active-vision 0.0.5__tar.gz → 0.1.1__tar.gz
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- {active_vision-0.0.5 → active_vision-0.1.1}/PKG-INFO +60 -72
- {active_vision-0.0.5 → active_vision-0.1.1}/README.md +56 -71
- {active_vision-0.0.5 → active_vision-0.1.1}/pyproject.toml +4 -1
- active_vision-0.1.1/src/active_vision/__init__.py +3 -0
- active_vision-0.1.1/src/active_vision/core.py +626 -0
- {active_vision-0.0.5 → active_vision-0.1.1}/src/active_vision.egg-info/PKG-INFO +60 -72
- {active_vision-0.0.5 → active_vision-0.1.1}/src/active_vision.egg-info/requires.txt +3 -0
- active_vision-0.0.5/src/active_vision/__init__.py +0 -3
- active_vision-0.0.5/src/active_vision/core.py +0 -352
- {active_vision-0.0.5 → active_vision-0.1.1}/LICENSE +0 -0
- {active_vision-0.0.5 → active_vision-0.1.1}/setup.cfg +0 -0
- {active_vision-0.0.5 → active_vision-0.1.1}/src/active_vision.egg-info/SOURCES.txt +0 -0
- {active_vision-0.0.5 → active_vision-0.1.1}/src/active_vision.egg-info/dependency_links.txt +0 -0
- {active_vision-0.0.5 → active_vision-0.1.1}/src/active_vision.egg-info/top_level.txt +0 -0
|
@@ -1,10 +1,11 @@
|
|
|
1
1
|
Metadata-Version: 2.2
|
|
2
2
|
Name: active-vision
|
|
3
|
-
Version: 0.
|
|
3
|
+
Version: 0.1.1
|
|
4
4
|
Summary: Active learning for edge vision.
|
|
5
5
|
Requires-Python: >=3.10
|
|
6
6
|
Description-Content-Type: text/markdown
|
|
7
7
|
License-File: LICENSE
|
|
8
|
+
Requires-Dist: accelerate>=1.2.1
|
|
8
9
|
Requires-Dist: datasets>=3.2.0
|
|
9
10
|
Requires-Dist: fastai>=2.7.18
|
|
10
11
|
Requires-Dist: gradio>=5.12.0
|
|
@@ -13,6 +14,8 @@ Requires-Dist: ipywidgets>=8.1.5
|
|
|
13
14
|
Requires-Dist: loguru>=0.7.3
|
|
14
15
|
Requires-Dist: seaborn>=0.13.2
|
|
15
16
|
Requires-Dist: timm>=1.0.13
|
|
17
|
+
Requires-Dist: transformers>=4.48.0
|
|
18
|
+
Requires-Dist: xinfer>=0.3.2
|
|
16
19
|
|
|
17
20
|

|
|
18
21
|

|
|
@@ -68,17 +71,18 @@ cd active-vision
|
|
|
68
71
|
pip install -e .
|
|
69
72
|
```
|
|
70
73
|
|
|
71
|
-
I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
72
|
-
|
|
73
|
-
If you're using uv:
|
|
74
|
-
|
|
75
|
-
```bash
|
|
76
|
-
uv venv
|
|
77
|
-
uv sync
|
|
78
|
-
```
|
|
79
|
-
Once the virtual environment is created, you can install the package using pip.
|
|
80
74
|
|
|
81
75
|
> [!TIP]
|
|
76
|
+
> I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
77
|
+
>
|
|
78
|
+
> If you're using uv:
|
|
79
|
+
>
|
|
80
|
+
> ```bash
|
|
81
|
+
> uv venv
|
|
82
|
+
> uv sync
|
|
83
|
+
> ```
|
|
84
|
+
> Once the virtual environment is created, you can install the package using pip.
|
|
85
|
+
>
|
|
82
86
|
> If you're using uv add a `uv` before the pip install command to install into your virtual environment. Eg:
|
|
83
87
|
> ```bash
|
|
84
88
|
> uv pip install active-vision
|
|
@@ -117,12 +121,16 @@ pred_df = al.predict(filepaths)
|
|
|
117
121
|
# Sample low confidence predictions from unlabeled set
|
|
118
122
|
uncertain_df = al.sample_uncertain(pred_df, num_samples=10)
|
|
119
123
|
|
|
120
|
-
# Launch a Gradio UI to label the low confidence samples
|
|
124
|
+
# Launch a Gradio UI to label the low confidence samples, save the labeled samples to a file
|
|
121
125
|
al.label(uncertain_df, output_filename="uncertain")
|
|
122
126
|
```
|
|
123
127
|
|
|
124
128
|
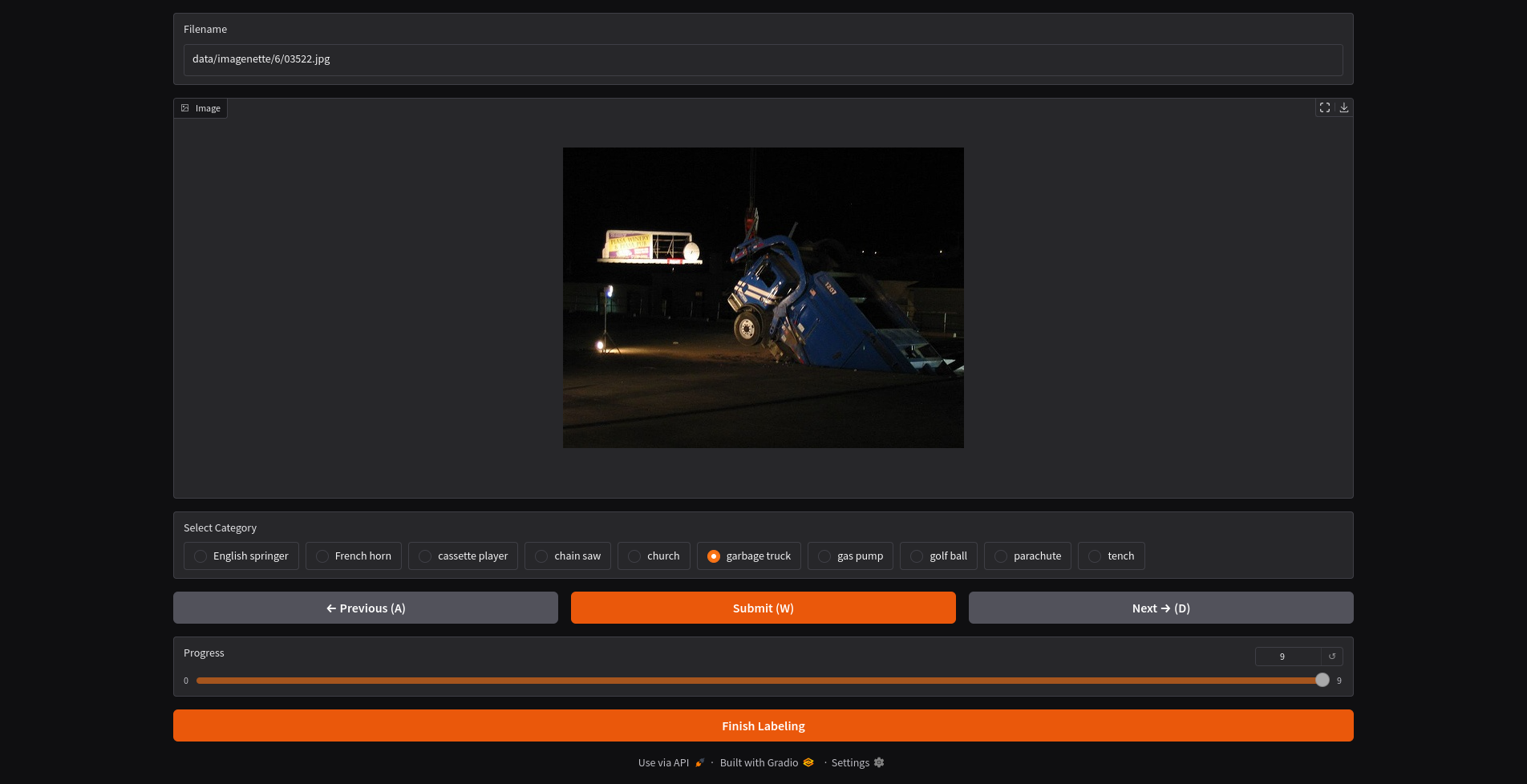
|
|
125
129
|
|
|
130
|
+
In the UI, you can optionally run zero-shot inference on the image. This will use a VLM to predict the label of the image. There are a dozen VLM models as supported in the [x.infer project](https://github.com/dnth/x.infer).
|
|
131
|
+
|
|
132
|
+

|
|
133
|
+
|
|
126
134
|
Once complete, the labeled samples will be save into a new df.
|
|
127
135
|
We can now add the newly labeled data to the training set.
|
|
128
136
|
|
|
@@ -167,12 +175,12 @@ The active learning loop is a iterative process and can keep going until you hit
|
|
|
167
175
|
For this dataset,I decided to stop the active learning loop at 275 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard.
|
|
168
176
|
|
|
169
177
|
|
|
170
|
-
| #Labeled Images
|
|
171
|
-
|
|
172
|
-
| 9469
|
|
173
|
-
| 9469
|
|
174
|
-
| 275
|
|
175
|
-
| 275
|
|
178
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
179
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------- |
|
|
180
|
+
| 9469 | 94.90% | 80 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
181
|
+
| 9469 | 95.11% | 200 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
182
|
+
| 275 | 99.33% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/05_retrain_larger.ipynb) |
|
|
183
|
+
| 275 | 93.40% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/04_relabel_loop.ipynb) |
|
|
176
184
|
|
|
177
185
|
### Dog Food
|
|
178
186
|
- num classes: 2
|
|
@@ -182,11 +190,11 @@ To start the active learning loop, I labeled 20 images (10 images from each clas
|
|
|
182
190
|
|
|
183
191
|
I decided to stop the active learning loop at 160 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
184
192
|
|
|
185
|
-
| #Labeled Images
|
|
186
|
-
|
|
187
|
-
| 2100
|
|
188
|
-
| 160
|
|
189
|
-
| 160
|
|
193
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
194
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |--------------------------------------------------------------------------------------------- |
|
|
195
|
+
| 2100 | 99.70% | ? | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/abhishek/autotrain-dog-vs-food) |
|
|
196
|
+
| 160 | 100.00% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/02_train.ipynb) |
|
|
197
|
+
| 160 | 97.60% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/01_label.ipynb) |
|
|
190
198
|
|
|
191
199
|
### Oxford-IIIT Pet
|
|
192
200
|
- num classes: 37
|
|
@@ -196,13 +204,27 @@ To start the active learning loop, I labeled 370 images (10 images from each cla
|
|
|
196
204
|
|
|
197
205
|
I decided to stop the active learning loop at 612 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
198
206
|
|
|
199
|
-
| #Labeled Images
|
|
200
|
-
|
|
201
|
-
| 3680
|
|
202
|
-
| 612
|
|
203
|
-
| 612
|
|
207
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
208
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------------------- |
|
|
209
|
+
| 3680 | 95.40% | 5 | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/walterg777/vit-base-oxford-iiit-pets) |
|
|
210
|
+
| 612 | 90.26% | 11 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/02_train.ipynb) |
|
|
211
|
+
| 612 | 91.38% | 11 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/03_train_vit.ipynb) |
|
|
212
|
+
|
|
213
|
+
### Eurosat RGB
|
|
214
|
+
- num classes: 10
|
|
215
|
+
- num images: 16100
|
|
216
|
+
|
|
217
|
+
To start the active learning loop, I labeled 100 images (10 images from each class) and iteratively labeled the most informative images until I hit 1188 labeled images.
|
|
218
|
+
|
|
219
|
+
I decided to stop the active learning loop at 1188 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
204
220
|
|
|
205
221
|
|
|
222
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
223
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |-------------------------------------------------------------------------------------------- |
|
|
224
|
+
| 16100 | 98.55% | 6 | vit-base-patch16-224 | ❌ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/03_train_all.ipynb) |
|
|
225
|
+
| 1188 | 94.59% | 6 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
226
|
+
| 1188 | 96.57% | 13 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
227
|
+
|
|
206
228
|
|
|
207
229
|
## ➿ Workflow
|
|
208
230
|
This section describes a more detailed workflow for active learning. There are two workflows for active learning that we can use depending on the availability of labeled data.
|
|
@@ -270,55 +292,21 @@ graph TD
|
|
|
270
292
|
|
|
271
293
|
|
|
272
294
|
|
|
273
|
-
|
|
274
|
-
To test out the workflows we will use the [imagenette dataset](https://huggingface.co/datasets/frgfm/imagenette). But this will be applicable to any dataset.
|
|
275
|
-
|
|
276
|
-
Imagenette is a subset of the ImageNet dataset with 10 classes. We will use this dataset to test out the workflows. Additionally, Imagenette has an existing leaderboard which we can use to evaluate the performance of the models.
|
|
277
|
-
|
|
278
|
-
### Step 1: Download the dataset
|
|
279
|
-
Download the imagenette dataset. The imagenette dataset has a train and validation split. Since the leaderboard is based on the validation set, we will evalutate the performance of our model on the validation set to make it easier to compare to the leaderboard.
|
|
280
|
-
|
|
281
|
-
We will treat the imagenette train set as a unlabeled set and iteratively sample from it while monitoring the performance on the validation set. Ideally we will be able to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
295
|
+
## 🧱 Sampling Approaches
|
|
282
296
|
|
|
283
|
-
|
|
297
|
+
Recommendation 1:
|
|
298
|
+
- 10% randomly selected from unlabeled items.
|
|
299
|
+
- 80% selected from the lowest confidence items.
|
|
300
|
+
- 10% selected as outliers.
|
|
284
301
|
|
|
285
|
-
|
|
286
|
-
```python
|
|
287
|
-
from datasets import load_dataset
|
|
288
|
-
|
|
289
|
-
unlabeled_dataset = load_dataset("dnth/active-learning-imagenette", "unlabeled")
|
|
290
|
-
eval_dataset = load_dataset("dnth/active-learning-imagenette", "evaluation")
|
|
291
|
-
```
|
|
302
|
+
Recommendation 2:
|
|
292
303
|
|
|
293
|
-
|
|
294
|
-
|
|
304
|
+
- Sample 100 predicted images at 10–20% confidence.
|
|
305
|
+
- Sample 100 predicted images at 20–30% confidence.
|
|
306
|
+
- Sample 100 predicted images at 30–40% confidence, and so on.
|
|
295
307
|
|
|
296
|
-
### Step 3: Training the proxy model
|
|
297
|
-
Train a proxy model on the initial dataset. The proxy model will be a small model that is easy to train and deploy. We will use the fastai framework to train the model. We will use the resnet18 architecture as a starting point. Once training is complete, compute the accuracy of the proxy model on the validation set and compare it to the leaderboard.
|
|
298
308
|
|
|
299
|
-
|
|
300
|
-
> With the initial model we got 91.24% accuracy on the validation set. See the [notebook](./nbs/01_initial_sampling.ipynb) for more details.
|
|
301
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
302
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
303
|
-
> | 10 | 100 | 91.24% | Initial sampling [notebook](./nbs/01_initial_sampling.ipynb) |
|
|
304
|
-
> | 80 | 9469 | 94.90% | fastai |
|
|
305
|
-
> | 200 | 9469 | 95.11% | fastai |
|
|
309
|
+
Uncertainty and diversity sampling are most effective when combined. For instance, you could first sample the most uncertain items using an uncertainty sampling method, then apply a diversity sampling method such as clustering to select a diverse set from the uncertain items.
|
|
306
310
|
|
|
311
|
+
Ultimately, the right ratios can depend on the specific task and dataset.
|
|
307
312
|
|
|
308
|
-
|
|
309
|
-
### Step 4: Inference on the unlabeled dataset
|
|
310
|
-
Run inference on the unlabeled dataset (the remaining imagenette train set) and evaluate the performance of the proxy model.
|
|
311
|
-
|
|
312
|
-
### Step 5: Active learning
|
|
313
|
-
Use active learning to select the most informative images to label from the unlabeled set. Pick the top 10 images from the unlabeled set that the proxy model is least confident about and label them.
|
|
314
|
-
|
|
315
|
-
### Step 6: Repeat
|
|
316
|
-
Repeat step 3 - 5 until the performance on the validation set is close to the leaderboard. Note the number of labeled images vs the performance on the validation set. Ideally we want to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
317
|
-
|
|
318
|
-
|
|
319
|
-
After the first iteration we got 94.57% accuracy on the validation set. See the [notebook](./nbs/03_retrain_model.ipynb) for more details.
|
|
320
|
-
|
|
321
|
-
> [!TIP]
|
|
322
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
323
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
324
|
-
> | 10 | 200 | 94.57% | First relabeling [notebook](./nbs/03_retrain_model.ipynb) | -->
|
|
@@ -52,17 +52,18 @@ cd active-vision
|
|
|
52
52
|
pip install -e .
|
|
53
53
|
```
|
|
54
54
|
|
|
55
|
-
I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
56
|
-
|
|
57
|
-
If you're using uv:
|
|
58
|
-
|
|
59
|
-
```bash
|
|
60
|
-
uv venv
|
|
61
|
-
uv sync
|
|
62
|
-
```
|
|
63
|
-
Once the virtual environment is created, you can install the package using pip.
|
|
64
55
|
|
|
65
56
|
> [!TIP]
|
|
57
|
+
> I recommend using [uv](https://docs.astral.sh/uv/) to set up a virtual environment and install the package. You can also use other virtual env of your choice.
|
|
58
|
+
>
|
|
59
|
+
> If you're using uv:
|
|
60
|
+
>
|
|
61
|
+
> ```bash
|
|
62
|
+
> uv venv
|
|
63
|
+
> uv sync
|
|
64
|
+
> ```
|
|
65
|
+
> Once the virtual environment is created, you can install the package using pip.
|
|
66
|
+
>
|
|
66
67
|
> If you're using uv add a `uv` before the pip install command to install into your virtual environment. Eg:
|
|
67
68
|
> ```bash
|
|
68
69
|
> uv pip install active-vision
|
|
@@ -101,12 +102,16 @@ pred_df = al.predict(filepaths)
|
|
|
101
102
|
# Sample low confidence predictions from unlabeled set
|
|
102
103
|
uncertain_df = al.sample_uncertain(pred_df, num_samples=10)
|
|
103
104
|
|
|
104
|
-
# Launch a Gradio UI to label the low confidence samples
|
|
105
|
+
# Launch a Gradio UI to label the low confidence samples, save the labeled samples to a file
|
|
105
106
|
al.label(uncertain_df, output_filename="uncertain")
|
|
106
107
|
```
|
|
107
108
|
|
|
108
109
|

|
|
109
110
|
|
|
111
|
+
In the UI, you can optionally run zero-shot inference on the image. This will use a VLM to predict the label of the image. There are a dozen VLM models as supported in the [x.infer project](https://github.com/dnth/x.infer).
|
|
112
|
+
|
|
113
|
+

|
|
114
|
+
|
|
110
115
|
Once complete, the labeled samples will be save into a new df.
|
|
111
116
|
We can now add the newly labeled data to the training set.
|
|
112
117
|
|
|
@@ -151,12 +156,12 @@ The active learning loop is a iterative process and can keep going until you hit
|
|
|
151
156
|
For this dataset,I decided to stop the active learning loop at 275 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard.
|
|
152
157
|
|
|
153
158
|
|
|
154
|
-
| #Labeled Images
|
|
155
|
-
|
|
156
|
-
| 9469
|
|
157
|
-
| 9469
|
|
158
|
-
| 275
|
|
159
|
-
| 275
|
|
159
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
160
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------- |
|
|
161
|
+
| 9469 | 94.90% | 80 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
162
|
+
| 9469 | 95.11% | 200 | xse_resnext50 | ❌ | [Link](https://github.com/fastai/imagenette) |
|
|
163
|
+
| 275 | 99.33% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/05_retrain_larger.ipynb) |
|
|
164
|
+
| 275 | 93.40% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/04_relabel_loop.ipynb) |
|
|
160
165
|
|
|
161
166
|
### Dog Food
|
|
162
167
|
- num classes: 2
|
|
@@ -166,11 +171,11 @@ To start the active learning loop, I labeled 20 images (10 images from each clas
|
|
|
166
171
|
|
|
167
172
|
I decided to stop the active learning loop at 160 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
168
173
|
|
|
169
|
-
| #Labeled Images
|
|
170
|
-
|
|
171
|
-
| 2100
|
|
172
|
-
| 160
|
|
173
|
-
| 160
|
|
174
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
175
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |--------------------------------------------------------------------------------------------- |
|
|
176
|
+
| 2100 | 99.70% | ? | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/abhishek/autotrain-dog-vs-food) |
|
|
177
|
+
| 160 | 100.00% | 6 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/02_train.ipynb) |
|
|
178
|
+
| 160 | 97.60% | 4 | resnet18 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/dog_food_dataset/01_label.ipynb) |
|
|
174
179
|
|
|
175
180
|
### Oxford-IIIT Pet
|
|
176
181
|
- num classes: 37
|
|
@@ -180,13 +185,27 @@ To start the active learning loop, I labeled 370 images (10 images from each cla
|
|
|
180
185
|
|
|
181
186
|
I decided to stop the active learning loop at 612 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
182
187
|
|
|
183
|
-
| #Labeled Images
|
|
184
|
-
|
|
185
|
-
| 3680
|
|
186
|
-
| 612
|
|
187
|
-
| 612
|
|
188
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
189
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |------------------------------------------------------------------------------------------------- |
|
|
190
|
+
| 3680 | 95.40% | 5 | vit-base-patch16-224 | ❌ | [Link](https://huggingface.co/walterg777/vit-base-oxford-iiit-pets) |
|
|
191
|
+
| 612 | 90.26% | 11 | convnext_small_in22k | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/02_train.ipynb) |
|
|
192
|
+
| 612 | 91.38% | 11 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/oxford_iiit_pets/03_train_vit.ipynb) |
|
|
193
|
+
|
|
194
|
+
### Eurosat RGB
|
|
195
|
+
- num classes: 10
|
|
196
|
+
- num images: 16100
|
|
197
|
+
|
|
198
|
+
To start the active learning loop, I labeled 100 images (10 images from each class) and iteratively labeled the most informative images until I hit 1188 labeled images.
|
|
199
|
+
|
|
200
|
+
I decided to stop the active learning loop at 1188 labeled images because the performance on the evaluation set is close to the top performing model on the leaderboard. You can decide your own stopping point based on your use case.
|
|
188
201
|
|
|
189
202
|
|
|
203
|
+
| #Labeled Images | Evaluation Accuracy | Train Epochs | Model | Active Learning | Source |
|
|
204
|
+
|----------------: |--------------------: |-------------: |---------------------- |:---------------: |-------------------------------------------------------------------------------------------- |
|
|
205
|
+
| 16100 | 98.55% | 6 | vit-base-patch16-224 | ❌ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/03_train_all.ipynb) |
|
|
206
|
+
| 1188 | 94.59% | 6 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
207
|
+
| 1188 | 96.57% | 13 | vit-base-patch16-224 | ✓ | [Link](https://github.com/dnth/active-vision/blob/main/nbs/eurosat_rgb/02_train.ipynb) |
|
|
208
|
+
|
|
190
209
|
|
|
191
210
|
## ➿ Workflow
|
|
192
211
|
This section describes a more detailed workflow for active learning. There are two workflows for active learning that we can use depending on the availability of labeled data.
|
|
@@ -254,55 +273,21 @@ graph TD
|
|
|
254
273
|
|
|
255
274
|
|
|
256
275
|
|
|
257
|
-
|
|
258
|
-
To test out the workflows we will use the [imagenette dataset](https://huggingface.co/datasets/frgfm/imagenette). But this will be applicable to any dataset.
|
|
259
|
-
|
|
260
|
-
Imagenette is a subset of the ImageNet dataset with 10 classes. We will use this dataset to test out the workflows. Additionally, Imagenette has an existing leaderboard which we can use to evaluate the performance of the models.
|
|
261
|
-
|
|
262
|
-
### Step 1: Download the dataset
|
|
263
|
-
Download the imagenette dataset. The imagenette dataset has a train and validation split. Since the leaderboard is based on the validation set, we will evalutate the performance of our model on the validation set to make it easier to compare to the leaderboard.
|
|
264
|
-
|
|
265
|
-
We will treat the imagenette train set as a unlabeled set and iteratively sample from it while monitoring the performance on the validation set. Ideally we will be able to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
276
|
+
## 🧱 Sampling Approaches
|
|
266
277
|
|
|
267
|
-
|
|
278
|
+
Recommendation 1:
|
|
279
|
+
- 10% randomly selected from unlabeled items.
|
|
280
|
+
- 80% selected from the lowest confidence items.
|
|
281
|
+
- 10% selected as outliers.
|
|
268
282
|
|
|
269
|
-
|
|
270
|
-
```python
|
|
271
|
-
from datasets import load_dataset
|
|
272
|
-
|
|
273
|
-
unlabeled_dataset = load_dataset("dnth/active-learning-imagenette", "unlabeled")
|
|
274
|
-
eval_dataset = load_dataset("dnth/active-learning-imagenette", "evaluation")
|
|
275
|
-
```
|
|
283
|
+
Recommendation 2:
|
|
276
284
|
|
|
277
|
-
|
|
278
|
-
|
|
285
|
+
- Sample 100 predicted images at 10–20% confidence.
|
|
286
|
+
- Sample 100 predicted images at 20–30% confidence.
|
|
287
|
+
- Sample 100 predicted images at 30–40% confidence, and so on.
|
|
279
288
|
|
|
280
|
-
### Step 3: Training the proxy model
|
|
281
|
-
Train a proxy model on the initial dataset. The proxy model will be a small model that is easy to train and deploy. We will use the fastai framework to train the model. We will use the resnet18 architecture as a starting point. Once training is complete, compute the accuracy of the proxy model on the validation set and compare it to the leaderboard.
|
|
282
289
|
|
|
283
|
-
|
|
284
|
-
> With the initial model we got 91.24% accuracy on the validation set. See the [notebook](./nbs/01_initial_sampling.ipynb) for more details.
|
|
285
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
286
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
287
|
-
> | 10 | 100 | 91.24% | Initial sampling [notebook](./nbs/01_initial_sampling.ipynb) |
|
|
288
|
-
> | 80 | 9469 | 94.90% | fastai |
|
|
289
|
-
> | 200 | 9469 | 95.11% | fastai |
|
|
290
|
+
Uncertainty and diversity sampling are most effective when combined. For instance, you could first sample the most uncertain items using an uncertainty sampling method, then apply a diversity sampling method such as clustering to select a diverse set from the uncertain items.
|
|
290
291
|
|
|
292
|
+
Ultimately, the right ratios can depend on the specific task and dataset.
|
|
291
293
|
|
|
292
|
-
|
|
293
|
-
### Step 4: Inference on the unlabeled dataset
|
|
294
|
-
Run inference on the unlabeled dataset (the remaining imagenette train set) and evaluate the performance of the proxy model.
|
|
295
|
-
|
|
296
|
-
### Step 5: Active learning
|
|
297
|
-
Use active learning to select the most informative images to label from the unlabeled set. Pick the top 10 images from the unlabeled set that the proxy model is least confident about and label them.
|
|
298
|
-
|
|
299
|
-
### Step 6: Repeat
|
|
300
|
-
Repeat step 3 - 5 until the performance on the validation set is close to the leaderboard. Note the number of labeled images vs the performance on the validation set. Ideally we want to get to a point where the performance on the validation set is close to the leaderboard with minimal number of labeled images.
|
|
301
|
-
|
|
302
|
-
|
|
303
|
-
After the first iteration we got 94.57% accuracy on the validation set. See the [notebook](./nbs/03_retrain_model.ipynb) for more details.
|
|
304
|
-
|
|
305
|
-
> [!TIP]
|
|
306
|
-
> | Train Epochs | Number of Images | Validation Accuracy | Source |
|
|
307
|
-
> |--------------|-----------------|----------------------|------------------|
|
|
308
|
-
> | 10 | 200 | 94.57% | First relabeling [notebook](./nbs/03_retrain_model.ipynb) | -->
|
|
@@ -1,10 +1,11 @@
|
|
|
1
1
|
[project]
|
|
2
2
|
name = "active-vision"
|
|
3
|
-
version = "0.
|
|
3
|
+
version = "0.1.1"
|
|
4
4
|
description = "Active learning for edge vision."
|
|
5
5
|
readme = "README.md"
|
|
6
6
|
requires-python = ">=3.10"
|
|
7
7
|
dependencies = [
|
|
8
|
+
"accelerate>=1.2.1",
|
|
8
9
|
"datasets>=3.2.0",
|
|
9
10
|
"fastai>=2.7.18",
|
|
10
11
|
"gradio>=5.12.0",
|
|
@@ -13,4 +14,6 @@ dependencies = [
|
|
|
13
14
|
"loguru>=0.7.3",
|
|
14
15
|
"seaborn>=0.13.2",
|
|
15
16
|
"timm>=1.0.13",
|
|
17
|
+
"transformers>=4.48.0",
|
|
18
|
+
"xinfer>=0.3.2",
|
|
16
19
|
]
|