "setuptools.build_meta"
|
|
4
|
+
|
|
5
|
+
[project]
|
|
6
|
+
name = "coxstream"
|
|
7
|
+
version = "0.1.0"
|
|
8
|
+
description = "Exact out-of-core Cox proportional hazards regression via streaming Newton-Raphson"
|
|
9
|
+
readme = "README.md"
|
|
10
|
+
license = "MIT"
|
|
11
|
+
authors = [{ name = "Tommy Carstensen", email = "zenodo@tommycarstensen.com" }]
|
|
12
|
+
requires-python = ">=3.10"
|
|
13
|
+
dependencies = [
|
|
14
|
+
"numpy>=1.24",
|
|
15
|
+
]
|
|
16
|
+
keywords = [
|
|
17
|
+
"survival analysis",
|
|
18
|
+
"cox proportional hazards",
|
|
19
|
+
"out-of-core",
|
|
20
|
+
"streaming",
|
|
21
|
+
"epidemiology",
|
|
22
|
+
"statistics",
|
|
23
|
+
]
|
|
24
|
+
classifiers = [
|
|
25
|
+
"Development Status :: 3 - Alpha",
|
|
26
|
+
"Intended Audience :: Science/Research",
|
|
27
|
+
"Programming Language :: Python :: 3",
|
|
28
|
+
"Topic :: Scientific/Engineering :: Bio-Informatics",
|
|
29
|
+
"Topic :: Scientific/Engineering :: Medical Science Apps.",
|
|
30
|
+
]
|
|
31
|
+
|
|
32
|
+
[project.optional-dependencies]
|
|
33
|
+
parquet = ["pyarrow>=14"]
|
|
34
|
+
test = ["pytest>=7"]
|
|
35
|
+
|
|
36
|
+
[project.urls]
|
|
37
|
+
Homepage = "https://github.com/tommycarstensen/coxstream"
|
|
38
|
+
Repository = "https://github.com/tommycarstensen/coxstream"
|
|
39
|
+
Issues = "https://github.com/tommycarstensen/coxstream/issues"
|
|
40
|
+
|
|
41
|
+
[tool.setuptools.packages.find]
|
|
42
|
+
where = ["src"]
|
|
43
|
+
|
|
44
|
+
[tool.setuptools.package-data]
|
|
45
|
+
coxstream = ["*.pyx"]
|
coxstream-0.1.0/setup.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
1
|
+
"""Build the vendored Cython Efron streaming kernel (coxstream._kernel).
|
|
2
|
+
|
|
3
|
+
The project metadata lives in pyproject.toml; this file only declares the
|
|
4
|
+
compiled extension. Build in place for development with:
|
|
5
|
+
|
|
6
|
+
pip install -e .
|
|
7
|
+
"""
|
|
8
|
+
import platform
|
|
9
|
+
|
|
10
|
+
import numpy as np
|
|
11
|
+
from Cython.Build import cythonize
|
|
12
|
+
from setuptools import Extension, setup
|
|
13
|
+
|
|
14
|
+
# -O3 -ffast-math lets the compiler auto-vectorise the O(p^2) inner loops.
|
|
15
|
+
# -march=native is added only on Linux: macOS Pythons are universal2 and
|
|
16
|
+
# -march=native breaks the cross-arch build.
|
|
17
|
+
_flags = ["-O3", "-ffast-math"]
|
|
18
|
+
if platform.system() == "Linux":
|
|
19
|
+
_flags.append("-march=native")
|
|
20
|
+
|
|
21
|
+
setup(
|
|
22
|
+
ext_modules=cythonize(
|
|
23
|
+
[
|
|
24
|
+
Extension(
|
|
25
|
+
"coxstream._kernel",
|
|
26
|
+
sources=["src/coxstream/_kernel.pyx"],
|
|
27
|
+
include_dirs=[np.get_include()],
|
|
28
|
+
extra_compile_args=_flags,
|
|
29
|
+
)
|
|
30
|
+
],
|
|
31
|
+
compiler_directives={
|
|
32
|
+
"language_level": "3",
|
|
33
|
+
"boundscheck": False,
|
|
34
|
+
"wraparound": False,
|
|
35
|
+
"cdivision": True,
|
|
36
|
+
},
|
|
37
|
+
),
|
|
38
|
+
)
|
|
@@ -0,0 +1,18 @@
|
|
|
1
|
+
"""coxstream: exact out-of-core Cox proportional hazards via streaming NR.
|
|
2
|
+
|
|
3
|
+
Public API
|
|
4
|
+
----------
|
|
5
|
+
CoxStream
|
|
6
|
+
Exact Efron Cox proportional hazards estimator. Computes the score and
|
|
7
|
+
observed information in a single descending-time pass per Newton-Raphson
|
|
8
|
+
iteration, with O(p^2) working memory independent of the cohort size.
|
|
9
|
+
``fit`` takes in-memory arrays; ``fit_parquet`` streams out-of-core.
|
|
10
|
+
check_sorted
|
|
11
|
+
Dry run for the ``fit_parquet`` precondition: validate that a Parquet file
|
|
12
|
+
is descending-time sorted, from footer statistics alone (no full pass), so a
|
|
13
|
+
sort mistake fails fast instead of yielding a silently wrong fit.
|
|
14
|
+
"""
|
|
15
|
+
from coxstream.coxstream import CoxStream, check_sorted
|
|
16
|
+
|
|
17
|
+
__all__ = ["CoxStream", "check_sorted"]
|
|
18
|
+
__version__ = "0.1.0"
|