cotengrust 0.1.0__tar.gz → 0.1.1__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {cotengrust-0.1.0 → cotengrust-0.1.1}/.github/workflows/CI.yml +45 -3
- {cotengrust-0.1.0 → cotengrust-0.1.1}/Cargo.lock +1 -1
- {cotengrust-0.1.0 → cotengrust-0.1.1}/Cargo.toml +1 -2
- cotengrust-0.1.1/PKG-INFO +249 -0
- cotengrust-0.1.1/README.md +236 -0
- {cotengrust-0.1.0 → cotengrust-0.1.1}/pyproject.toml +11 -5
- {cotengrust-0.1.0 → cotengrust-0.1.1}/src/lib.rs +148 -47
- cotengrust-0.1.1/tests/test_cotengrust.py +205 -0
- cotengrust-0.1.0/PKG-INFO +0 -8
- {cotengrust-0.1.0 → cotengrust-0.1.1}/.gitignore +0 -0
- {cotengrust-0.1.0 → cotengrust-0.1.1}/LICENSE +0 -0
|
@@ -1,7 +1,7 @@
|
|
|
1
|
-
# This file is autogenerated by maturin
|
|
1
|
+
# This file is autogenerated by maturin v1.2.3
|
|
2
2
|
# To update, run
|
|
3
3
|
#
|
|
4
|
-
# maturin generate-ci github
|
|
4
|
+
# maturin generate-ci github --pytest
|
|
5
5
|
#
|
|
6
6
|
name: CI
|
|
7
7
|
|
|
@@ -41,6 +41,30 @@ jobs:
|
|
|
41
41
|
with:
|
|
42
42
|
name: wheels
|
|
43
43
|
path: dist
|
|
44
|
+
- name: pytest
|
|
45
|
+
if: ${{ startsWith(matrix.target, 'x86_64') }}
|
|
46
|
+
shell: bash
|
|
47
|
+
run: |
|
|
48
|
+
set -e
|
|
49
|
+
ls dist/*
|
|
50
|
+
pip install cotengrust --find-links dist --force-reinstall
|
|
51
|
+
pip install pytest numpy cotengra
|
|
52
|
+
pytest --verbose
|
|
53
|
+
- name: pytest
|
|
54
|
+
if: ${{ !startsWith(matrix.target, 'x86') && matrix.target != 'ppc64' }}
|
|
55
|
+
uses: uraimo/run-on-arch-action@v2.5.0
|
|
56
|
+
with:
|
|
57
|
+
arch: ${{ matrix.target }}
|
|
58
|
+
distro: ubuntu22.04
|
|
59
|
+
githubToken: ${{ github.token }}
|
|
60
|
+
install: |
|
|
61
|
+
apt-get update
|
|
62
|
+
apt-get install -y --no-install-recommends python3 python3-pip
|
|
63
|
+
pip3 install -U pip pytest # numpy cotengra
|
|
64
|
+
run: |
|
|
65
|
+
set -e
|
|
66
|
+
pip3 install cotengrust --find-links dist --force-reinstall
|
|
67
|
+
pytest --verbose
|
|
44
68
|
|
|
45
69
|
windows:
|
|
46
70
|
runs-on: windows-latest
|
|
@@ -64,6 +88,15 @@ jobs:
|
|
|
64
88
|
with:
|
|
65
89
|
name: wheels
|
|
66
90
|
path: dist
|
|
91
|
+
- name: pytest
|
|
92
|
+
if: ${{ !startsWith(matrix.target, 'aarch64') }}
|
|
93
|
+
shell: bash
|
|
94
|
+
run: |
|
|
95
|
+
set -e
|
|
96
|
+
ls dist/*
|
|
97
|
+
pip install cotengrust --find-links dist --force-reinstall
|
|
98
|
+
pip install pytest numpy cotengra
|
|
99
|
+
pytest --verbose
|
|
67
100
|
|
|
68
101
|
macos:
|
|
69
102
|
runs-on: macos-latest
|
|
@@ -86,6 +119,15 @@ jobs:
|
|
|
86
119
|
with:
|
|
87
120
|
name: wheels
|
|
88
121
|
path: dist
|
|
122
|
+
- name: pytest
|
|
123
|
+
if: ${{ !startsWith(matrix.target, 'aarch64') }}
|
|
124
|
+
shell: bash
|
|
125
|
+
run: |
|
|
126
|
+
set -e
|
|
127
|
+
ls dist/*
|
|
128
|
+
pip install cotengrust --find-links dist --force-reinstall
|
|
129
|
+
pip install pytest numpy cotengra
|
|
130
|
+
pytest --verbose
|
|
89
131
|
|
|
90
132
|
sdist:
|
|
91
133
|
runs-on: ubuntu-latest
|
|
@@ -117,4 +159,4 @@ jobs:
|
|
|
117
159
|
MATURIN_PYPI_TOKEN: ${{ secrets.PYPI_API_TOKEN }}
|
|
118
160
|
with:
|
|
119
161
|
command: upload
|
|
120
|
-
args: --skip-existing *
|
|
162
|
+
args: --non-interactive --skip-existing *
|
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
[package]
|
|
2
2
|
name = "cotengrust"
|
|
3
|
-
version = "0.1.
|
|
3
|
+
version = "0.1.1"
|
|
4
4
|
edition = "2021"
|
|
5
5
|
|
|
6
6
|
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
|
|
@@ -19,4 +19,3 @@ rustc-hash = "1.1"
|
|
|
19
19
|
codegen-units = 1
|
|
20
20
|
lto = true
|
|
21
21
|
opt-level = 3
|
|
22
|
-
panic = "abort"
|
|
@@ -0,0 +1,249 @@
|
|
|
1
|
+
Metadata-Version: 2.1
|
|
2
|
+
Name: cotengrust
|
|
3
|
+
Version: 0.1.1
|
|
4
|
+
Classifier: Programming Language :: Rust
|
|
5
|
+
Classifier: Programming Language :: Python :: Implementation :: CPython
|
|
6
|
+
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
|
7
|
+
License-File: LICENSE
|
|
8
|
+
Summary: Fast contraction ordering primitives for tensor networks.
|
|
9
|
+
Author-email: Johnnie Gray <johnniemcgray@gmail.com>
|
|
10
|
+
Requires-Python: >=3.8
|
|
11
|
+
Description-Content-Type: text/markdown; charset=UTF-8; variant=GFM
|
|
12
|
+
|
|
13
|
+
# cotengrust
|
|
14
|
+
|
|
15
|
+
`cotengrust` provides fast rust implementations of contraction ordering
|
|
16
|
+
primitives for tensor networks or einsum expressions. The two main functions
|
|
17
|
+
are:
|
|
18
|
+
|
|
19
|
+
- `optimize_optimal(inputs, output, size_dict, **kwargs)`
|
|
20
|
+
- `optimize_greedy(inputs, output, size_dict, **kwargs)`
|
|
21
|
+
|
|
22
|
+
The optimal algorithm is an optimized version of the `opt_einsum` 'dp'
|
|
23
|
+
path - itself an implementation of https://arxiv.org/abs/1304.6112.
|
|
24
|
+
|
|
25
|
+
|
|
26
|
+
## Installation
|
|
27
|
+
|
|
28
|
+
`cotengrust` is available for most platforms from
|
|
29
|
+
[PyPI](https://pypi.org/project/cotengrust/):
|
|
30
|
+
|
|
31
|
+
```bash
|
|
32
|
+
pip install cotengrust
|
|
33
|
+
```
|
|
34
|
+
|
|
35
|
+
or if you want to develop locally (which requires [pyo3](https://github.com/PyO3/pyo3)
|
|
36
|
+
and [maturin](https://github.com/PyO3/maturin)):
|
|
37
|
+
|
|
38
|
+
```bash
|
|
39
|
+
git clone https://github.com/jcmgray/cotengrust.git
|
|
40
|
+
cd cotengrust
|
|
41
|
+
maturin develop --release
|
|
42
|
+
```
|
|
43
|
+
(the release flag is very important for assessing performance!).
|
|
44
|
+
|
|
45
|
+
|
|
46
|
+
## Usage
|
|
47
|
+
|
|
48
|
+
If `cotengrust` is installed, then by default `cotengra` will use it for its
|
|
49
|
+
greedy and optimal subroutines, notably subtree reconfiguration. You can also
|
|
50
|
+
call the routines directly:
|
|
51
|
+
|
|
52
|
+
```python
|
|
53
|
+
import cotengra as ctg
|
|
54
|
+
import cotengrust as ctgr
|
|
55
|
+
|
|
56
|
+
# specify an 8x8 square lattice contraction
|
|
57
|
+
inputs, output, shapes, size_dict = ctg.utils.lattice_equation([8, 8])
|
|
58
|
+
|
|
59
|
+
# find the optimal 'combo' contraction path
|
|
60
|
+
%%time
|
|
61
|
+
path = ctgr.optimize_optimal(inputs, output, size_dict, minimize='combo')
|
|
62
|
+
# CPU times: user 13.7 s, sys: 83.4 ms, total: 13.7 s
|
|
63
|
+
# Wall time: 13.7 s
|
|
64
|
+
|
|
65
|
+
# construct a contraction tree for further introspection
|
|
66
|
+
tree = ctg.ContractionTree.from_path(
|
|
67
|
+
inputs, output, size_dict, path=path
|
|
68
|
+
)
|
|
69
|
+
tree.plot_rubberband()
|
|
70
|
+
```
|
|
71
|
+
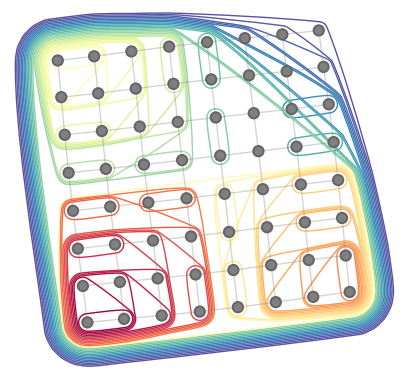
|
|
72
|
+
|
|
73
|
+
|
|
74
|
+
## API
|
|
75
|
+
|
|
76
|
+
The optimize functions follow the api of the python implementations in `cotengra.pathfinders.path_basic.py`.
|
|
77
|
+
|
|
78
|
+
```python
|
|
79
|
+
def optimize_optimal(
|
|
80
|
+
inputs,
|
|
81
|
+
output,
|
|
82
|
+
size_dict,
|
|
83
|
+
minimize='flops',
|
|
84
|
+
cost_cap=2,
|
|
85
|
+
search_outer=False,
|
|
86
|
+
simplify=True,
|
|
87
|
+
use_ssa=False,
|
|
88
|
+
):
|
|
89
|
+
"""Find an optimal contraction ordering.
|
|
90
|
+
|
|
91
|
+
Parameters
|
|
92
|
+
----------
|
|
93
|
+
inputs : Sequence[Sequence[str]]
|
|
94
|
+
The indices of each input tensor.
|
|
95
|
+
output : Sequence[str]
|
|
96
|
+
The indices of the output tensor.
|
|
97
|
+
size_dict : dict[str, int]
|
|
98
|
+
The size of each index.
|
|
99
|
+
minimize : str, optional
|
|
100
|
+
The cost function to minimize. The options are:
|
|
101
|
+
|
|
102
|
+
- "flops": minimize with respect to total operation count only
|
|
103
|
+
(also known as contraction cost)
|
|
104
|
+
- "size": minimize with respect to maximum intermediate size only
|
|
105
|
+
(also known as contraction width)
|
|
106
|
+
- 'write' : minimize the sum of all tensor sizes, i.e. memory written
|
|
107
|
+
- 'combo' or 'combo={factor}` : minimize the sum of
|
|
108
|
+
FLOPS + factor * WRITE, with a default factor of 64.
|
|
109
|
+
- 'limit' or 'limit={factor}` : minimize the sum of
|
|
110
|
+
MAX(FLOPS, alpha * WRITE) for each individual contraction, with a
|
|
111
|
+
default factor of 64.
|
|
112
|
+
|
|
113
|
+
'combo' is generally a good default in term of practical hardware
|
|
114
|
+
performance, where both memory bandwidth and compute are limited.
|
|
115
|
+
cost_cap : float, optional
|
|
116
|
+
The maximum cost of a contraction to initially consider. This acts like
|
|
117
|
+
a sieve and is doubled at each iteration until the optimal path can
|
|
118
|
+
be found, but supplying an accurate guess can speed up the algorithm.
|
|
119
|
+
search_outer : bool, optional
|
|
120
|
+
If True, consider outer product contractions. This is much slower but
|
|
121
|
+
theoretically might be required to find the true optimal 'flops'
|
|
122
|
+
ordering. In practical settings (i.e. with minimize='combo'), outer
|
|
123
|
+
products should not be required.
|
|
124
|
+
simplify : bool, optional
|
|
125
|
+
Whether to perform simplifications before optimizing. These are:
|
|
126
|
+
|
|
127
|
+
- ignore any indices that appear in all terms
|
|
128
|
+
- combine any repeated indices within a single term
|
|
129
|
+
- reduce any non-output indices that only appear on a single term
|
|
130
|
+
- combine any scalar terms
|
|
131
|
+
- combine any tensors with matching indices (hadamard products)
|
|
132
|
+
|
|
133
|
+
Such simpifications may be required in the general case for the proper
|
|
134
|
+
functioning of the core optimization, but may be skipped if the input
|
|
135
|
+
indices are already in a simplified form.
|
|
136
|
+
use_ssa : bool, optional
|
|
137
|
+
Whether to return the contraction path in 'single static assignment'
|
|
138
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
139
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
140
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
141
|
+
|
|
142
|
+
Returns
|
|
143
|
+
-------
|
|
144
|
+
path : list[list[int]]
|
|
145
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
146
|
+
may also have single term contractions if `simplify=True`.
|
|
147
|
+
"""
|
|
148
|
+
...
|
|
149
|
+
|
|
150
|
+
|
|
151
|
+
def optimize_greedy(
|
|
152
|
+
inputs,
|
|
153
|
+
output,
|
|
154
|
+
size_dict,
|
|
155
|
+
costmod=1.0,
|
|
156
|
+
temperature=0.0,
|
|
157
|
+
simplify=True,
|
|
158
|
+
use_ssa=False,
|
|
159
|
+
):
|
|
160
|
+
"""Find a contraction path using a (randomizable) greedy algorithm.
|
|
161
|
+
|
|
162
|
+
Parameters
|
|
163
|
+
----------
|
|
164
|
+
inputs : Sequence[Sequence[str]]
|
|
165
|
+
The indices of each input tensor.
|
|
166
|
+
output : Sequence[str]
|
|
167
|
+
The indices of the output tensor.
|
|
168
|
+
size_dict : dict[str, int]
|
|
169
|
+
A dictionary mapping indices to their dimension.
|
|
170
|
+
costmod : float, optional
|
|
171
|
+
When assessing local greedy scores how much to weight the size of the
|
|
172
|
+
tensors removed compared to the size of the tensor added::
|
|
173
|
+
|
|
174
|
+
score = size_ab - costmod * (size_a + size_b)
|
|
175
|
+
|
|
176
|
+
This can be a useful hyper-parameter to tune.
|
|
177
|
+
temperature : float, optional
|
|
178
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
179
|
+
score. This is implemented as::
|
|
180
|
+
|
|
181
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
182
|
+
|
|
183
|
+
which implements boltzmann sampling.
|
|
184
|
+
simplify : bool, optional
|
|
185
|
+
Whether to perform simplifications before optimizing. These are:
|
|
186
|
+
|
|
187
|
+
- ignore any indices that appear in all terms
|
|
188
|
+
- combine any repeated indices within a single term
|
|
189
|
+
- reduce any non-output indices that only appear on a single term
|
|
190
|
+
- combine any scalar terms
|
|
191
|
+
- combine any tensors with matching indices (hadamard products)
|
|
192
|
+
|
|
193
|
+
Such simpifications may be required in the general case for the proper
|
|
194
|
+
functioning of the core optimization, but may be skipped if the input
|
|
195
|
+
indices are already in a simplified form.
|
|
196
|
+
use_ssa : bool, optional
|
|
197
|
+
Whether to return the contraction path in 'single static assignment'
|
|
198
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
199
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
200
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
201
|
+
|
|
202
|
+
Returns
|
|
203
|
+
-------
|
|
204
|
+
path : list[list[int]]
|
|
205
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
206
|
+
may also have single term contractions if `simplify=True`.
|
|
207
|
+
"""
|
|
208
|
+
|
|
209
|
+
def optimize_simplify(
|
|
210
|
+
inputs,
|
|
211
|
+
output,
|
|
212
|
+
size_dict,
|
|
213
|
+
use_ssa=False,
|
|
214
|
+
):
|
|
215
|
+
"""Find the (partial) contracton path for simplifiactions only.
|
|
216
|
+
|
|
217
|
+
Parameters
|
|
218
|
+
----------
|
|
219
|
+
inputs : Sequence[Sequence[str]]
|
|
220
|
+
The indices of each input tensor.
|
|
221
|
+
output : Sequence[str]
|
|
222
|
+
The indices of the output tensor.
|
|
223
|
+
size_dict : dict[str, int]
|
|
224
|
+
A dictionary mapping indices to their dimension.
|
|
225
|
+
use_ssa : bool, optional
|
|
226
|
+
Whether to return the contraction path in 'single static assignment'
|
|
227
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
228
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
229
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
230
|
+
|
|
231
|
+
Returns
|
|
232
|
+
-------
|
|
233
|
+
path : list[list[int]]
|
|
234
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
235
|
+
may also have single term contractions.
|
|
236
|
+
|
|
237
|
+
"""
|
|
238
|
+
...
|
|
239
|
+
|
|
240
|
+
def ssa_to_linear(ssa_path, n=None):
|
|
241
|
+
"""Convert a SSA path to linear format."""
|
|
242
|
+
...
|
|
243
|
+
|
|
244
|
+
def find_subgraphs(inputs, output, size_dict,):
|
|
245
|
+
"""Find all disconnected subgraphs of a specified contraction."""
|
|
246
|
+
...
|
|
247
|
+
```
|
|
248
|
+
|
|
249
|
+
|
|
@@ -0,0 +1,236 @@
|
|
|
1
|
+
# cotengrust
|
|
2
|
+
|
|
3
|
+
`cotengrust` provides fast rust implementations of contraction ordering
|
|
4
|
+
primitives for tensor networks or einsum expressions. The two main functions
|
|
5
|
+
are:
|
|
6
|
+
|
|
7
|
+
- `optimize_optimal(inputs, output, size_dict, **kwargs)`
|
|
8
|
+
- `optimize_greedy(inputs, output, size_dict, **kwargs)`
|
|
9
|
+
|
|
10
|
+
The optimal algorithm is an optimized version of the `opt_einsum` 'dp'
|
|
11
|
+
path - itself an implementation of https://arxiv.org/abs/1304.6112.
|
|
12
|
+
|
|
13
|
+
|
|
14
|
+
## Installation
|
|
15
|
+
|
|
16
|
+
`cotengrust` is available for most platforms from
|
|
17
|
+
[PyPI](https://pypi.org/project/cotengrust/):
|
|
18
|
+
|
|
19
|
+
```bash
|
|
20
|
+
pip install cotengrust
|
|
21
|
+
```
|
|
22
|
+
|
|
23
|
+
or if you want to develop locally (which requires [pyo3](https://github.com/PyO3/pyo3)
|
|
24
|
+
and [maturin](https://github.com/PyO3/maturin)):
|
|
25
|
+
|
|
26
|
+
```bash
|
|
27
|
+
git clone https://github.com/jcmgray/cotengrust.git
|
|
28
|
+
cd cotengrust
|
|
29
|
+
maturin develop --release
|
|
30
|
+
```
|
|
31
|
+
(the release flag is very important for assessing performance!).
|
|
32
|
+
|
|
33
|
+
|
|
34
|
+
## Usage
|
|
35
|
+
|
|
36
|
+
If `cotengrust` is installed, then by default `cotengra` will use it for its
|
|
37
|
+
greedy and optimal subroutines, notably subtree reconfiguration. You can also
|
|
38
|
+
call the routines directly:
|
|
39
|
+
|
|
40
|
+
```python
|
|
41
|
+
import cotengra as ctg
|
|
42
|
+
import cotengrust as ctgr
|
|
43
|
+
|
|
44
|
+
# specify an 8x8 square lattice contraction
|
|
45
|
+
inputs, output, shapes, size_dict = ctg.utils.lattice_equation([8, 8])
|
|
46
|
+
|
|
47
|
+
# find the optimal 'combo' contraction path
|
|
48
|
+
%%time
|
|
49
|
+
path = ctgr.optimize_optimal(inputs, output, size_dict, minimize='combo')
|
|
50
|
+
# CPU times: user 13.7 s, sys: 83.4 ms, total: 13.7 s
|
|
51
|
+
# Wall time: 13.7 s
|
|
52
|
+
|
|
53
|
+
# construct a contraction tree for further introspection
|
|
54
|
+
tree = ctg.ContractionTree.from_path(
|
|
55
|
+
inputs, output, size_dict, path=path
|
|
56
|
+
)
|
|
57
|
+
tree.plot_rubberband()
|
|
58
|
+
```
|
|
59
|
+

|
|
60
|
+
|
|
61
|
+
|
|
62
|
+
## API
|
|
63
|
+
|
|
64
|
+
The optimize functions follow the api of the python implementations in `cotengra.pathfinders.path_basic.py`.
|
|
65
|
+
|
|
66
|
+
```python
|
|
67
|
+
def optimize_optimal(
|
|
68
|
+
inputs,
|
|
69
|
+
output,
|
|
70
|
+
size_dict,
|
|
71
|
+
minimize='flops',
|
|
72
|
+
cost_cap=2,
|
|
73
|
+
search_outer=False,
|
|
74
|
+
simplify=True,
|
|
75
|
+
use_ssa=False,
|
|
76
|
+
):
|
|
77
|
+
"""Find an optimal contraction ordering.
|
|
78
|
+
|
|
79
|
+
Parameters
|
|
80
|
+
----------
|
|
81
|
+
inputs : Sequence[Sequence[str]]
|
|
82
|
+
The indices of each input tensor.
|
|
83
|
+
output : Sequence[str]
|
|
84
|
+
The indices of the output tensor.
|
|
85
|
+
size_dict : dict[str, int]
|
|
86
|
+
The size of each index.
|
|
87
|
+
minimize : str, optional
|
|
88
|
+
The cost function to minimize. The options are:
|
|
89
|
+
|
|
90
|
+
- "flops": minimize with respect to total operation count only
|
|
91
|
+
(also known as contraction cost)
|
|
92
|
+
- "size": minimize with respect to maximum intermediate size only
|
|
93
|
+
(also known as contraction width)
|
|
94
|
+
- 'write' : minimize the sum of all tensor sizes, i.e. memory written
|
|
95
|
+
- 'combo' or 'combo={factor}` : minimize the sum of
|
|
96
|
+
FLOPS + factor * WRITE, with a default factor of 64.
|
|
97
|
+
- 'limit' or 'limit={factor}` : minimize the sum of
|
|
98
|
+
MAX(FLOPS, alpha * WRITE) for each individual contraction, with a
|
|
99
|
+
default factor of 64.
|
|
100
|
+
|
|
101
|
+
'combo' is generally a good default in term of practical hardware
|
|
102
|
+
performance, where both memory bandwidth and compute are limited.
|
|
103
|
+
cost_cap : float, optional
|
|
104
|
+
The maximum cost of a contraction to initially consider. This acts like
|
|
105
|
+
a sieve and is doubled at each iteration until the optimal path can
|
|
106
|
+
be found, but supplying an accurate guess can speed up the algorithm.
|
|
107
|
+
search_outer : bool, optional
|
|
108
|
+
If True, consider outer product contractions. This is much slower but
|
|
109
|
+
theoretically might be required to find the true optimal 'flops'
|
|
110
|
+
ordering. In practical settings (i.e. with minimize='combo'), outer
|
|
111
|
+
products should not be required.
|
|
112
|
+
simplify : bool, optional
|
|
113
|
+
Whether to perform simplifications before optimizing. These are:
|
|
114
|
+
|
|
115
|
+
- ignore any indices that appear in all terms
|
|
116
|
+
- combine any repeated indices within a single term
|
|
117
|
+
- reduce any non-output indices that only appear on a single term
|
|
118
|
+
- combine any scalar terms
|
|
119
|
+
- combine any tensors with matching indices (hadamard products)
|
|
120
|
+
|
|
121
|
+
Such simpifications may be required in the general case for the proper
|
|
122
|
+
functioning of the core optimization, but may be skipped if the input
|
|
123
|
+
indices are already in a simplified form.
|
|
124
|
+
use_ssa : bool, optional
|
|
125
|
+
Whether to return the contraction path in 'single static assignment'
|
|
126
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
127
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
128
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
129
|
+
|
|
130
|
+
Returns
|
|
131
|
+
-------
|
|
132
|
+
path : list[list[int]]
|
|
133
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
134
|
+
may also have single term contractions if `simplify=True`.
|
|
135
|
+
"""
|
|
136
|
+
...
|
|
137
|
+
|
|
138
|
+
|
|
139
|
+
def optimize_greedy(
|
|
140
|
+
inputs,
|
|
141
|
+
output,
|
|
142
|
+
size_dict,
|
|
143
|
+
costmod=1.0,
|
|
144
|
+
temperature=0.0,
|
|
145
|
+
simplify=True,
|
|
146
|
+
use_ssa=False,
|
|
147
|
+
):
|
|
148
|
+
"""Find a contraction path using a (randomizable) greedy algorithm.
|
|
149
|
+
|
|
150
|
+
Parameters
|
|
151
|
+
----------
|
|
152
|
+
inputs : Sequence[Sequence[str]]
|
|
153
|
+
The indices of each input tensor.
|
|
154
|
+
output : Sequence[str]
|
|
155
|
+
The indices of the output tensor.
|
|
156
|
+
size_dict : dict[str, int]
|
|
157
|
+
A dictionary mapping indices to their dimension.
|
|
158
|
+
costmod : float, optional
|
|
159
|
+
When assessing local greedy scores how much to weight the size of the
|
|
160
|
+
tensors removed compared to the size of the tensor added::
|
|
161
|
+
|
|
162
|
+
score = size_ab - costmod * (size_a + size_b)
|
|
163
|
+
|
|
164
|
+
This can be a useful hyper-parameter to tune.
|
|
165
|
+
temperature : float, optional
|
|
166
|
+
When asessing local greedy scores, how much to randomly perturb the
|
|
167
|
+
score. This is implemented as::
|
|
168
|
+
|
|
169
|
+
score -> sign(score) * log(|score|) - temperature * gumbel()
|
|
170
|
+
|
|
171
|
+
which implements boltzmann sampling.
|
|
172
|
+
simplify : bool, optional
|
|
173
|
+
Whether to perform simplifications before optimizing. These are:
|
|
174
|
+
|
|
175
|
+
- ignore any indices that appear in all terms
|
|
176
|
+
- combine any repeated indices within a single term
|
|
177
|
+
- reduce any non-output indices that only appear on a single term
|
|
178
|
+
- combine any scalar terms
|
|
179
|
+
- combine any tensors with matching indices (hadamard products)
|
|
180
|
+
|
|
181
|
+
Such simpifications may be required in the general case for the proper
|
|
182
|
+
functioning of the core optimization, but may be skipped if the input
|
|
183
|
+
indices are already in a simplified form.
|
|
184
|
+
use_ssa : bool, optional
|
|
185
|
+
Whether to return the contraction path in 'single static assignment'
|
|
186
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
187
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
188
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
189
|
+
|
|
190
|
+
Returns
|
|
191
|
+
-------
|
|
192
|
+
path : list[list[int]]
|
|
193
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
194
|
+
may also have single term contractions if `simplify=True`.
|
|
195
|
+
"""
|
|
196
|
+
|
|
197
|
+
def optimize_simplify(
|
|
198
|
+
inputs,
|
|
199
|
+
output,
|
|
200
|
+
size_dict,
|
|
201
|
+
use_ssa=False,
|
|
202
|
+
):
|
|
203
|
+
"""Find the (partial) contracton path for simplifiactions only.
|
|
204
|
+
|
|
205
|
+
Parameters
|
|
206
|
+
----------
|
|
207
|
+
inputs : Sequence[Sequence[str]]
|
|
208
|
+
The indices of each input tensor.
|
|
209
|
+
output : Sequence[str]
|
|
210
|
+
The indices of the output tensor.
|
|
211
|
+
size_dict : dict[str, int]
|
|
212
|
+
A dictionary mapping indices to their dimension.
|
|
213
|
+
use_ssa : bool, optional
|
|
214
|
+
Whether to return the contraction path in 'single static assignment'
|
|
215
|
+
(SSA) format (i.e. as if each intermediate is appended to the list of
|
|
216
|
+
inputs, without removals). This can be quicker and easier to work with
|
|
217
|
+
than the 'linear recycled' format that `numpy` and `opt_einsum` use.
|
|
218
|
+
|
|
219
|
+
Returns
|
|
220
|
+
-------
|
|
221
|
+
path : list[list[int]]
|
|
222
|
+
The contraction path, given as a sequence of pairs of node indices. It
|
|
223
|
+
may also have single term contractions.
|
|
224
|
+
|
|
225
|
+
"""
|
|
226
|
+
...
|
|
227
|
+
|
|
228
|
+
def ssa_to_linear(ssa_path, n=None):
|
|
229
|
+
"""Convert a SSA path to linear format."""
|
|
230
|
+
...
|
|
231
|
+
|
|
232
|
+
def find_subgraphs(inputs, output, size_dict,):
|
|
233
|
+
"""Find all disconnected subgraphs of a specified contraction."""
|
|
234
|
+
...
|
|
235
|
+
```
|
|
236
|
+
|
|
@@ -1,16 +1,22 @@
|
|
|
1
|
-
[build-system]
|
|
2
|
-
requires = ["maturin>=0.15,<0.16"]
|
|
3
|
-
build-backend = "maturin"
|
|
4
|
-
|
|
5
1
|
[project]
|
|
6
2
|
name = "cotengrust"
|
|
7
|
-
|
|
3
|
+
version = "0.1.1"
|
|
4
|
+
description = "Fast contraction ordering primitives for tensor networks."
|
|
5
|
+
readme = "README.md"
|
|
6
|
+
requires-python = ">=3.8"
|
|
8
7
|
classifiers = [
|
|
9
8
|
"Programming Language :: Rust",
|
|
10
9
|
"Programming Language :: Python :: Implementation :: CPython",
|
|
11
10
|
"Programming Language :: Python :: Implementation :: PyPy",
|
|
12
11
|
]
|
|
12
|
+
license = { file = "LICENSE" }
|
|
13
|
+
authors = [
|
|
14
|
+
{name = "Johnnie Gray", email = "johnniemcgray@gmail.com"}
|
|
15
|
+
]
|
|
13
16
|
|
|
17
|
+
[build-system]
|
|
18
|
+
requires = ["maturin>=0.15,<0.16"]
|
|
19
|
+
build-backend = "maturin"
|
|
14
20
|
|
|
15
21
|
[tool.maturin]
|
|
16
22
|
features = ["pyo3/extension-module"]
|
|
@@ -25,7 +25,7 @@ type SubContraction = (Legs, Score, BitPath);
|
|
|
25
25
|
/// helper struct to build contractions from bottom up
|
|
26
26
|
struct ContractionProcessor {
|
|
27
27
|
nodes: Dict<Node, Legs>,
|
|
28
|
-
edges: Dict<Ix,
|
|
28
|
+
edges: Dict<Ix, BTreeSet<Node>>,
|
|
29
29
|
appearances: Vec<Count>,
|
|
30
30
|
sizes: Vec<Score>,
|
|
31
31
|
ssa: Node,
|
|
@@ -133,7 +133,7 @@ impl ContractionProcessor {
|
|
|
133
133
|
size_dict: Dict<char, f32>,
|
|
134
134
|
) -> ContractionProcessor {
|
|
135
135
|
let mut nodes: Dict<Node, Legs> = Dict::default();
|
|
136
|
-
let mut edges: Dict<Ix,
|
|
136
|
+
let mut edges: Dict<Ix, BTreeSet<Node>> = Dict::default();
|
|
137
137
|
let mut indmap: Dict<char, Ix> = Dict::default();
|
|
138
138
|
let mut sizes: Vec<Score> = Vec::with_capacity(size_dict.len());
|
|
139
139
|
let mut appearances: Vec<Count> = Vec::with_capacity(size_dict.len());
|
|
@@ -147,7 +147,7 @@ impl ContractionProcessor {
|
|
|
147
147
|
None => {
|
|
148
148
|
// index not parsed yet
|
|
149
149
|
indmap.insert(ind, c);
|
|
150
|
-
edges.insert(c,
|
|
150
|
+
edges.insert(c, std::iter::once(i as Node).collect());
|
|
151
151
|
appearances.push(1);
|
|
152
152
|
sizes.push(f32::log(size_dict[&ind] as f32, 2.0));
|
|
153
153
|
legs.push((c, 1));
|
|
@@ -156,7 +156,7 @@ impl ContractionProcessor {
|
|
|
156
156
|
Some(&ix) => {
|
|
157
157
|
// index already present
|
|
158
158
|
appearances[ix as usize] += 1;
|
|
159
|
-
edges.get_mut(&ix).unwrap().
|
|
159
|
+
edges.get_mut(&ix).unwrap().insert(i as Node);
|
|
160
160
|
legs.push((ix, 1));
|
|
161
161
|
}
|
|
162
162
|
};
|
|
@@ -204,11 +204,15 @@ impl ContractionProcessor {
|
|
|
204
204
|
fn pop_node(&mut self, i: Node) -> Legs {
|
|
205
205
|
let legs = self.nodes.remove(&i).unwrap();
|
|
206
206
|
for (ix, _) in legs.iter() {
|
|
207
|
-
let
|
|
208
|
-
|
|
207
|
+
let enodes = match self.edges.get_mut(&ix) {
|
|
208
|
+
Some(enodes) => enodes,
|
|
209
|
+
// if repeated index, might have already been removed
|
|
210
|
+
None => continue,
|
|
211
|
+
};
|
|
212
|
+
enodes.remove(&i);
|
|
213
|
+
if enodes.len() == 0 {
|
|
214
|
+
// last node with this index -> remove from map
|
|
209
215
|
self.edges.remove(&ix);
|
|
210
|
-
} else {
|
|
211
|
-
nodes.retain(|&j| j != i);
|
|
212
216
|
}
|
|
213
217
|
}
|
|
214
218
|
legs
|
|
@@ -221,8 +225,8 @@ impl ContractionProcessor {
|
|
|
221
225
|
for (ix, _) in &legs {
|
|
222
226
|
self.edges
|
|
223
227
|
.entry(*ix)
|
|
224
|
-
.and_modify(|nodes| nodes.
|
|
225
|
-
.or_insert(
|
|
228
|
+
.and_modify(|nodes| {nodes.insert(i);})
|
|
229
|
+
.or_insert(std::iter::once(i as Node).collect());
|
|
226
230
|
}
|
|
227
231
|
self.nodes.insert(i, legs);
|
|
228
232
|
i
|
|
@@ -267,28 +271,27 @@ impl ContractionProcessor {
|
|
|
267
271
|
/// combine and remove all scalars
|
|
268
272
|
fn simplify_scalars(&mut self) {
|
|
269
273
|
let mut scalars = Vec::new();
|
|
274
|
+
let mut j: Option<Node> = None;
|
|
275
|
+
let mut jndim: usize = 0;
|
|
270
276
|
for (i, legs) in self.nodes.iter() {
|
|
271
|
-
|
|
277
|
+
let ndim = legs.len();
|
|
278
|
+
if ndim == 0 {
|
|
272
279
|
scalars.push(*i);
|
|
280
|
+
} else {
|
|
281
|
+
// also search for smallest other term to multiply into
|
|
282
|
+
if j.is_none() || ndim < jndim {
|
|
283
|
+
j = Some(*i);
|
|
284
|
+
jndim = ndim;
|
|
285
|
+
}
|
|
273
286
|
}
|
|
274
287
|
}
|
|
275
288
|
if scalars.len() > 0 {
|
|
276
|
-
for
|
|
277
|
-
|
|
289
|
+
for p in 0..scalars.len() - 1 {
|
|
290
|
+
let i = scalars[p];
|
|
291
|
+
let j = scalars[p + 1];
|
|
292
|
+
let k = self.contract_nodes(i, j);
|
|
293
|
+
scalars[p + 1] = k;
|
|
278
294
|
}
|
|
279
|
-
let (res, con) = match self.nodes.iter().min_by_key(|&(_, legs)| legs.len()) {
|
|
280
|
-
Some((&j, _)) => {
|
|
281
|
-
let res = self.pop_node(j);
|
|
282
|
-
let con: Vec<Node> = scalars.into_iter().chain(vec![j].into_iter()).collect();
|
|
283
|
-
(res, con)
|
|
284
|
-
}
|
|
285
|
-
None => {
|
|
286
|
-
let res = Vec::new();
|
|
287
|
-
(res, scalars)
|
|
288
|
-
}
|
|
289
|
-
};
|
|
290
|
-
self.add_node(res);
|
|
291
|
-
self.ssa_path.push(con);
|
|
292
295
|
}
|
|
293
296
|
}
|
|
294
297
|
|
|
@@ -393,6 +396,8 @@ impl ContractionProcessor {
|
|
|
393
396
|
|
|
394
397
|
// get the initial candidate contractions
|
|
395
398
|
for ix_nodes in self.edges.values() {
|
|
399
|
+
// convert to vector for combinational indexing
|
|
400
|
+
let ix_nodes: Vec<Node> = ix_nodes.iter().cloned().collect();
|
|
396
401
|
// for all combinations of nodes with a connected edge
|
|
397
402
|
for ip in 0..ix_nodes.len() {
|
|
398
403
|
let i = ix_nodes[ip];
|
|
@@ -579,26 +584,70 @@ fn compute_con_cost_combo(
|
|
|
579
584
|
(new_legs, new_score)
|
|
580
585
|
}
|
|
581
586
|
|
|
587
|
+
fn compute_con_cost_limit(
|
|
588
|
+
temp_legs: Legs,
|
|
589
|
+
appearances: &Vec<Count>,
|
|
590
|
+
sizes: &Vec<Score>,
|
|
591
|
+
iscore: Score,
|
|
592
|
+
jscore: Score,
|
|
593
|
+
factor: Score,
|
|
594
|
+
) -> (Legs, Score) {
|
|
595
|
+
// remove indices that have reached final appearance
|
|
596
|
+
// and compute cost and size of local contraction
|
|
597
|
+
let mut new_legs: Legs = Legs::with_capacity(temp_legs.len());
|
|
598
|
+
let mut size: Score = 0.0;
|
|
599
|
+
let mut cost: Score = 0.0;
|
|
600
|
+
for (ix, ix_count) in temp_legs.into_iter() {
|
|
601
|
+
// all involved indices contribute to the cost
|
|
602
|
+
let d = sizes[ix as usize];
|
|
603
|
+
cost += d;
|
|
604
|
+
if ix_count != appearances[ix as usize] {
|
|
605
|
+
// not last appearance -> kept index contributes to new size
|
|
606
|
+
new_legs.push((ix, ix_count));
|
|
607
|
+
size += d;
|
|
608
|
+
}
|
|
609
|
+
}
|
|
610
|
+
// whichever is more expensive, the cost or the scaled write
|
|
611
|
+
let new_local_score = cost.max(factor + size);
|
|
612
|
+
|
|
613
|
+
// the total score including history
|
|
614
|
+
let new_score = logadd(logadd(iscore, jscore), new_local_score);
|
|
615
|
+
|
|
616
|
+
(new_legs, new_score)
|
|
617
|
+
}
|
|
618
|
+
|
|
582
619
|
impl ContractionProcessor {
|
|
583
620
|
fn optimize_optimal_connected(
|
|
584
621
|
&mut self,
|
|
585
622
|
subgraph: Vec<Node>,
|
|
586
623
|
minimize: Option<String>,
|
|
587
|
-
factor: Option<Score>,
|
|
588
624
|
cost_cap: Option<Score>,
|
|
625
|
+
search_outer: Option<bool>,
|
|
589
626
|
) {
|
|
627
|
+
// parse the minimize argument
|
|
590
628
|
let minimize = minimize.unwrap_or("flops".to_string());
|
|
591
|
-
let
|
|
592
|
-
let
|
|
629
|
+
let mut minimize_split = minimize.split('-');
|
|
630
|
+
let minimize_type = minimize_split.next().unwrap();
|
|
631
|
+
let factor = minimize_split
|
|
632
|
+
.next()
|
|
633
|
+
.map_or(64.0, |s| s.parse::<f32>().unwrap())
|
|
634
|
+
.ln();
|
|
635
|
+
if minimize_split.next().is_some() {
|
|
636
|
+
// multiple hyphens -> raise error
|
|
637
|
+
panic!("invalid minimize: {:?}", minimize);
|
|
638
|
+
}
|
|
639
|
+
let compute_cost = match minimize_type {
|
|
593
640
|
"flops" => compute_con_cost_flops,
|
|
594
641
|
"size" => compute_con_cost_size,
|
|
595
642
|
"write" => compute_con_cost_write,
|
|
596
643
|
"combo" => compute_con_cost_combo,
|
|
644
|
+
"limit" => compute_con_cost_limit,
|
|
597
645
|
_ => panic!(
|
|
598
|
-
"minimize must be one of 'flops', 'size', 'write', or '
|
|
646
|
+
"minimize must be one of 'flops', 'size', 'write', 'combo', or 'limit', got {}",
|
|
599
647
|
minimize
|
|
600
648
|
),
|
|
601
649
|
};
|
|
650
|
+
let search_outer = search_outer.unwrap_or(false);
|
|
602
651
|
|
|
603
652
|
// storage for each possible contraction to reach subgraph of size m
|
|
604
653
|
let mut contractions: Vec<Dict<Subgraph, SubContraction>> =
|
|
@@ -624,7 +673,7 @@ impl ContractionProcessor {
|
|
|
624
673
|
|
|
625
674
|
let mut ip: usize;
|
|
626
675
|
let mut jp: usize;
|
|
627
|
-
let mut
|
|
676
|
+
let mut skip_because_outer: bool;
|
|
628
677
|
|
|
629
678
|
let cost_cap_incr = f32::ln(2.0);
|
|
630
679
|
let mut cost_cap = cost_cap.unwrap_or(cost_cap_incr);
|
|
@@ -647,7 +696,8 @@ impl ContractionProcessor {
|
|
|
647
696
|
let mut temp_legs: Legs = Vec::with_capacity(ilegs.len() + jlegs.len());
|
|
648
697
|
ip = 0;
|
|
649
698
|
jp = 0;
|
|
650
|
-
|
|
699
|
+
// if search_outer -> we will never skip
|
|
700
|
+
skip_because_outer = !search_outer;
|
|
651
701
|
while ip < ilegs.len() && jp < jlegs.len() {
|
|
652
702
|
if ilegs[ip].0 < jlegs[jp].0 {
|
|
653
703
|
// index only appears in ilegs
|
|
@@ -662,10 +712,10 @@ impl ContractionProcessor {
|
|
|
662
712
|
temp_legs.push((ilegs[ip].0, ilegs[ip].1 + jlegs[jp].1));
|
|
663
713
|
ip += 1;
|
|
664
714
|
jp += 1;
|
|
665
|
-
|
|
715
|
+
skip_because_outer = false;
|
|
666
716
|
}
|
|
667
717
|
}
|
|
668
|
-
if
|
|
718
|
+
if skip_because_outer {
|
|
669
719
|
// no shared indices -> outer product
|
|
670
720
|
continue;
|
|
671
721
|
}
|
|
@@ -683,7 +733,7 @@ impl ContractionProcessor {
|
|
|
683
733
|
);
|
|
684
734
|
|
|
685
735
|
if new_score > cost_cap {
|
|
686
|
-
// contraction not allowed yet due to
|
|
736
|
+
// contraction not allowed yet due to 'sieve'
|
|
687
737
|
continue;
|
|
688
738
|
}
|
|
689
739
|
|
|
@@ -711,10 +761,10 @@ impl ContractionProcessor {
|
|
|
711
761
|
}
|
|
712
762
|
}
|
|
713
763
|
}
|
|
714
|
-
// move new contractions from temp into the main storage,
|
|
715
|
-
// might be contractions for the same subgraph in
|
|
716
|
-
// because we check eagerly best_scores above,
|
|
717
|
-
// are guaranteed to be better
|
|
764
|
+
// move new contractions from temp into the main storage,
|
|
765
|
+
// there might be contractions for the same subgraph in
|
|
766
|
+
// this, but because we check eagerly best_scores above,
|
|
767
|
+
// later entries are guaranteed to be better
|
|
718
768
|
contractions_m_temp.drain(..).for_each(|(k, v)| {
|
|
719
769
|
contractions[m].insert(k, v);
|
|
720
770
|
});
|
|
@@ -722,7 +772,7 @@ impl ContractionProcessor {
|
|
|
722
772
|
}
|
|
723
773
|
cost_cap += cost_cap_incr;
|
|
724
774
|
}
|
|
725
|
-
// can only ever be a single entry in contractions[nterms] -> the best
|
|
775
|
+
// can only ever be a single entry in contractions[nterms] -> the best
|
|
726
776
|
let (_, _, best_path) = contractions[nterms].values().next().unwrap();
|
|
727
777
|
|
|
728
778
|
// convert from the bitpath to the actual (subgraph) node ids
|
|
@@ -738,17 +788,45 @@ impl ContractionProcessor {
|
|
|
738
788
|
fn optimize_optimal(
|
|
739
789
|
&mut self,
|
|
740
790
|
minimize: Option<String>,
|
|
741
|
-
factor: Option<Score>,
|
|
742
791
|
cost_cap: Option<Score>,
|
|
792
|
+
search_outer: Option<bool>,
|
|
743
793
|
) {
|
|
744
794
|
for subgraph in self.subgraphs() {
|
|
745
|
-
self.optimize_optimal_connected(subgraph, minimize.clone(),
|
|
795
|
+
self.optimize_optimal_connected(subgraph, minimize.clone(), cost_cap, search_outer);
|
|
746
796
|
}
|
|
747
797
|
}
|
|
748
798
|
}
|
|
749
799
|
|
|
750
800
|
// --------------------------- PYTHON FUNCTIONS ---------------------------- //
|
|
751
801
|
|
|
802
|
+
#[pyfunction]
|
|
803
|
+
#[pyo3()]
|
|
804
|
+
fn ssa_to_linear(ssa_path: SSAPath, n: Option<usize>) -> SSAPath {
|
|
805
|
+
let n = match n {
|
|
806
|
+
Some(n) => n,
|
|
807
|
+
None => ssa_path.iter().map(|v| v.len()).sum::<usize>() + ssa_path.len() + 1,
|
|
808
|
+
};
|
|
809
|
+
let mut ids: Vec<Node> = (0..n).map(|i| i as Node).collect();
|
|
810
|
+
let mut path: SSAPath = Vec::with_capacity(2 * n - 1);
|
|
811
|
+
let mut ssa = n as Node;
|
|
812
|
+
for scon in ssa_path {
|
|
813
|
+
// find the locations of the ssa ids in the list of ids
|
|
814
|
+
let mut con: Vec<Node> = scon
|
|
815
|
+
.iter()
|
|
816
|
+
.map(|s| ids.binary_search(s).unwrap() as Node)
|
|
817
|
+
.collect();
|
|
818
|
+
// remove the ssa ids from the list
|
|
819
|
+
con.sort();
|
|
820
|
+
for j in con.iter().rev() {
|
|
821
|
+
ids.remove(*j as usize);
|
|
822
|
+
}
|
|
823
|
+
path.push(con);
|
|
824
|
+
ids.push(ssa);
|
|
825
|
+
ssa += 1;
|
|
826
|
+
}
|
|
827
|
+
path
|
|
828
|
+
}
|
|
829
|
+
|
|
752
830
|
#[pyfunction]
|
|
753
831
|
#[pyo3()]
|
|
754
832
|
fn find_subgraphs(
|
|
@@ -766,10 +844,16 @@ fn optimize_simplify(
|
|
|
766
844
|
inputs: Vec<Vec<char>>,
|
|
767
845
|
output: Vec<char>,
|
|
768
846
|
size_dict: Dict<char, f32>,
|
|
847
|
+
use_ssa: Option<bool>,
|
|
769
848
|
) -> SSAPath {
|
|
849
|
+
let n = inputs.len();
|
|
770
850
|
let mut cp = ContractionProcessor::new(inputs, output, size_dict);
|
|
771
851
|
cp.simplify();
|
|
772
|
-
|
|
852
|
+
if use_ssa.unwrap_or(false) {
|
|
853
|
+
cp.ssa_path
|
|
854
|
+
} else {
|
|
855
|
+
ssa_to_linear(cp.ssa_path, Some(n))
|
|
856
|
+
}
|
|
773
857
|
}
|
|
774
858
|
|
|
775
859
|
#[pyfunction]
|
|
@@ -781,15 +865,23 @@ fn optimize_greedy(
|
|
|
781
865
|
costmod: Option<f32>,
|
|
782
866
|
temperature: Option<f32>,
|
|
783
867
|
simplify: Option<bool>,
|
|
868
|
+
use_ssa: Option<bool>,
|
|
784
869
|
) -> Vec<Vec<Node>> {
|
|
870
|
+
let n = inputs.len();
|
|
785
871
|
let mut cp = ContractionProcessor::new(inputs, output, size_dict);
|
|
786
872
|
if simplify.unwrap_or(true) {
|
|
873
|
+
// perform simplifications
|
|
787
874
|
cp.simplify();
|
|
788
875
|
}
|
|
876
|
+
// greddily contract each connected subgraph
|
|
789
877
|
cp.optimize_greedy(costmod, temperature);
|
|
790
878
|
// optimize any remaining disconnected terms
|
|
791
879
|
cp.optimize_remaining_by_size();
|
|
792
|
-
|
|
880
|
+
if use_ssa.unwrap_or(false) {
|
|
881
|
+
cp.ssa_path
|
|
882
|
+
} else {
|
|
883
|
+
ssa_to_linear(cp.ssa_path, Some(n))
|
|
884
|
+
}
|
|
793
885
|
}
|
|
794
886
|
|
|
795
887
|
#[pyfunction]
|
|
@@ -799,23 +891,32 @@ fn optimize_optimal(
|
|
|
799
891
|
output: Vec<char>,
|
|
800
892
|
size_dict: Dict<char, f32>,
|
|
801
893
|
minimize: Option<String>,
|
|
802
|
-
factor: Option<Score>,
|
|
803
894
|
cost_cap: Option<Score>,
|
|
895
|
+
search_outer: Option<bool>,
|
|
804
896
|
simplify: Option<bool>,
|
|
897
|
+
use_ssa: Option<bool>,
|
|
805
898
|
) -> Vec<Vec<Node>> {
|
|
899
|
+
let n = inputs.len();
|
|
806
900
|
let mut cp = ContractionProcessor::new(inputs, output, size_dict);
|
|
807
901
|
if simplify.unwrap_or(true) {
|
|
902
|
+
// perform simplifications
|
|
808
903
|
cp.simplify();
|
|
809
904
|
}
|
|
810
|
-
|
|
905
|
+
// optimally contract each connected subgraph
|
|
906
|
+
cp.optimize_optimal(minimize, cost_cap, search_outer);
|
|
811
907
|
// optimize any remaining disconnected terms
|
|
812
908
|
cp.optimize_remaining_by_size();
|
|
813
|
-
|
|
909
|
+
if use_ssa.unwrap_or(false) {
|
|
910
|
+
cp.ssa_path
|
|
911
|
+
} else {
|
|
912
|
+
ssa_to_linear(cp.ssa_path, Some(n))
|
|
913
|
+
}
|
|
814
914
|
}
|
|
815
915
|
|
|
816
916
|
/// A Python module implemented in Rust.
|
|
817
917
|
#[pymodule]
|
|
818
918
|
fn cotengrust(_py: Python, m: &PyModule) -> PyResult<()> {
|
|
919
|
+
m.add_function(wrap_pyfunction!(ssa_to_linear, m)?)?;
|
|
819
920
|
m.add_function(wrap_pyfunction!(find_subgraphs, m)?)?;
|
|
820
921
|
m.add_function(wrap_pyfunction!(optimize_simplify, m)?)?;
|
|
821
922
|
m.add_function(wrap_pyfunction!(optimize_greedy, m)?)?;
|
|
@@ -0,0 +1,205 @@
|
|
|
1
|
+
import pytest
|
|
2
|
+
|
|
3
|
+
try:
|
|
4
|
+
import cotengra as ctg
|
|
5
|
+
|
|
6
|
+
ctg_missing = False
|
|
7
|
+
except ImportError:
|
|
8
|
+
ctg_missing = True
|
|
9
|
+
ctg = None
|
|
10
|
+
|
|
11
|
+
import cotengrust as ctgr
|
|
12
|
+
|
|
13
|
+
|
|
14
|
+
requires_cotengra = pytest.mark.skipif(ctg_missing, reason="requires cotengra")
|
|
15
|
+
|
|
16
|
+
|
|
17
|
+
@pytest.mark.parametrize("which", ["greedy", "optimal"])
|
|
18
|
+
def test_basic_call(which):
|
|
19
|
+
inputs = [('a', 'b'), ('b', 'c'), ('c', 'd'), ('d', 'a')]
|
|
20
|
+
output = ('b', 'd')
|
|
21
|
+
size_dict = {'a': 2, 'b': 3, 'c': 4, 'd': 5}
|
|
22
|
+
path = {
|
|
23
|
+
"greedy": ctgr.optimize_greedy,
|
|
24
|
+
"optimal": ctgr.optimize_optimal,
|
|
25
|
+
}[
|
|
26
|
+
which
|
|
27
|
+
](inputs, output, size_dict)
|
|
28
|
+
assert all(len(con) <= 2 for con in path)
|
|
29
|
+
|
|
30
|
+
|
|
31
|
+
def find_output_str(lhs):
|
|
32
|
+
tmp_lhs = lhs.replace(",", "")
|
|
33
|
+
return "".join(s for s in sorted(set(tmp_lhs)) if tmp_lhs.count(s) == 1)
|
|
34
|
+
|
|
35
|
+
|
|
36
|
+
def eq_to_inputs_output(eq):
|
|
37
|
+
if "->" not in eq:
|
|
38
|
+
eq += "->" + find_output_str(eq)
|
|
39
|
+
inputs, output = eq.split("->")
|
|
40
|
+
inputs = inputs.split(",")
|
|
41
|
+
inputs = [list(s) for s in inputs]
|
|
42
|
+
output = list(output)
|
|
43
|
+
return inputs, output
|
|
44
|
+
|
|
45
|
+
|
|
46
|
+
def get_rand_size_dict(inputs, d_min=2, d_max=3):
|
|
47
|
+
import random
|
|
48
|
+
|
|
49
|
+
size_dict = {}
|
|
50
|
+
for term in inputs:
|
|
51
|
+
for ix in term:
|
|
52
|
+
if ix not in size_dict:
|
|
53
|
+
size_dict[ix] = random.randint(d_min, d_max)
|
|
54
|
+
return size_dict
|
|
55
|
+
|
|
56
|
+
|
|
57
|
+
# these are taken from opt_einsum
|
|
58
|
+
test_case_eqs = [
|
|
59
|
+
# Test scalar-like operations
|
|
60
|
+
"a,->a",
|
|
61
|
+
"ab,->ab",
|
|
62
|
+
",ab,->ab",
|
|
63
|
+
",,->",
|
|
64
|
+
# Test hadamard-like products
|
|
65
|
+
"a,ab,abc->abc",
|
|
66
|
+
"a,b,ab->ab",
|
|
67
|
+
# Test index-transformations
|
|
68
|
+
"ea,fb,gc,hd,abcd->efgh",
|
|
69
|
+
"ea,fb,abcd,gc,hd->efgh",
|
|
70
|
+
"abcd,ea,fb,gc,hd->efgh",
|
|
71
|
+
# Test complex contractions
|
|
72
|
+
"acdf,jbje,gihb,hfac,gfac,gifabc,hfac",
|
|
73
|
+
"cd,bdhe,aidb,hgca,gc,hgibcd,hgac",
|
|
74
|
+
"abhe,hidj,jgba,hiab,gab",
|
|
75
|
+
"bde,cdh,agdb,hica,ibd,hgicd,hiac",
|
|
76
|
+
"chd,bde,agbc,hiad,hgc,hgi,hiad",
|
|
77
|
+
"chd,bde,agbc,hiad,bdi,cgh,agdb",
|
|
78
|
+
"bdhe,acad,hiab,agac,hibd",
|
|
79
|
+
# Test collapse
|
|
80
|
+
"ab,ab,c->",
|
|
81
|
+
"ab,ab,c->c",
|
|
82
|
+
"ab,ab,cd,cd->",
|
|
83
|
+
"ab,ab,cd,cd->ac",
|
|
84
|
+
"ab,ab,cd,cd->cd",
|
|
85
|
+
"ab,ab,cd,cd,ef,ef->",
|
|
86
|
+
# Test outer prodcuts
|
|
87
|
+
"ab,cd,ef->abcdef",
|
|
88
|
+
"ab,cd,ef->acdf",
|
|
89
|
+
"ab,cd,de->abcde",
|
|
90
|
+
"ab,cd,de->be",
|
|
91
|
+
"ab,bcd,cd->abcd",
|
|
92
|
+
"ab,bcd,cd->abd",
|
|
93
|
+
# Random test cases that have previously failed
|
|
94
|
+
"eb,cb,fb->cef",
|
|
95
|
+
"dd,fb,be,cdb->cef",
|
|
96
|
+
"bca,cdb,dbf,afc->",
|
|
97
|
+
"dcc,fce,ea,dbf->ab",
|
|
98
|
+
"fdf,cdd,ccd,afe->ae",
|
|
99
|
+
"abcd,ad",
|
|
100
|
+
"ed,fcd,ff,bcf->be",
|
|
101
|
+
"baa,dcf,af,cde->be",
|
|
102
|
+
"bd,db,eac->ace",
|
|
103
|
+
"fff,fae,bef,def->abd",
|
|
104
|
+
"efc,dbc,acf,fd->abe",
|
|
105
|
+
# Inner products
|
|
106
|
+
"ab,ab",
|
|
107
|
+
"ab,ba",
|
|
108
|
+
"abc,abc",
|
|
109
|
+
"abc,bac",
|
|
110
|
+
"abc,cba",
|
|
111
|
+
# GEMM test cases
|
|
112
|
+
"ab,bc",
|
|
113
|
+
"ab,cb",
|
|
114
|
+
"ba,bc",
|
|
115
|
+
"ba,cb",
|
|
116
|
+
"abcd,cd",
|
|
117
|
+
"abcd,ab",
|
|
118
|
+
"abcd,cdef",
|
|
119
|
+
"abcd,cdef->feba",
|
|
120
|
+
"abcd,efdc",
|
|
121
|
+
# Inner than dot
|
|
122
|
+
"aab,bc->ac",
|
|
123
|
+
"ab,bcc->ac",
|
|
124
|
+
"aab,bcc->ac",
|
|
125
|
+
"baa,bcc->ac",
|
|
126
|
+
"aab,ccb->ac",
|
|
127
|
+
# Randomly built test caes
|
|
128
|
+
"aab,fa,df,ecc->bde",
|
|
129
|
+
"ecb,fef,bad,ed->ac",
|
|
130
|
+
"bcf,bbb,fbf,fc->",
|
|
131
|
+
"bb,ff,be->e",
|
|
132
|
+
"bcb,bb,fc,fff->",
|
|
133
|
+
"fbb,dfd,fc,fc->",
|
|
134
|
+
"afd,ba,cc,dc->bf",
|
|
135
|
+
"adb,bc,fa,cfc->d",
|
|
136
|
+
"bbd,bda,fc,db->acf",
|
|
137
|
+
"dba,ead,cad->bce",
|
|
138
|
+
"aef,fbc,dca->bde",
|
|
139
|
+
]
|
|
140
|
+
|
|
141
|
+
|
|
142
|
+
@requires_cotengra
|
|
143
|
+
@pytest.mark.parametrize("eq", test_case_eqs)
|
|
144
|
+
@pytest.mark.parametrize("which", ["greedy", "optimal"])
|
|
145
|
+
def test_manual_cases(eq, which):
|
|
146
|
+
inputs, output = eq_to_inputs_output(eq)
|
|
147
|
+
size_dict = get_rand_size_dict(inputs)
|
|
148
|
+
path = {
|
|
149
|
+
"greedy": ctgr.optimize_greedy,
|
|
150
|
+
"optimal": ctgr.optimize_optimal,
|
|
151
|
+
}[
|
|
152
|
+
which
|
|
153
|
+
](inputs, output, size_dict)
|
|
154
|
+
assert all(len(con) <= 2 for con in path)
|
|
155
|
+
tree = ctg.ContractionTree.from_path(
|
|
156
|
+
inputs, output, size_dict, path=path, check=True
|
|
157
|
+
)
|
|
158
|
+
assert tree.is_complete()
|
|
159
|
+
|
|
160
|
+
|
|
161
|
+
@requires_cotengra
|
|
162
|
+
@pytest.mark.parametrize("seed", range(10))
|
|
163
|
+
@pytest.mark.parametrize("which", ["greedy", "optimal"])
|
|
164
|
+
def test_basic_rand(seed, which):
|
|
165
|
+
inputs, output, shapes, size_dict = ctg.utils.rand_equation(
|
|
166
|
+
n=10,
|
|
167
|
+
reg=4,
|
|
168
|
+
n_out=2,
|
|
169
|
+
n_hyper_in=1,
|
|
170
|
+
n_hyper_out=1,
|
|
171
|
+
d_min=2,
|
|
172
|
+
d_max=3,
|
|
173
|
+
seed=seed,
|
|
174
|
+
)
|
|
175
|
+
path = {
|
|
176
|
+
"greedy": ctgr.optimize_greedy,
|
|
177
|
+
"optimal": ctgr.optimize_optimal,
|
|
178
|
+
}[
|
|
179
|
+
which
|
|
180
|
+
](inputs, output, size_dict)
|
|
181
|
+
assert all(len(con) <= 2 for con in path)
|
|
182
|
+
tree = ctg.ContractionTree.from_path(
|
|
183
|
+
inputs, output, size_dict, path=path, check=True
|
|
184
|
+
)
|
|
185
|
+
assert tree.is_complete()
|
|
186
|
+
|
|
187
|
+
|
|
188
|
+
@requires_cotengra
|
|
189
|
+
def test_optimal_lattice_eq():
|
|
190
|
+
inputs, output, _, size_dict = ctg.utils.lattice_equation(
|
|
191
|
+
[4, 5], d_max=3, seed=42
|
|
192
|
+
)
|
|
193
|
+
|
|
194
|
+
path = ctgr.optimize_optimal(inputs, output, size_dict, minimize='flops')
|
|
195
|
+
tree = ctg.ContractionTree.from_path(
|
|
196
|
+
inputs, output, size_dict, path=path
|
|
197
|
+
)
|
|
198
|
+
assert tree.contraction_cost() == 3628
|
|
199
|
+
|
|
200
|
+
path = ctgr.optimize_optimal(inputs, output, size_dict, minimize='size')
|
|
201
|
+
assert all(len(con) <= 2 for con in path)
|
|
202
|
+
tree = ctg.ContractionTree.from_path(
|
|
203
|
+
inputs, output, size_dict, path=path
|
|
204
|
+
)
|
|
205
|
+
assert tree.contraction_width() == pytest.approx(6.754887502163468)
|
cotengrust-0.1.0/PKG-INFO
DELETED
|
@@ -1,8 +0,0 @@
|
|
|
1
|
-
Metadata-Version: 2.1
|
|
2
|
-
Name: cotengrust
|
|
3
|
-
Version: 0.1.0
|
|
4
|
-
Classifier: Programming Language :: Rust
|
|
5
|
-
Classifier: Programming Language :: Python :: Implementation :: CPython
|
|
6
|
-
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
|
7
|
-
License-File: LICENSE
|
|
8
|
-
Requires-Python: >=3.7
|
|
File without changes
|
|
File without changes
|