biopipen 0.27.2__tar.gz → 0.27.8__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
Potentially problematic release.
This version of biopipen might be problematic. Click here for more details.
- {biopipen-0.27.2 → biopipen-0.27.8}/PKG-INFO +2 -2
- biopipen-0.27.8/biopipen/__init__.py +1 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/filters.py +5 -4
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/testing.py +4 -14
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/delim.py +1 -1
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/plot.py +36 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/scrna.py +56 -18
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/scrna_metabolic_landscape.py +7 -7
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/snp.py +65 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/tcr.py +6 -6
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/delim/SampleInfo.R +6 -6
- biopipen-0.27.8/biopipen/scripts/plot/ROC.R +88 -0
- biopipen-0.27.8/biopipen/scripts/scrna/ExprImputation.R +7 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/MarkersFinder.R +30 -5
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/MetaMarkers.R +17 -3
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/ScFGSEA.R +21 -4
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats-features.R +1 -1
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats-stats.R +1 -1
- biopipen-0.27.8/biopipen/scripts/scrna/SeuratMap2Ref.R +302 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratPreparing.R +276 -113
- biopipen-0.27.8/biopipen/scripts/scrna/SeuratTo10X.R +27 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna_metabolic_landscape/MetabolicFeatures.R +17 -6
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna_metabolic_landscape/MetabolicFeaturesIntraSubset.R +9 -5
- biopipen-0.27.8/biopipen/scripts/snp/MatrixEQTL.R +157 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/gsea.R +39 -8
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/misc.R +1 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/pyproject.toml +2 -2
- {biopipen-0.27.2 → biopipen-0.27.8}/setup.py +2 -2
- biopipen-0.27.2/biopipen/__init__.py +0 -1
- biopipen-0.27.2/biopipen/scripts/scrna/ExprImpution.R +0 -7
- biopipen-0.27.2/biopipen/scripts/scrna/SeuratMap2Ref.R +0 -156
- biopipen-0.27.2/biopipen/scripts/scrna/Write10X.R +0 -11
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/__init__.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/config.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/config.toml +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/defaults.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/core/proc.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/__init__.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/bam.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/bcftools.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/bed.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/cellranger.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/cellranger_pipeline.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/cnv.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/cnvkit.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/cnvkit_pipeline.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/gene.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/gsea.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/misc.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/rnaseq.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/stats.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/tcgamaf.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/vcf.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/ns/web.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/bam/CNAClinic.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/bam/CNVpytor.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/bam/ControlFREEC.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cellranger/CellRangerCount.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cellranger/CellRangerSummary.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cellranger/CellRangerVdj.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnv/AneuploidyScore.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnv/AneuploidyScoreSummary.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnv/TMADScoreSummary.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnvkit/CNVkitDiagram.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnvkit/CNVkitHeatmap.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/cnvkit/CNVkitScatter.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/delim/SampleInfo.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/gsea/FGSEA.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/gsea/GSEA.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/CellsDistribution.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/DimPlots.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/MarkersFinder.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/MetaMarkers.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/RadarPlots.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/ScFGSEA.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/SeuratClusterStats.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/SeuratMap2Ref.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/SeuratPreparing.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna/TopExpressingGenes.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna_metabolic_landscape/MetabolicFeatures.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna_metabolic_landscape/MetabolicFeaturesIntraSubset.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna_metabolic_landscape/MetabolicPathwayActivity.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/scrna_metabolic_landscape/MetabolicPathwayHeterogeneity.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/CDR3AAPhyschem.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/CloneResidency.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/Immunarch.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/SampleDiversity.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/TCRClusterStats.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/TESSA.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/tcr/VJUsage.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/utils/gsea.liq +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/utils/misc.liq +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/vcf/TruvariBenchSummary.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/reports/vcf/TruvariConsistency.svelte +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bam/BamMerge.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bam/BamSplitChroms.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bam/CNAClinic.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bam/CNVpytor.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bam/ControlFREEC.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bcftools/BcftoolsAnnotate.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bcftools/BcftoolsFilter.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bcftools/BcftoolsSort.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bed/Bed2Vcf.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bed/BedConsensus.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bed/BedLiftOver.sh +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/bed/BedtoolsMerge.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cellranger/CellRangerCount.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cellranger/CellRangerSummary.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cellranger/CellRangerVdj.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnv/AneuploidyScore.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnv/AneuploidyScoreSummary.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnv/TMADScore.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnv/TMADScoreSummary.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitAccess.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitAutobin.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitBatch.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitCall.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitCoverage.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitDiagram.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitFix.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitGuessBaits.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitHeatmap.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitReference.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitScatter.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/CNVkitSegment.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/cnvkit/guess_baits.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/delim/RowsBinder.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/gene/GeneNameConversion.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/gsea/Enrichr.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/gsea/FGSEA.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/gsea/GSEA.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/gsea/PreRank.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/misc/Config2File.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/misc/Str2File.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/plot/Heatmap.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/plot/VennDiagram.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/rnaseq/Simulation-ESCO.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/rnaseq/Simulation-RUVcorr.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/rnaseq/Simulation.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/rnaseq/UnitConversion.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/AnnData2Seurat.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation-celltypist.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation-direct.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation-hitype.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation-sccatch.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation-sctype.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellTypeAnnotation.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/CellsDistribution.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/DimPlots.R +0 -0
- /biopipen-0.27.2/biopipen/scripts/scrna/ExprImpution-alra.R → /biopipen-0.27.8/biopipen/scripts/scrna/ExprImputation-alra.R +0 -0
- /biopipen-0.27.2/biopipen/scripts/scrna/ExprImpution-rmagic.R → /biopipen-0.27.8/biopipen/scripts/scrna/ExprImputation-rmagic.R +0 -0
- /biopipen-0.27.2/biopipen/scripts/scrna/ExprImpution-scimpute.R → /biopipen-0.27.8/biopipen/scripts/scrna/ExprImputation-scimpute.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/ModuleScoreCalculator.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/RadarPlots.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SCImpute.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/Seurat2AnnData.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats-dimplots.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats-hists.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats-ngenes.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClusterStats.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratClustering.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratFilter.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratLoading.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratMetadataMutater.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratSplit.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratSubClustering.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/SeuratSubset.R +0 -0
- /biopipen-0.27.2/biopipen/scripts/scrna/SeuratTo10X.R → /biopipen-0.27.8/biopipen/scripts/scrna/Subset10X.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/TopExpressingGenes.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/celltypist-wrapper.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna/sctype.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna_metabolic_landscape/MetabolicPathwayActivity.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/scrna_metabolic_landscape/MetabolicPathwayHeterogeneity.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/snp/PlinkSimulation.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/stats/ChowTest.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/stats/DiffCoexpr.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/stats/LiquidAssoc.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/stats/MetaPvalue.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcgamaf/Maf2Vcf.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcgamaf/MafAddChr.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcgamaf/maf2vcf.pl +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Attach2Seurat.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/CDR3AAPhyschem.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/CloneResidency.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/CloneSizeQQPlot.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/GIANA/GIANA.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/GIANA/GIANA4.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/GIANA/Imgt_Human_TRBV.fasta +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/GIANA/query.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-basic.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-clonality.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-diversity.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-geneusage.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-kmer.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-overlap.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-spectratyping.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-tracking.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch-vjjunc.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/Immunarch2VDJtools.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/ImmunarchFilter.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/ImmunarchLoading.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/ImmunarchSplitIdents.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/SampleDiversity.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TCRClusterStats.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TCRClustering.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TCRDock.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/Atchley_factors.csv +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/BriseisEncoder.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/MCMC_control.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/TrainedEncoder.h5 +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/fixed_b.csv +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/initialization.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/post_analysis.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/real_data.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/update.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/TESSA_source/utility.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/VJUsage.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/immunarch-patched.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/tcr/vdjtools-patch.sh +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/TruvariBench.sh +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/TruvariBenchSummary.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/TruvariConsistency.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/Vcf2Bed.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfAnno.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfDownSample.sh +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfFilter.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfFix.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfFix_utils.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfIndex.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfIntersect.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfLiftOver.sh +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/vcf/VcfSplitSamples.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/web/Download.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/scripts/web/DownloadList.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/__init__.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/caching.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/common_docstrs.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/gene.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/gene.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/io.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/misc.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/mutate_helpers.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/plot.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/reference.py +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/rnaseq.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/single_cell.R +0 -0
- {biopipen-0.27.2 → biopipen-0.27.8}/biopipen/utils/vcf.py +0 -0
|
@@ -1,6 +1,6 @@
|
|
|
1
1
|
Metadata-Version: 2.1
|
|
2
2
|
Name: biopipen
|
|
3
|
-
Version: 0.27.
|
|
3
|
+
Version: 0.27.8
|
|
4
4
|
Summary: Bioinformatics processes/pipelines that can be run from `pipen run`
|
|
5
5
|
License: MIT
|
|
6
6
|
Author: pwwang
|
|
@@ -17,6 +17,6 @@ Requires-Dist: datar[pandas] (>=0.15.6,<0.16.0)
|
|
|
17
17
|
Requires-Dist: pipen-board[report] (>=0.15,<0.16)
|
|
18
18
|
Requires-Dist: pipen-cli-run (>=0.13,<0.14)
|
|
19
19
|
Requires-Dist: pipen-filters (>=0.12,<0.13)
|
|
20
|
-
Requires-Dist: pipen-poplog (>=0.1,<0.2)
|
|
20
|
+
Requires-Dist: pipen-poplog (>=0.1.2,<0.2.0)
|
|
21
21
|
Requires-Dist: pipen-runinfo (>=0.6,<0.7) ; extra == "runinfo"
|
|
22
22
|
Requires-Dist: pipen-verbose (>=0.11,<0.12)
|
|
@@ -0,0 +1 @@
|
|
|
1
|
+
__version__ = "0.27.8"
|
|
@@ -235,8 +235,8 @@ def _render_fgsea(
|
|
|
235
235
|
with Path(cont["dir"]).joinpath("fgsea.txt").open() as f:
|
|
236
236
|
next(f) # skip header
|
|
237
237
|
for line in f:
|
|
238
|
-
|
|
239
|
-
pathways.append(
|
|
238
|
+
items = line.strip().split("\t")
|
|
239
|
+
pathways.append((items[0], items[-1]))
|
|
240
240
|
if len(pathways) >= n_pathways:
|
|
241
241
|
break
|
|
242
242
|
|
|
@@ -263,6 +263,7 @@ def _render_fgsea(
|
|
|
263
263
|
{
|
|
264
264
|
"kind": "table",
|
|
265
265
|
"src": str(Path(cont["dir"]).joinpath("fgsea.txt")),
|
|
266
|
+
"data": {"excluded": {"slug"}},
|
|
266
267
|
}
|
|
267
268
|
],
|
|
268
269
|
},
|
|
@@ -274,10 +275,10 @@ def _render_fgsea(
|
|
|
274
275
|
"ui": "table_of_images",
|
|
275
276
|
"contents": [
|
|
276
277
|
{
|
|
277
|
-
"src": str(Path(cont["dir"]) / f"fgsea_{
|
|
278
|
+
"src": str(Path(cont["dir"]) / f"fgsea_{slug}.png"),
|
|
278
279
|
"title": pw,
|
|
279
280
|
}
|
|
280
|
-
for pw in pathways
|
|
281
|
+
for pw, slug in pathways
|
|
281
282
|
]
|
|
282
283
|
},
|
|
283
284
|
]
|
|
@@ -3,7 +3,7 @@ import tempfile
|
|
|
3
3
|
from functools import wraps
|
|
4
4
|
from pathlib import Path
|
|
5
5
|
|
|
6
|
-
from pipen import Pipen
|
|
6
|
+
from pipen import Pipen
|
|
7
7
|
|
|
8
8
|
TESTING_INDEX_INIT = 1
|
|
9
9
|
TESTING_PARENT_DIR = Path(tempfile.gettempdir())
|
|
@@ -40,26 +40,16 @@ def _get_test_dirs(testfile, new):
|
|
|
40
40
|
return name, workdir, outdir
|
|
41
41
|
|
|
42
42
|
|
|
43
|
-
|
|
44
|
-
"""A plugin to check if the pipeline succeeded"""
|
|
45
|
-
|
|
46
|
-
name = "succeeded"
|
|
47
|
-
version = "0.1.0"
|
|
48
|
-
|
|
49
|
-
@plugin.impl
|
|
50
|
-
async def on_complete(pipen, succeeded):
|
|
51
|
-
pipen._succeeded = succeeded
|
|
52
|
-
|
|
53
|
-
|
|
54
|
-
def get_pipeline(testfile, loglevel="debug", **kwargs):
|
|
43
|
+
def get_pipeline(testfile, loglevel="debug", enable_report=False, **kwargs):
|
|
55
44
|
"""Get a pipeline for a test file"""
|
|
56
45
|
name, workdir, outdir = _get_test_dirs(testfile, False)
|
|
46
|
+
report_plugin_prefix = "+" if enable_report else "-"
|
|
57
47
|
kws = {
|
|
58
48
|
"name": name,
|
|
59
49
|
"workdir": workdir,
|
|
60
50
|
"outdir": outdir,
|
|
61
51
|
"loglevel": loglevel,
|
|
62
|
-
"plugins": [
|
|
52
|
+
"plugins": [f"{report_plugin_prefix}report"],
|
|
63
53
|
}
|
|
64
54
|
kws.update(kwargs)
|
|
65
55
|
return Pipen(**kws)
|
|
@@ -114,3 +114,39 @@ class Heatmap(Proc):
|
|
|
114
114
|
"globals": "",
|
|
115
115
|
}
|
|
116
116
|
script = "file://../scripts/plot/Heatmap.R"
|
|
117
|
+
|
|
118
|
+
|
|
119
|
+
class ROC(Proc):
|
|
120
|
+
"""Plot ROC curve using [`plotROC`](https://cran.r-project.org/web/packages/plotROC/vignettes/examples.html).
|
|
121
|
+
|
|
122
|
+
Input:
|
|
123
|
+
infile: The input file for data, tab-separated.
|
|
124
|
+
The first column should be ids of the records (this is optional if `envs.noids` is True).
|
|
125
|
+
The second column should be the labels of the records (1 for positive, 0 for negative).
|
|
126
|
+
If they are not binary, you can specify the positive label by `envs.pos_label`.
|
|
127
|
+
From the third column, it should be the scores of the different models.
|
|
128
|
+
|
|
129
|
+
Output:
|
|
130
|
+
outfile: The output figure file
|
|
131
|
+
|
|
132
|
+
Envs:
|
|
133
|
+
noids: Whether the input file has ids (first column) or not.
|
|
134
|
+
pos_label: The positive label.
|
|
135
|
+
ci: Whether to use `geom_rocci()` instead of `geom_roc()`.
|
|
136
|
+
devpars: The parameters for `png()`
|
|
137
|
+
args: Additional arguments for `geom_roc()` or `geom_rocci()` if `envs.ci` is True.
|
|
138
|
+
style_roc: Arguments for `style_roc()`
|
|
139
|
+
""" # noqa: E501
|
|
140
|
+
input = "infile:file"
|
|
141
|
+
output = "outfile:file:{{in.infile | stem}}.roc.png"
|
|
142
|
+
lang = config.lang.rscript
|
|
143
|
+
envs = {
|
|
144
|
+
"noids": False,
|
|
145
|
+
"pos_label": 1,
|
|
146
|
+
"ci": False,
|
|
147
|
+
"devpars": {"res": 100, "width": 750, "height": 600},
|
|
148
|
+
"args": {"labels": False},
|
|
149
|
+
"style_roc": {},
|
|
150
|
+
"show_auc": True,
|
|
151
|
+
}
|
|
152
|
+
script = "file://../scripts/plot/ROC.R"
|
|
@@ -122,6 +122,9 @@ class SeuratPreparing(Proc):
|
|
|
122
122
|
genes.
|
|
123
123
|
///
|
|
124
124
|
|
|
125
|
+
cell_qc_per_sample (flag): Whether to perform cell QC per sample or not.
|
|
126
|
+
If `True`, the cell QC will be performed per sample, and the QC will be
|
|
127
|
+
applied to each sample before merging.
|
|
125
128
|
gene_qc (ns): Filter genes.
|
|
126
129
|
`gene_qc` is applied after `cell_qc`.
|
|
127
130
|
- min_cells: The minimum number of cells that a gene must be
|
|
@@ -201,6 +204,13 @@ class SeuratPreparing(Proc):
|
|
|
201
204
|
- scvi: Same as `scVIIntegration`.
|
|
202
205
|
- <more>: See <https://satijalab.org/seurat/reference/integratelayers>
|
|
203
206
|
|
|
207
|
+
DoubletFinder (ns): Arguments to run [`DoubletFinder`](https://github.com/chris-mcginnis-ucsf/DoubletFinder).
|
|
208
|
+
See also <https://demultiplexing-doublet-detecting-docs.readthedocs.io/en/latest/DoubletFinder.html>.
|
|
209
|
+
To disable `DoubletFinder`, set `envs.DoubletFinder` to `None` or `False`; or set `pcs` to `0`.
|
|
210
|
+
- PCs (type=int): Number of PCs to use for 'doubletFinder' function.
|
|
211
|
+
- doublets (type=float): Number of expected doublets as a proportion of the pool size.
|
|
212
|
+
- pN (type=float): Number of doublets to simulate as a proportion of the pool size.
|
|
213
|
+
|
|
204
214
|
Requires:
|
|
205
215
|
r-seurat:
|
|
206
216
|
- check: {{proc.lang}} <(echo "library(Seurat)")
|
|
@@ -215,6 +225,7 @@ class SeuratPreparing(Proc):
|
|
|
215
225
|
envs = {
|
|
216
226
|
"ncores": config.misc.ncores,
|
|
217
227
|
"cell_qc": None, # "nFeature_RNA > 200 & percent.mt < 5",
|
|
228
|
+
"cell_qc_per_sample": False,
|
|
218
229
|
"gene_qc": {"min_cells": 0, "excludes": []},
|
|
219
230
|
"use_sct": False,
|
|
220
231
|
"no_integration": False,
|
|
@@ -227,6 +238,7 @@ class SeuratPreparing(Proc):
|
|
|
227
238
|
"min_cells": 5,
|
|
228
239
|
},
|
|
229
240
|
"IntegrateLayers": {"method": "harmony"},
|
|
241
|
+
"DoubletFinder": {"PCs": 0, "pN": 0.25, "doublets": 0.075},
|
|
230
242
|
}
|
|
231
243
|
script = "file://../scripts/scrna/SeuratPreparing.R"
|
|
232
244
|
plugin_opts = {
|
|
@@ -405,7 +417,7 @@ class SeuratClusterStats(Proc):
|
|
|
405
417
|
nCells_All = { }
|
|
406
418
|
```
|
|
407
419
|
|
|
408
|
-
{: width="80%" }
|
|
420
|
+
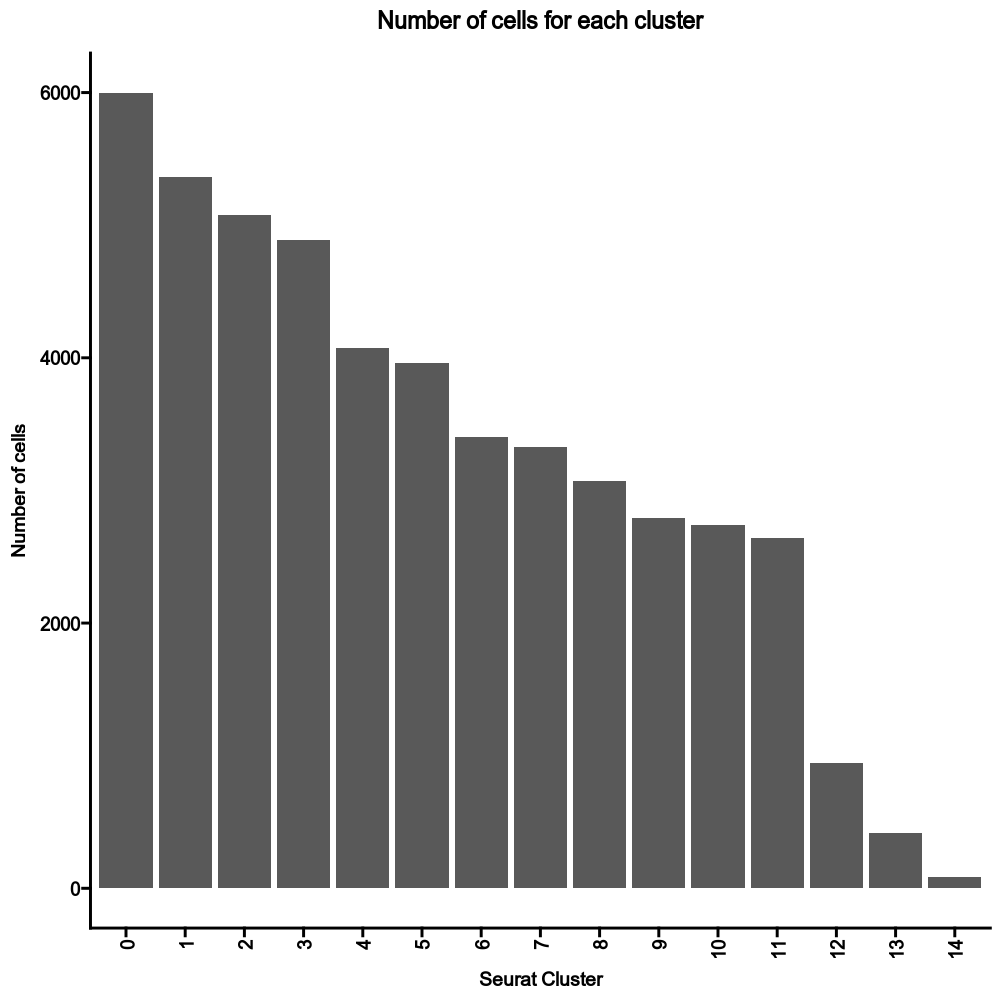{: width="80%" }
|
|
409
421
|
|
|
410
422
|
### Number of cells in each cluster by groups
|
|
411
423
|
|
|
@@ -414,7 +426,7 @@ class SeuratClusterStats(Proc):
|
|
|
414
426
|
nCells_Sample = { group-by = "Sample" }
|
|
415
427
|
```
|
|
416
428
|
|
|
417
|
-
{: width="80%" }
|
|
429
|
+
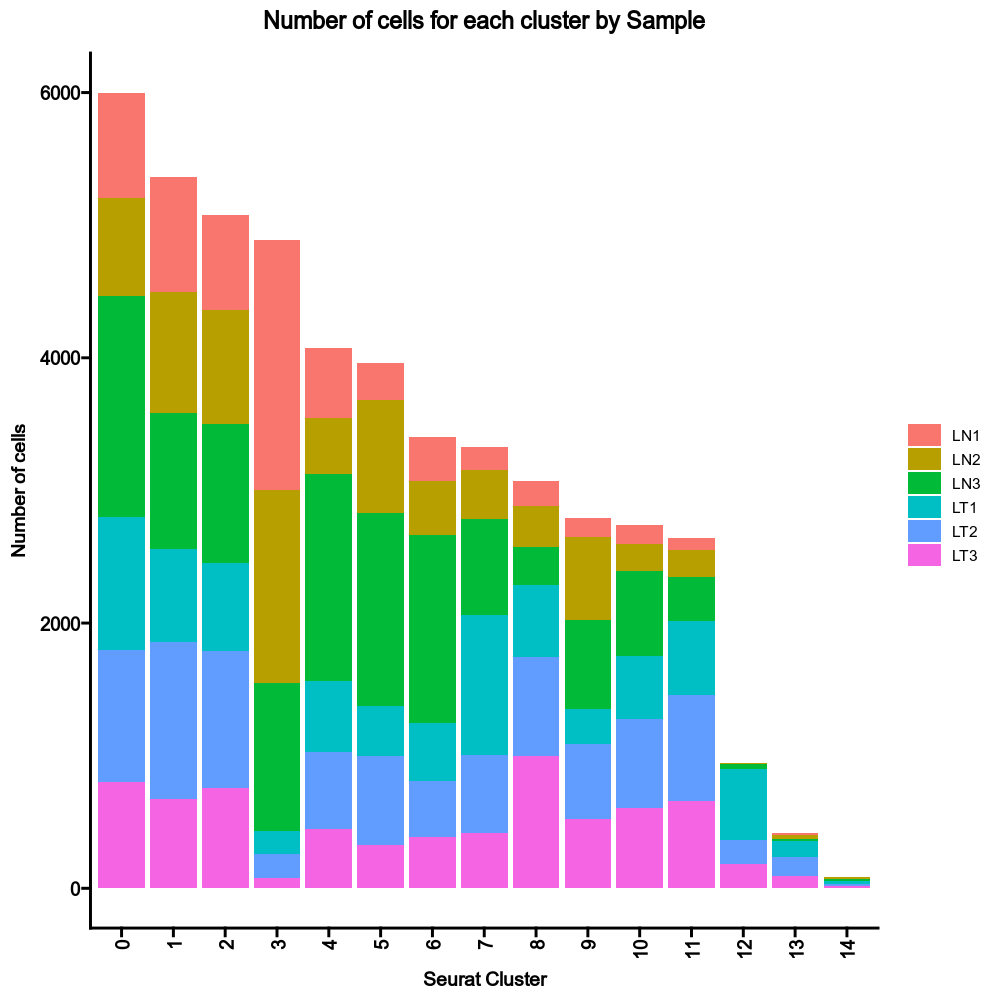{: width="80%" }
|
|
418
430
|
|
|
419
431
|
### Violin plots for the gene expressions
|
|
420
432
|
|
|
@@ -427,8 +439,8 @@ class SeuratClusterStats(Proc):
|
|
|
427
439
|
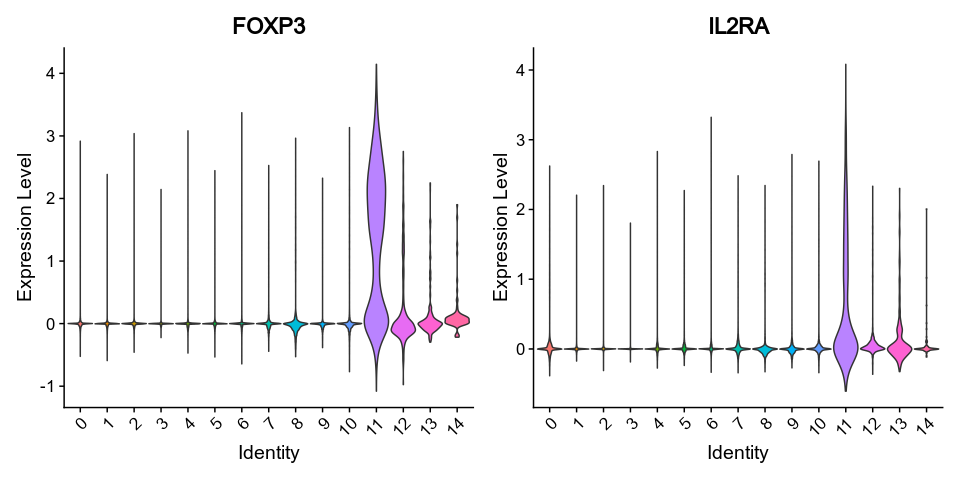
vlnplots_1 = { features = ["FOXP3", "IL2RA"], pt-size = 0, kind = "vln" }
|
|
428
440
|
```
|
|
429
441
|
|
|
430
|
-
{: width="80%" }
|
|
431
|
-
{: width="80%" }
|
|
442
|
+
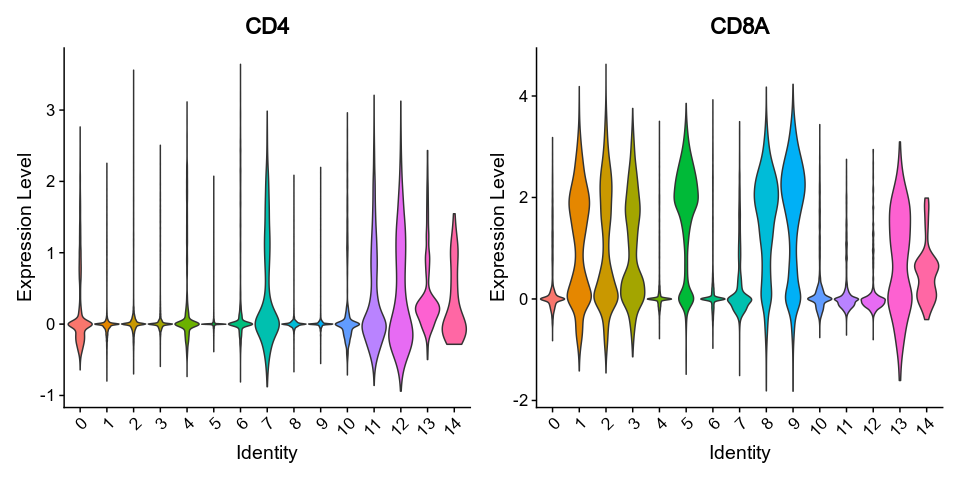{: width="80%" }
|
|
443
|
+
{: width="80%" }
|
|
432
444
|
|
|
433
445
|
### Dimension reduction plot with labels
|
|
434
446
|
|
|
@@ -439,7 +451,7 @@ class SeuratClusterStats(Proc):
|
|
|
439
451
|
repel = true
|
|
440
452
|
```
|
|
441
453
|
|
|
442
|
-
{: width="80%" }
|
|
454
|
+
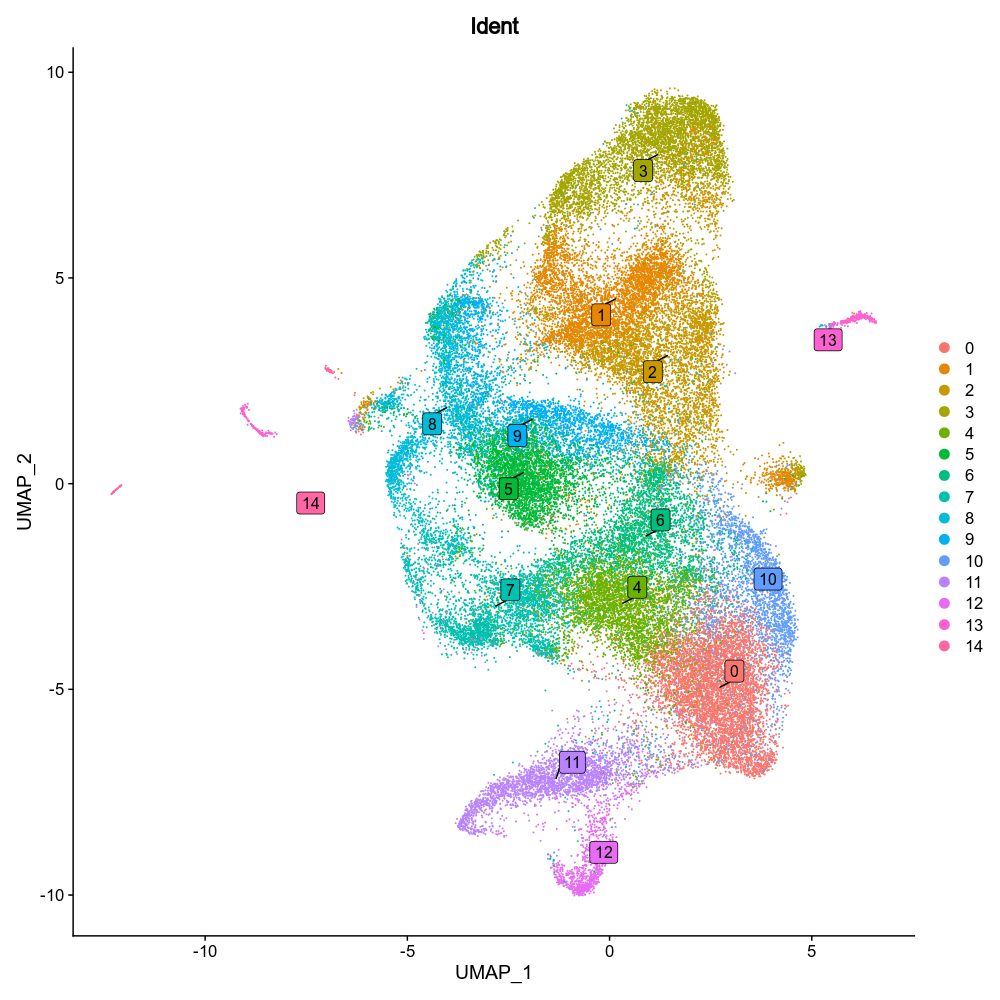{: width="80%" }
|
|
443
455
|
|
|
444
456
|
Input:
|
|
445
457
|
srtobj: The seurat object loaded by `SeuratClustering`
|
|
@@ -849,7 +861,7 @@ class CellsDistribution(Proc):
|
|
|
849
861
|
group_order = [ "Tumor", "Normal" ]
|
|
850
862
|
```
|
|
851
863
|
|
|
852
|
-

|
|
864
|
+
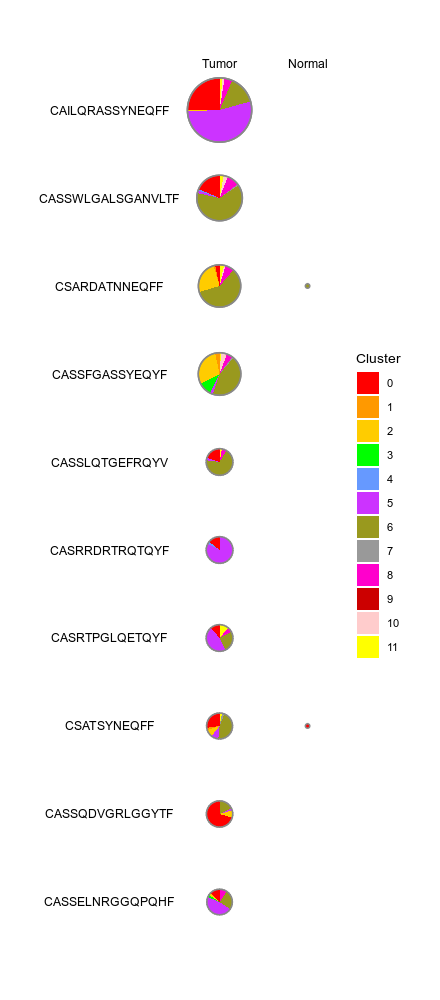
|
|
853
865
|
|
|
854
866
|
Input:
|
|
855
867
|
srtobj: The seurat object in RDS format
|
|
@@ -1229,7 +1241,7 @@ class TopExpressingGenes(Proc):
|
|
|
1229
1241
|
}
|
|
1230
1242
|
|
|
1231
1243
|
|
|
1232
|
-
class
|
|
1244
|
+
class ExprImputation(Proc):
|
|
1233
1245
|
"""This process imputes the dropout values in scRNA-seq data.
|
|
1234
1246
|
|
|
1235
1247
|
It takes the Seurat object as input and outputs the Seurat object with
|
|
@@ -1305,13 +1317,13 @@ class ExprImpution(Proc):
|
|
|
1305
1317
|
},
|
|
1306
1318
|
"alra_args": {},
|
|
1307
1319
|
}
|
|
1308
|
-
script = "file://../scripts/scrna/
|
|
1320
|
+
script = "file://../scripts/scrna/ExprImputation.R"
|
|
1309
1321
|
|
|
1310
1322
|
|
|
1311
1323
|
class SCImpute(Proc):
|
|
1312
1324
|
"""Impute the dropout values in scRNA-seq data.
|
|
1313
1325
|
|
|
1314
|
-
Deprecated. Use `
|
|
1326
|
+
Deprecated. Use `ExprImputation` instead.
|
|
1315
1327
|
|
|
1316
1328
|
Input:
|
|
1317
1329
|
infile: The input file for imputation
|
|
@@ -1475,14 +1487,17 @@ class SeuratTo10X(Proc):
|
|
|
1475
1487
|
srtobj: The seurat object in RDS
|
|
1476
1488
|
|
|
1477
1489
|
Output:
|
|
1478
|
-
outdir: The output directory
|
|
1490
|
+
outdir: The output directory.
|
|
1491
|
+
When `envs.split_by` is specified, the subdirectories will be
|
|
1492
|
+
created for each distinct value of the column.
|
|
1493
|
+
Otherwise, the matrices will be written to the output directory.
|
|
1479
1494
|
|
|
1480
1495
|
Envs:
|
|
1481
1496
|
version: The version of 10X format
|
|
1482
1497
|
"""
|
|
1483
1498
|
input = "srtobj:file"
|
|
1484
1499
|
output = "outdir:dir:{{in.srtobj | stem}}"
|
|
1485
|
-
envs = {"version": "3"}
|
|
1500
|
+
envs = {"version": "3", "split_by": None}
|
|
1486
1501
|
lang = config.lang.rscript
|
|
1487
1502
|
script = "file://../scripts/scrna/SeuratTo10X.R"
|
|
1488
1503
|
|
|
@@ -1754,13 +1769,18 @@ class SeuratMap2Ref(Proc):
|
|
|
1754
1769
|
sobjfile: The seurat object
|
|
1755
1770
|
|
|
1756
1771
|
Output:
|
|
1757
|
-
outfile: The rds file of seurat object with cell type annotated
|
|
1772
|
+
outfile: The rds file of seurat object with cell type annotated.
|
|
1773
|
+
Note that the reduction name will be `ref.umap` for the mapping.
|
|
1774
|
+
To visualize the mapping, you should use `ref.umap` as the reduction name.
|
|
1758
1775
|
|
|
1759
1776
|
Envs:
|
|
1760
1777
|
ncores (type=int;order=-100): Number of cores to use.
|
|
1761
|
-
|
|
1778
|
+
When `split_by` is used, this will be the number of cores for each object to map to the reference.
|
|
1779
|
+
When `split_by` is not used, this is used in `future::plan(strategy = "multicore", workers = <ncores>)`
|
|
1762
1780
|
to parallelize some Seurat procedures.
|
|
1763
|
-
See also: <https://satijalab.org/seurat/
|
|
1781
|
+
See also: <https://satijalab.org/seurat/archive/v3.0/future_vignette.html>
|
|
1782
|
+
mutaters (type=json): The mutaters to mutate the metadata.
|
|
1783
|
+
This is helpful when we want to create new columns for `split_by`.
|
|
1764
1784
|
use: A column name of metadata from the reference
|
|
1765
1785
|
(e.g. `celltype.l1`, `celltype.l2`) to transfer to the query as the
|
|
1766
1786
|
cell types (ident) for downstream analysis. This field is required.
|
|
@@ -1772,16 +1792,29 @@ class SeuratMap2Ref(Proc):
|
|
|
1772
1792
|
`Seurat::LoadH5Seurat()`.
|
|
1773
1793
|
The file type is determined by the extension. `.rds` or `.RDS` for
|
|
1774
1794
|
RDS file, `.h5seurat` or `.h5` for h5seurat file.
|
|
1795
|
+
refnorm (choice): Normalization method the reference used. The same method will be used for the query.
|
|
1796
|
+
- NormalizeData: Using [`NormalizeData`](https://satijalab.org/seurat/reference/normalizedata).
|
|
1797
|
+
- SCTransform: Using [`SCTransform`](https://satijalab.org/seurat/reference/sctransform).
|
|
1798
|
+
- auto: Automatically detect the normalization method.
|
|
1799
|
+
If the default assay of reference is `SCT`, then `SCTransform` will be used.
|
|
1800
|
+
split_by: The column name in metadata to split the query into multiple objects.
|
|
1801
|
+
This helps when the original query is too large to process.
|
|
1775
1802
|
SCTransform (ns): Arguments for [`SCTransform()`](https://satijalab.org/seurat/reference/sctransform)
|
|
1776
1803
|
- do-correct-umi (flag): Place corrected UMI matrix in assay counts layer?
|
|
1777
1804
|
- do-scale (flag): Whether to scale residuals to have unit variance?
|
|
1778
1805
|
- do-center (flag): Whether to center residuals to have mean zero?
|
|
1779
1806
|
- <more>: See <https://satijalab.org/seurat/reference/sctransform>.
|
|
1780
1807
|
Note that the hyphen (`-`) will be transformed into `.` for the keys.
|
|
1808
|
+
NormalizeData (ns): Arguments for [`NormalizeData()`](https://satijalab.org/seurat/reference/normalizedata)
|
|
1809
|
+
- normalization-method: Normalization method.
|
|
1810
|
+
- <more>: See <https://satijalab.org/seurat/reference/normalizedata>.
|
|
1811
|
+
Note that the hyphen (`-`) will be transformed into `.` for the keys.
|
|
1781
1812
|
FindTransferAnchors (ns): Arguments for [`FindTransferAnchors()`](https://satijalab.org/seurat/reference/findtransferanchors)
|
|
1782
1813
|
- normalization-method (choice): Name of normalization method used.
|
|
1783
1814
|
- LogNormalize: Log-normalize the data matrix
|
|
1784
1815
|
- SCT: Scale data using the SCTransform method
|
|
1816
|
+
- auto: Automatically detect the normalization method.
|
|
1817
|
+
See `envs.refnorm`.
|
|
1785
1818
|
- reference-reduction: Name of dimensional reduction to use from the reference if running the pcaproject workflow.
|
|
1786
1819
|
Optionally enables reuse of precomputed reference dimensional reduction.
|
|
1787
1820
|
- <more>: See <https://satijalab.org/seurat/reference/findtransferanchors>.
|
|
@@ -1807,14 +1840,19 @@ class SeuratMap2Ref(Proc):
|
|
|
1807
1840
|
"ncores": config.misc.ncores,
|
|
1808
1841
|
"use": None,
|
|
1809
1842
|
"ident": "seurat_clusters",
|
|
1843
|
+
"mutaters": {},
|
|
1810
1844
|
"ref": None,
|
|
1845
|
+
"refnorm": "auto",
|
|
1846
|
+
"split_by": None,
|
|
1811
1847
|
"SCTransform": {
|
|
1812
1848
|
"do-correct-umi": False,
|
|
1813
1849
|
"do-scale": False,
|
|
1814
1850
|
"do-center": True,
|
|
1815
1851
|
},
|
|
1852
|
+
"NormalizeData": {
|
|
1853
|
+
"normalization-method": "LogNormalize",
|
|
1854
|
+
},
|
|
1816
1855
|
"FindTransferAnchors": {
|
|
1817
|
-
"normalization-method": "SCT",
|
|
1818
1856
|
"reference-reduction": "spca",
|
|
1819
1857
|
},
|
|
1820
1858
|
"MapQuery": {
|
|
@@ -1862,7 +1900,7 @@ class RadarPlots(Proc):
|
|
|
1862
1900
|
|
|
1863
1901
|
Then we will have a radar plots like this:
|
|
1864
1902
|
|
|
1865
|
-

|
|
1903
|
+
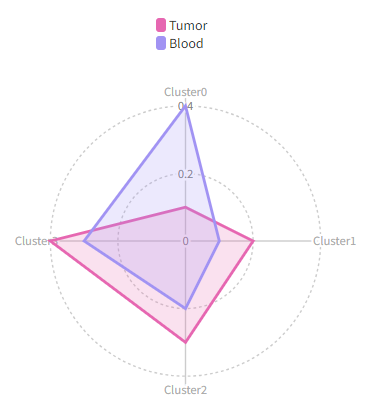
|
|
1866
1904
|
|
|
1867
1905
|
We can use `each` to separate the cells into different cases:
|
|
1868
1906
|
|
|
@@ -1874,7 +1912,7 @@ class RadarPlots(Proc):
|
|
|
1874
1912
|
|
|
1875
1913
|
Then we will have two radar plots, one for `Pre` and one for `Post`:
|
|
1876
1914
|
|
|
1877
|
-

|
|
1915
|
+
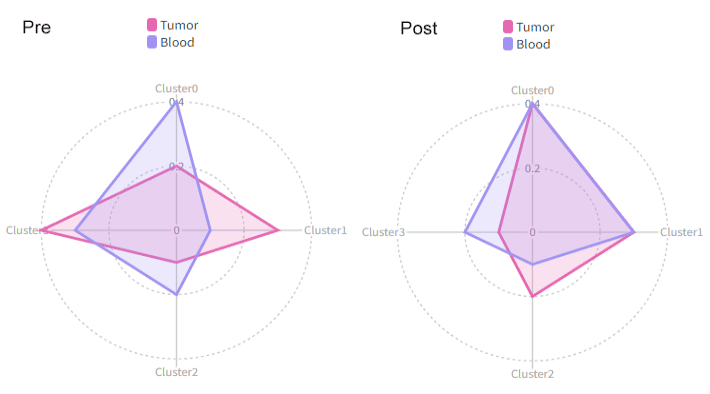
|
|
1878
1916
|
|
|
1879
1917
|
Using `cluster_order` to change the order of the clusters and show only the first 3 clusters:
|
|
1880
1918
|
|
|
@@ -1885,7 +1923,7 @@ class RadarPlots(Proc):
|
|
|
1885
1923
|
breaks = [0, 50, 100] # also change the breaks
|
|
1886
1924
|
```
|
|
1887
1925
|
|
|
1888
|
-

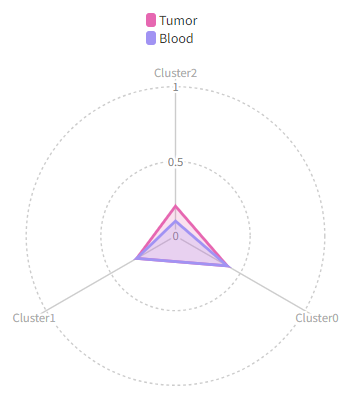
|
|
1926
|
+
|
|
1889
1927
|
|
|
1890
1928
|
|
|
1891
1929
|
/// Attention
|
|
@@ -22,11 +22,11 @@ class MetabolicPathwayActivity(Proc):
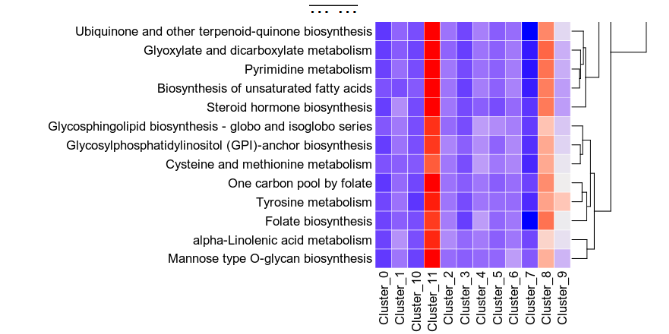
|
|
|
22
22
|
For each subset, a heatmap and a violin plot will be generated.
|
|
23
23
|
The heatmap shows the pathway activities for each group and each metabolic pathway
|
|
24
24
|
|
|
25
|
-
{: width="80%"}
|
|
25
|
+
{: width="80%"}
|
|
26
26
|
|
|
27
27
|
The violin plot shows the distribution of the pathway activities for each group
|
|
28
28
|
|
|
29
|
-
{: width="45%"}
|
|
29
|
+
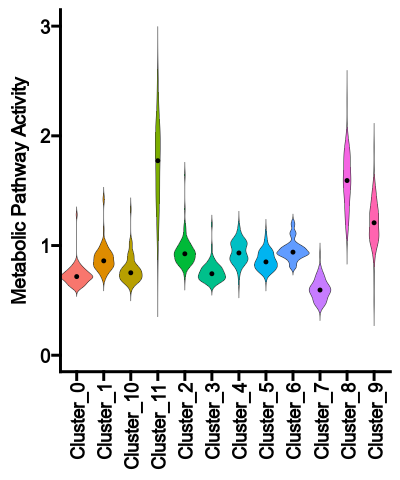{: width="45%"}
|
|
30
30
|
|
|
31
31
|
Envs:
|
|
32
32
|
ntimes (type=int): Number of times to do the permutation
|
|
@@ -294,7 +294,7 @@ class MetabolicPathwayHeterogeneity(Proc):
|
|
|
294
294
|
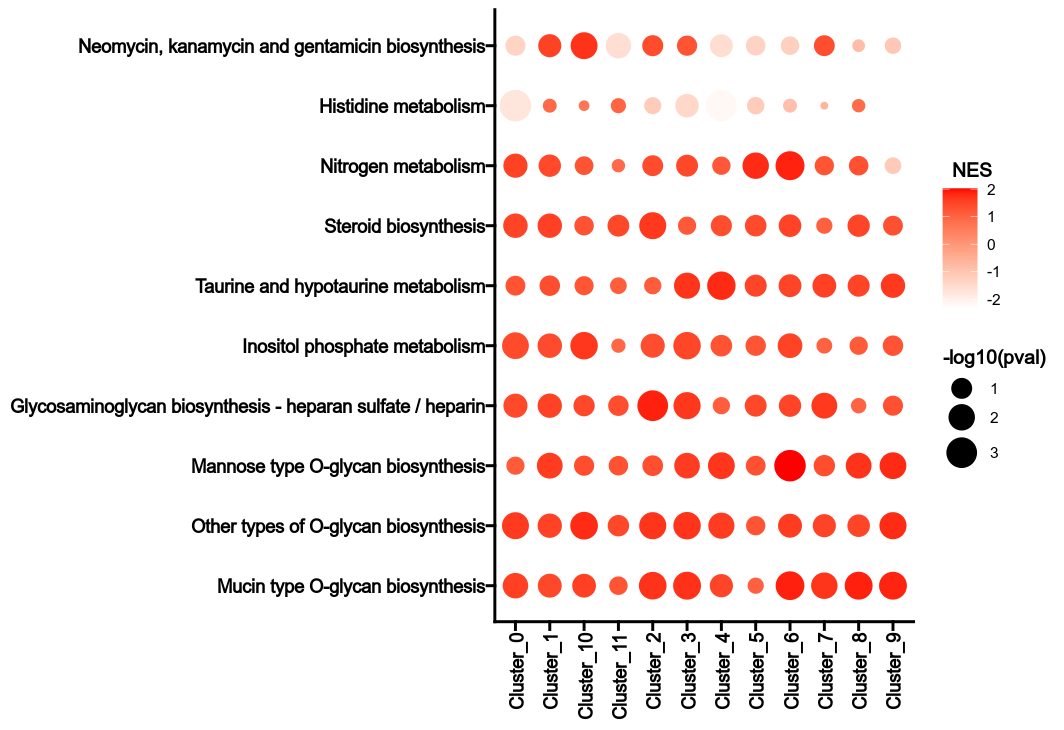
The heterogeneity can be reflected by the NES values and the p-values in
|
|
295
295
|
different groups for the metabolic pathways.
|
|
296
296
|
|
|
297
|
-

|
|
297
|
+
|
|
298
298
|
|
|
299
299
|
|
|
300
300
|
Envs:
|
|
@@ -566,8 +566,8 @@ class ScrnaMetabolicLandscape(ProcGroup):
|
|
|
566
566
|
input_data = lambda ch: tibble(
|
|
567
567
|
srtobj=ch.iloc[:, 0],
|
|
568
568
|
metafile=[None],
|
|
569
|
-
mutaters=[self.opts.mutaters],
|
|
570
569
|
)
|
|
570
|
+
envs = {"mutaters": self.opts.mutaters}
|
|
571
571
|
|
|
572
572
|
return MetabolicSeuratMetadataMutater
|
|
573
573
|
|
|
@@ -577,10 +577,10 @@ class ScrnaMetabolicLandscape(ProcGroup):
|
|
|
577
577
|
if self.opts.noimpute:
|
|
578
578
|
return self.p_mutater
|
|
579
579
|
|
|
580
|
-
from .scrna import
|
|
580
|
+
from .scrna import ExprImputation
|
|
581
581
|
|
|
582
582
|
@annotate.format_doc(indent=3)
|
|
583
|
-
class
|
|
583
|
+
class MetabolicExprImputation(ExprImputation):
|
|
584
584
|
"""{{Summary}}
|
|
585
585
|
|
|
586
586
|
You can turn off the imputation by setting the `noimpute` option
|
|
@@ -588,7 +588,7 @@ class ScrnaMetabolicLandscape(ProcGroup):
|
|
|
588
588
|
"""
|
|
589
589
|
requires = self.p_mutater
|
|
590
590
|
|
|
591
|
-
return
|
|
591
|
+
return MetabolicExprImputation
|
|
592
592
|
|
|
593
593
|
@ProcGroup.add_proc
|
|
594
594
|
def p_pathway_activity(self) -> Type[Proc]:
|
|
@@ -71,3 +71,68 @@ class PlinkSimulation(Proc):
|
|
|
71
71
|
"sample_prefix": None,
|
|
72
72
|
}
|
|
73
73
|
script = "file://../scripts/snp/PlinkSimulation.py"
|
|
74
|
+
|
|
75
|
+
|
|
76
|
+
class MatrixEQTL(Proc):
|
|
77
|
+
"""Run Matrix eQTL
|
|
78
|
+
|
|
79
|
+
See also <https://www.bios.unc.edu/research/genomic_software/Matrix_eQTL/>
|
|
80
|
+
|
|
81
|
+
Input:
|
|
82
|
+
geno: Genotype matrix file with rows representing SNPs and columns
|
|
83
|
+
representing samples.
|
|
84
|
+
expr: Expression matrix file with rows representing genes and columns
|
|
85
|
+
representing samples.
|
|
86
|
+
cov: Covariate matrix file with rows representing covariates and columns
|
|
87
|
+
representing samples.
|
|
88
|
+
|
|
89
|
+
Output:
|
|
90
|
+
alleqtls: Matrix eQTL output file
|
|
91
|
+
cisqtls: The cis-eQTL file if `snppos` and `genepos` are provided.
|
|
92
|
+
Otherwise it'll be empty.
|
|
93
|
+
|
|
94
|
+
Envs:
|
|
95
|
+
model (choice): The model to use.
|
|
96
|
+
- `linear`: Linear model
|
|
97
|
+
- `modelLINEAR`: Same as `linear`
|
|
98
|
+
- `anova`: ANOVA model
|
|
99
|
+
- `modelANOVA`: Same as `anova`
|
|
100
|
+
pval (type=float): P-value threshold for eQTLs
|
|
101
|
+
transp (type=float): P-value threshold for trans-eQTLs.
|
|
102
|
+
If cis-eQTLs are not enabled (`snppos` and `genepos` are not set),
|
|
103
|
+
this defaults to 1e-5.
|
|
104
|
+
If cis-eQTLs are enabled, this defaults to `None`, which will disable
|
|
105
|
+
trans-eQTL analysis.
|
|
106
|
+
fdr (flag): Do FDR calculation or not (save memory if not).
|
|
107
|
+
snppos: The path of the SNP position file.
|
|
108
|
+
It could be a BED, GFF, VCF or a tab-delimited file with
|
|
109
|
+
`snp`, `chr`, `pos` as the first 3 columns.
|
|
110
|
+
genepos: The path of the gene position file.
|
|
111
|
+
It could be a BED or GFF file.
|
|
112
|
+
dist (type=int): Distance threshold for cis-eQTLs.
|
|
113
|
+
transpose_geno (flag): If set, the genotype matrix (`in.geno`)
|
|
114
|
+
will be transposed.
|
|
115
|
+
transpose_expr (flag): If set, the expression matrix (`in.expr`)
|
|
116
|
+
will be transposed.
|
|
117
|
+
transpose_cov (flag): If set, the covariate matrix (`in.cov`)
|
|
118
|
+
will be transposed.
|
|
119
|
+
"""
|
|
120
|
+
input = "geno:file, expr:file, cov:file"
|
|
121
|
+
output = [
|
|
122
|
+
"alleqtls:file:{{in.geno | stem}}.alleqtls.txt",
|
|
123
|
+
"cisqtls:file:{{in.geno | stem}}.cisqtls.txt",
|
|
124
|
+
]
|
|
125
|
+
lang = config.lang.rscript
|
|
126
|
+
envs = {
|
|
127
|
+
"model": "linear",
|
|
128
|
+
"pval": 1e-3,
|
|
129
|
+
"transp": None,
|
|
130
|
+
"fdr": False,
|
|
131
|
+
"snppos": None,
|
|
132
|
+
"genepos": config.ref.refgene,
|
|
133
|
+
"dist": 250000,
|
|
134
|
+
"transpose_geno": False,
|
|
135
|
+
"transpose_expr": False,
|
|
136
|
+
"transpose_cov": False,
|
|
137
|
+
}
|
|
138
|
+
script = "file://../scripts/snp/MatrixEQTL.R"
|
|
@@ -923,7 +923,7 @@ class CloneResidency(Proc):
|
|
|
923
923
|
|
|
924
924
|
- Residency plots showing the residency of clones in the two groups
|
|
925
925
|
|
|
926
|
-

|
|
926
|
+
|
|
927
927
|
|
|
928
928
|
The points in the plot are jittered to avoid overplotting. The x-axis is the residency in the first group and
|
|
929
929
|
the y-axis is the residency in the second group. The size of the points are relative to the normalized size of
|
|
@@ -943,7 +943,7 @@ class CloneResidency(Proc):
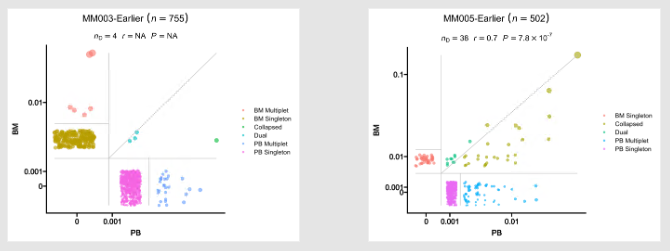
|
|
|
943
943
|
|
|
944
944
|
- Venn diagrams showing the overlap of the clones in the two groups
|
|
945
945
|
|
|
946
|
-
{: width="60%"}
|
|
946
|
+
{: width="60%"}
|
|
947
947
|
|
|
948
948
|
Input:
|
|
949
949
|
immdata: The data loaded by `immunarch::repLoad()`
|
|
@@ -1259,7 +1259,7 @@ class TCRClusterStats(Proc):
|
|
|
1259
1259
|
by = "Sample"
|
|
1260
1260
|
```
|
|
1261
1261
|
|
|
1262
|
-
{: width="80%"}
|
|
1262
|
+
{: width="80%"}
|
|
1263
1263
|
|
|
1264
1264
|
### Shared clusters
|
|
1265
1265
|
|
|
@@ -1269,7 +1269,7 @@ class TCRClusterStats(Proc):
|
|
|
1269
1269
|
heatmap_meta = ["region"]
|
|
1270
1270
|
```
|
|
1271
1271
|
|
|
1272
|
-
{: width="80%"}
|
|
1272
|
+
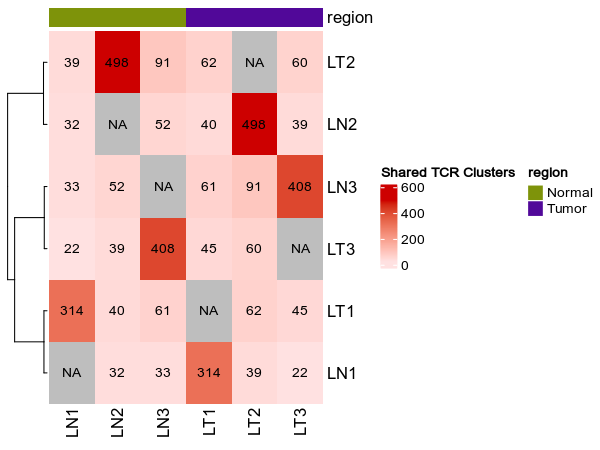{: width="80%"}
|
|
1273
1273
|
|
|
1274
1274
|
### Sample diversity
|
|
1275
1275
|
|
|
@@ -1278,11 +1278,11 @@ class TCRClusterStats(Proc):
|
|
|
1278
1278
|
method = "gini"
|
|
1279
1279
|
```
|
|
1280
1280
|
|
|
1281
|
-
{: width="80%"}
|
|
1281
|
+
{: width="80%"}
|
|
1282
1282
|
|
|
1283
1283
|
Compared to the sample diversity using TCR clones:
|
|
1284
1284
|
|
|
1285
|
-
{: width="80%"}
|
|
1285
|
+
{: width="80%"}
|
|
1286
1286
|
|
|
1287
1287
|
Input:
|
|
1288
1288
|
immfile: The immunarch object with TCR clusters attached
|
|
@@ -113,14 +113,14 @@ for (name in names(stats)) {
|
|
|
113
113
|
if (stat$plot == "boxplot" || stat$plot == "box") {
|
|
114
114
|
p <- ggplot(data, aes(x=!!group, y=!!sym(stat$on), fill=!!group)) +
|
|
115
115
|
geom_boxplot(position = "dodge") +
|
|
116
|
-
scale_fill_biopipen() +
|
|
116
|
+
scale_fill_biopipen(alpha = .6) +
|
|
117
117
|
xlab("")
|
|
118
118
|
} else if (stat$plot == "violin" ||
|
|
119
119
|
stat$plot == "violinplot" ||
|
|
120
120
|
stat$plot == "vlnplot") {
|
|
121
121
|
p <- ggplot(data, aes(x = !!group, y = !!sym(stat$on), fill=!!group)) +
|
|
122
122
|
geom_violin(position = "dodge") +
|
|
123
|
-
scale_fill_biopipen() +
|
|
123
|
+
scale_fill_biopipen(alpha = .6) +
|
|
124
124
|
xlab("")
|
|
125
125
|
} else if (
|
|
126
126
|
(grepl("violin", stat$plot) || grepl("vln", stat$plot)) &&
|
|
@@ -129,12 +129,12 @@ for (name in names(stats)) {
|
|
|
129
129
|
p <- ggplot(data, aes(x = !!group, y = !!sym(stat$on), fill = !!group)) +
|
|
130
130
|
geom_violin(position = "dodge") +
|
|
131
131
|
geom_boxplot(width = 0.1, position = position_dodge(0.9), fill="white") +
|
|
132
|
-
scale_fill_biopipen() +
|
|
132
|
+
scale_fill_biopipen(alpha = .6) +
|
|
133
133
|
xlab("")
|
|
134
134
|
} else if (stat$plot == "histogram" || stat$plot == "hist") {
|
|
135
135
|
p <- ggplot(data, aes(x = !!sym(stat$on), fill = !!group)) +
|
|
136
136
|
geom_histogram(bins = 10, position = "dodge", alpha = 0.8, color = "white") +
|
|
137
|
-
scale_fill_biopipen()
|
|
137
|
+
scale_fill_biopipen(alpha = .6)
|
|
138
138
|
} else if (stat$plot == "pie" || stat$plot == "piechart") {
|
|
139
139
|
if (is.null(stat$each)) {
|
|
140
140
|
data <- data %>% distinct(!!group, .keep_all = TRUE)
|
|
@@ -157,7 +157,7 @@ for (name in names(stats)) {
|
|
|
157
157
|
fill="#EEEEEE",
|
|
158
158
|
size=4
|
|
159
159
|
) +
|
|
160
|
-
scale_fill_biopipen(name = group) +
|
|
160
|
+
scale_fill_biopipen(alpha = .6, name = group) +
|
|
161
161
|
ggtitle(paste0("# ", stat$on))
|
|
162
162
|
} else if (stat$plot == "bar" || stat$plot == "barplot") {
|
|
163
163
|
if (is.null(stat$each)) {
|
|
@@ -169,7 +169,7 @@ for (name in names(stats)) {
|
|
|
169
169
|
data,
|
|
170
170
|
aes(x = !!group, y = !!sym(count_on), fill = !!group)) +
|
|
171
171
|
geom_bar(stat = "identity") +
|
|
172
|
-
scale_fill_biopipen() +
|
|
172
|
+
scale_fill_biopipen(alpha = .6) +
|
|
173
173
|
ylab(paste0("# ", stat$on))
|
|
174
174
|
} else {
|
|
175
175
|
stop("Unknown plot type: ", stat$plot)
|