lacerda 0.3.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +7 -0
- data/.gitignore +10 -0
- data/.rspec +2 -0
- data/.ruby-gemset +1 -0
- data/.ruby-version +1 -0
- data/CHANGELOG.markdown +8 -0
- data/Gemfile +2 -0
- data/Guardfile +41 -0
- data/README.md +65 -0
- data/Rakefile +9 -0
- data/circle.yml +3 -0
- data/lacerda.gemspec +35 -0
- data/lib/lacerda.rb +10 -0
- data/lib/lacerda/compare/json_schema.rb +123 -0
- data/lib/lacerda/consume_contract.rb +18 -0
- data/lib/lacerda/consumed_object.rb +16 -0
- data/lib/lacerda/contract.rb +34 -0
- data/lib/lacerda/conversion.rb +132 -0
- data/lib/lacerda/conversion/apiary_to_json_schema.rb +9 -0
- data/lib/lacerda/conversion/data_structure.rb +93 -0
- data/lib/lacerda/conversion/error.rb +7 -0
- data/lib/lacerda/infrastructure.rb +74 -0
- data/lib/lacerda/object_description.rb +34 -0
- data/lib/lacerda/publish_contract.rb +22 -0
- data/lib/lacerda/published_object.rb +14 -0
- data/lib/lacerda/service.rb +63 -0
- data/lib/lacerda/tasks.rb +66 -0
- data/lib/lacerda/version.rb +3 -0
- data/stuff/contracts/author/consume.mson +0 -0
- data/stuff/contracts/author/publish.mson +20 -0
- data/stuff/contracts/edward/consume.mson +7 -0
- data/stuff/contracts/edward/publish.mson +0 -0
- data/stuff/explore/blueprint.apib +239 -0
- data/stuff/explore/swagger.yaml +139 -0
- data/stuff/explore/test.apib +14 -0
- data/stuff/explore/test.mson +239 -0
- data/stuff/explore/tmp.txt +27 -0
- metadata +250 -0
checksums.yaml
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
1
|
+
---
|
|
2
|
+
SHA1:
|
|
3
|
+
metadata.gz: b9e353a73a35769ada04cc9efa1a32dfbedc1fee
|
|
4
|
+
data.tar.gz: a18205aa09824893c34a3c861dff1995f92fd28a
|
|
5
|
+
SHA512:
|
|
6
|
+
metadata.gz: 605e8d8df037122645b4a113180ab043cb7472ca35792696e570c9398510b2c4f2703600cce3c3fdceee6f3fe473bbba44c1d259b7dfe9842cac85b31cb4ab0b
|
|
7
|
+
data.tar.gz: 4e9ad371ccb84ba3667c973011d216d0bddae5454a85a4aadfc638053d71c83ddb537cd1ae300561384b6e51c94e2929359c583dac46618b55d2a253f1f6b367
|
data/.gitignore
ADDED
data/.rspec
ADDED
data/.ruby-gemset
ADDED
|
@@ -0,0 +1 @@
|
|
|
1
|
+
minimum-term
|
data/.ruby-version
ADDED
|
@@ -0,0 +1 @@
|
|
|
1
|
+
2
|
data/CHANGELOG.markdown
ADDED
data/Gemfile
ADDED
data/Guardfile
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
1
|
+
# A sample Guardfile
|
|
2
|
+
# More info at https://github.com/guard/guard#readme
|
|
3
|
+
|
|
4
|
+
## Uncomment and set this to only include directories you want to watch
|
|
5
|
+
# directories %w(app lib config test spec features) \
|
|
6
|
+
# .select{|d| Dir.exists?(d) ? d : UI.warning("Directory #{d} does not exist")}
|
|
7
|
+
|
|
8
|
+
## Note: if you are using the `directories` clause above and you are not
|
|
9
|
+
## watching the project directory ('.'), then you will want to move
|
|
10
|
+
## the Guardfile to a watched dir and symlink it back, e.g.
|
|
11
|
+
#
|
|
12
|
+
# $ mkdir config
|
|
13
|
+
# $ mv Guardfile config/
|
|
14
|
+
# $ ln -s config/Guardfile .
|
|
15
|
+
#
|
|
16
|
+
# and, you'll have to watch "config/Guardfile" instead of "Guardfile"
|
|
17
|
+
|
|
18
|
+
guard :bundler do
|
|
19
|
+
watch('Gemfile')
|
|
20
|
+
# Uncomment next line if your Gemfile contains the `gemspec' command.
|
|
21
|
+
watch(/^.+\.gemspec/)
|
|
22
|
+
end
|
|
23
|
+
|
|
24
|
+
guard 'ctags-bundler', :src_path => ["lib"] do
|
|
25
|
+
watch(/^(app|lib|spec\/support)\/.*\.rb$/)
|
|
26
|
+
watch('Gemfile.lock')
|
|
27
|
+
watch(/^.+\.gemspec/)
|
|
28
|
+
end
|
|
29
|
+
|
|
30
|
+
guard :rspec, cmd: 'IGNORE_LOW_COVERAGE=1 rspec', all_on_start: true do
|
|
31
|
+
watch(%r{^spec/support/.*\.mson$}) { "spec" }
|
|
32
|
+
watch(%r{^spec/support/.*\.rb$}) { "spec" }
|
|
33
|
+
watch('spec/spec_helper.rb') { "spec" }
|
|
34
|
+
|
|
35
|
+
# We could run individual specs, sure, but for now I dictate the tests
|
|
36
|
+
# are only green when we have 100% coverage, so partial runs will never
|
|
37
|
+
# succeed. Therefore, always run all the things.
|
|
38
|
+
watch(%r{^(spec/.+_spec\.rb)$}) { "spec" }
|
|
39
|
+
watch(%r{^lib/(.+)\.rb$}) { "spec" }
|
|
40
|
+
end
|
|
41
|
+
|
data/README.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
1
|
+
# Lacerda [](https://circleci.com/gh/moviepilot/minimum-term/tree/master) [](https://coveralls.io/github/moviepilot/minimum-term?branch=master) [](https://codeclimate.com/github/moviepilot/minimum-term) [](https://gemnasium.com/moviepilot/minimum-term)
|
|
2
|
+
|
|
3
|
+

|
|
4
|
+
> «We need total coverage»<sup>[1](http://www.dailyscript.com/scripts/fearandloathing.html)</sup>
|
|
5
|
+
|
|
6
|
+
This gem can:
|
|
7
|
+
|
|
8
|
+
- convert MSON to JSON Schema files
|
|
9
|
+
- read a directory which contains one directory per service
|
|
10
|
+
- read a publish.mson and a consume.mson from each service
|
|
11
|
+
- build a model of your infrastructure knowing
|
|
12
|
+
- which services publishes what to which other service
|
|
13
|
+
- which service consumes what from which other service
|
|
14
|
+
- if all services consume and publish conforming to their contracts.
|
|
15
|
+
|
|
16
|
+
You likely don't want to use it on its own but head on over to the [Zeta](https://github.com/moviepilot/zeta) gem which explains things in more detail. If you're just looking for ONE way to transform MSON files into JSON Schema, read on:
|
|
17
|
+
|
|
18
|
+
## Getting started
|
|
19
|
+
First, check out [this API Blueprint map](https://github.com/apiaryio/api-blueprint/wiki/API-Blueprint-Map) to understand how _API Blueprint_ documents are laid out:
|
|
20
|
+
|
|
21
|
+
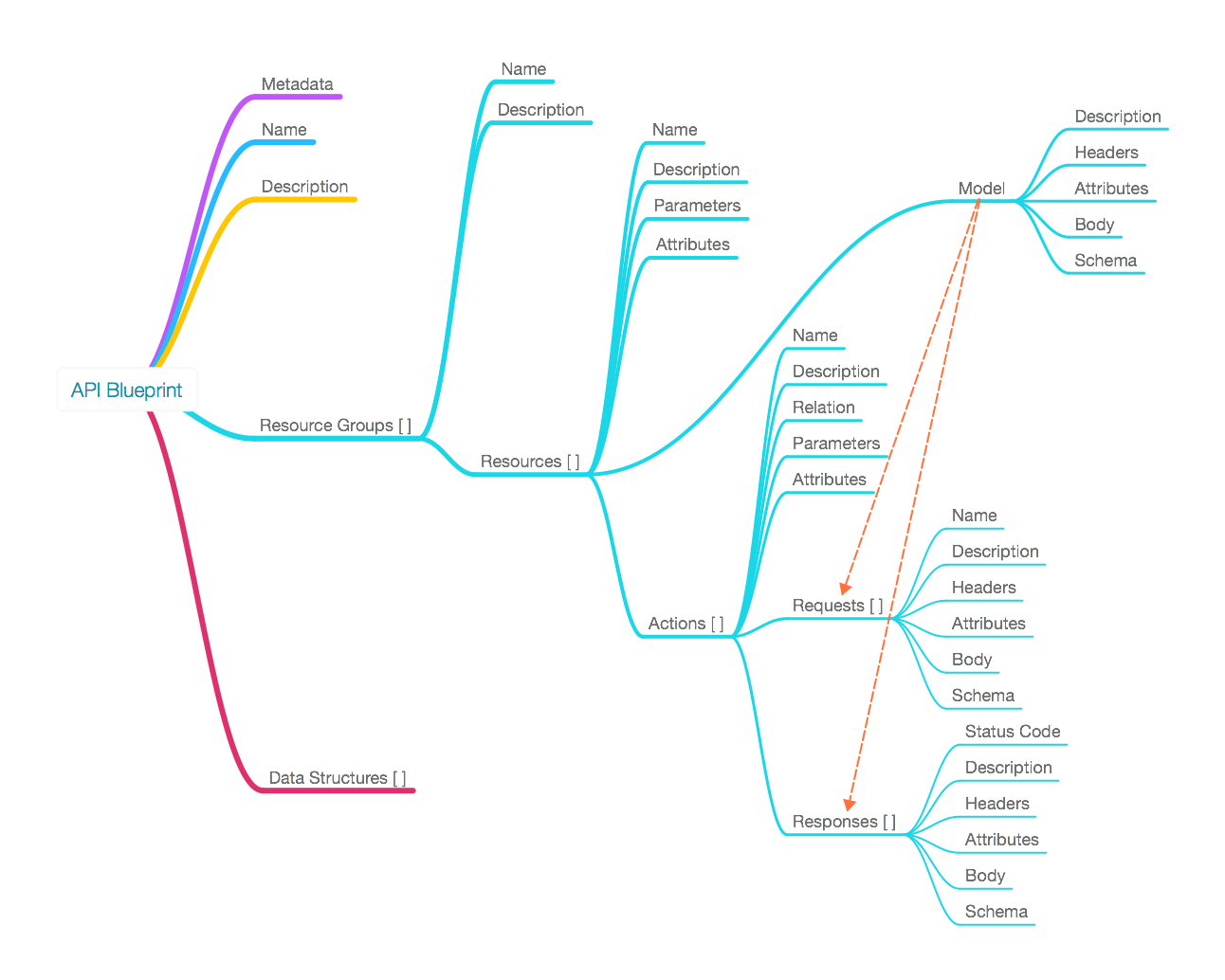
|
|
22
|
+
|
|
23
|
+
You can see that their structure covers a full API use case with resource groups, single resources, actions on those resources including requests and responses. All we want, though, is the little red top level branch called `Data structures`.
|
|
24
|
+
|
|
25
|
+
We're using a ruby gem called [RedSnow](https://github.com/apiaryio/redsnow), which has bindings to [SnowCrash](https://github.com/apiaryio/snowcrash) which parses _API Blueprints_ into an AST.
|
|
26
|
+
|
|
27
|
+
Luckily, a rake task does all that for you. To convert all `*.mson` files in `contracts/` into `*.schema.json` files,
|
|
28
|
+
|
|
29
|
+
put this in your `Rakefile`:
|
|
30
|
+
|
|
31
|
+
```ruby
|
|
32
|
+
require "lacerda/tasks"
|
|
33
|
+
```
|
|
34
|
+
|
|
35
|
+
and smoke it:
|
|
36
|
+
|
|
37
|
+
```shell
|
|
38
|
+
/home/dev/lacerda$ DATA_DIR=contracts/ rake lacerda:mson_to_json_schema
|
|
39
|
+
Converting 4 files:
|
|
40
|
+
OK /home/dev/lacerda/contracts/consumer/consume.mson
|
|
41
|
+
OK /home/dev/lacerda/contracts/invalid_property/consume.mson
|
|
42
|
+
OK /home/dev/lacerda/contracts/missing_required/consume.mson
|
|
43
|
+
OK /home/dev/lacerda/contracts/publisher/publish.mson
|
|
44
|
+
/home/dev/lacerda$
|
|
45
|
+
```
|
|
46
|
+
|
|
47
|
+
## Tests and development
|
|
48
|
+
- run `bundle` once
|
|
49
|
+
- run `guard` in a spare terminal which will run the tests,
|
|
50
|
+
install gems, and so forth
|
|
51
|
+
- run `rspec spec` to run all the tests
|
|
52
|
+
- check out `open coverage/index.html` or `open coverage/rcov/index.html`
|
|
53
|
+
- run `bundle console` to play around with a console
|
|
54
|
+
|
|
55
|
+
## Structure
|
|
56
|
+
|
|
57
|
+
By converting all files in a directory this gem will build up the following relationships:
|
|
58
|
+
|
|
59
|
+
- Infrastructure
|
|
60
|
+
- Service
|
|
61
|
+
- Contracts
|
|
62
|
+
- Publish contract
|
|
63
|
+
- PublishedObjects
|
|
64
|
+
- Consume contract
|
|
65
|
+
- ConsumedObjects
|
data/Rakefile
ADDED
data/circle.yml
ADDED
data/lacerda.gemspec
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
1
|
+
# coding: utf-8
|
|
2
|
+
lib = File.expand_path('../lib', __FILE__)
|
|
3
|
+
$LOAD_PATH.unshift(lib) unless $LOAD_PATH.include?(lib)
|
|
4
|
+
require 'lacerda/version'
|
|
5
|
+
|
|
6
|
+
Gem::Specification.new do |spec|
|
|
7
|
+
spec.name = "lacerda"
|
|
8
|
+
spec.version = Lacerda::VERSION
|
|
9
|
+
spec.authors = ["Jannis Hermanns"]
|
|
10
|
+
spec.email = ["jannis@gmail.com"]
|
|
11
|
+
|
|
12
|
+
spec.summary = 'Markdown publish/consume contract parser and validator'
|
|
13
|
+
spec.description = 'Specify which objects your services publish or consume in MSON (markdown) and let this gem validate these contracts.'
|
|
14
|
+
spec.homepage = "https://github.com/moviepilot/lacerda"
|
|
15
|
+
|
|
16
|
+
spec.files = `git ls-files -z`.split("\x0").reject { |f| f.match(%r{^(test|spec|features)/}) }
|
|
17
|
+
spec.bindir = "bin"
|
|
18
|
+
spec.executables = spec.files.grep(%r{^bin/}) { |f| File.basename(f) }
|
|
19
|
+
spec.require_paths = ["lib"]
|
|
20
|
+
spec.license = 'MIT'
|
|
21
|
+
|
|
22
|
+
spec.add_runtime_dependency "activesupport"
|
|
23
|
+
spec.add_runtime_dependency "rake", ["~> 10.2"]
|
|
24
|
+
spec.add_runtime_dependency "json-schema", ["~> 2.5"]
|
|
25
|
+
spec.add_runtime_dependency "redsnow", ["~> 0.4"]
|
|
26
|
+
spec.add_runtime_dependency "colorize"
|
|
27
|
+
|
|
28
|
+
spec.add_development_dependency "bundler", ["~> 1"]
|
|
29
|
+
spec.add_development_dependency "guard-bundler", ["~> 2.1"]
|
|
30
|
+
spec.add_development_dependency "guard-ctags-bundler", ["~> 1.4"]
|
|
31
|
+
spec.add_development_dependency "guard-rspec", ["~> 4.6"]
|
|
32
|
+
spec.add_development_dependency "rspec", ["~> 3.3"]
|
|
33
|
+
spec.add_development_dependency "coveralls", ["~> 0.8"]
|
|
34
|
+
spec.add_development_dependency "codeclimate-test-reporter"
|
|
35
|
+
end
|
data/lib/lacerda.rb
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
1
|
+
module Lacerda
|
|
2
|
+
module Compare
|
|
3
|
+
class JsonSchema
|
|
4
|
+
ERRORS = {
|
|
5
|
+
:ERR_ARRAY_ITEM_MISMATCH => nil,
|
|
6
|
+
:ERR_MISSING_DEFINITION => nil,
|
|
7
|
+
:ERR_MISSING_POINTER => nil,
|
|
8
|
+
:ERR_MISSING_PROPERTY => nil,
|
|
9
|
+
:ERR_MISSING_REQUIRED => nil,
|
|
10
|
+
:ERR_MISSING_TYPE_AND_REF => nil,
|
|
11
|
+
:ERR_TYPE_MISMATCH => nil,
|
|
12
|
+
:ERR_NOT_SUPPORTED => nil
|
|
13
|
+
}
|
|
14
|
+
|
|
15
|
+
attr_reader :errors
|
|
16
|
+
|
|
17
|
+
def initialize(containing_schema)
|
|
18
|
+
@containing_schema = containing_schema
|
|
19
|
+
end
|
|
20
|
+
|
|
21
|
+
def contains?(contained_schema, pry = false)
|
|
22
|
+
@errors = []
|
|
23
|
+
@contained_schema = contained_schema
|
|
24
|
+
definitions_contained?
|
|
25
|
+
end
|
|
26
|
+
|
|
27
|
+
private
|
|
28
|
+
|
|
29
|
+
def definitions_contained?
|
|
30
|
+
@contained_schema['definitions'].each do |property, contained_property|
|
|
31
|
+
containing_property = @containing_schema['definitions'][property]
|
|
32
|
+
return _e(:ERR_MISSING_DEFINITION, [property]) unless containing_property
|
|
33
|
+
return false unless schema_contains?(containing_property, contained_property, [property])
|
|
34
|
+
end
|
|
35
|
+
true
|
|
36
|
+
end
|
|
37
|
+
|
|
38
|
+
def _e(error, location, extra = nil)
|
|
39
|
+
message = [ERRORS[error], extra].compact.join(": ")
|
|
40
|
+
@errors.push(error: error, message: message, location: location.join("/"))
|
|
41
|
+
false
|
|
42
|
+
end
|
|
43
|
+
|
|
44
|
+
def schema_contains?(publish, consume, location = [])
|
|
45
|
+
|
|
46
|
+
# We can only compare types and $refs, so let's make
|
|
47
|
+
# sure they're there
|
|
48
|
+
return _e!(:ERR_MISSING_TYPE_AND_REF) unless
|
|
49
|
+
(consume['type'] or consume['$ref']) and
|
|
50
|
+
(publish['type'] or publish['$ref'])
|
|
51
|
+
|
|
52
|
+
# There's four possibilities here:
|
|
53
|
+
#
|
|
54
|
+
# 1) publish and consume have a type defined
|
|
55
|
+
# 2) publish and consume have a $ref defined
|
|
56
|
+
# 3) publish has a $ref defined, and consume an inline object
|
|
57
|
+
# 4) consume has a $ref defined, and publish an inline object
|
|
58
|
+
# (we don't support this yet, as otherwise couldn't check for
|
|
59
|
+
# missing definitions, because we could never know if something
|
|
60
|
+
# specified in the definitions of the consuming schema exists in
|
|
61
|
+
# the publishing schema as an inline property somewhere).
|
|
62
|
+
# TODO: check if what I just said makes sense. I'm not sure anymore.
|
|
63
|
+
# Let's go:
|
|
64
|
+
|
|
65
|
+
# 1)
|
|
66
|
+
if (consume['type'] and publish['type'])
|
|
67
|
+
if consume['type'] != publish['type']
|
|
68
|
+
return _e(:ERR_TYPE_MISMATCH, location, "#{consume['type']} != #{publish['type']}")
|
|
69
|
+
end
|
|
70
|
+
|
|
71
|
+
# 2)
|
|
72
|
+
elsif(consume['$ref'] and publish['$ref'])
|
|
73
|
+
resolved_consume = resolve_pointer(consume['$ref'], @contained_schema)
|
|
74
|
+
resolved_publish = resolve_pointer(publish['$ref'], @containing_schema)
|
|
75
|
+
return schema_contains?(resolved_publish, resolved_consume, location)
|
|
76
|
+
|
|
77
|
+
# 3)
|
|
78
|
+
elsif(consume['type'] and publish['$ref'])
|
|
79
|
+
if resolved_ref = resolve_pointer(publish['$ref'], @containing_schema)
|
|
80
|
+
return schema_contains?(resolved_ref, consume, location)
|
|
81
|
+
else
|
|
82
|
+
return _e(:ERR_MISSING_POINTER, location, publish['$ref'])
|
|
83
|
+
end
|
|
84
|
+
|
|
85
|
+
# 4)
|
|
86
|
+
elsif(consume['$ref'] and publish['type'])
|
|
87
|
+
return _e(:ERR_NOT_SUPPORTED, location)
|
|
88
|
+
end
|
|
89
|
+
|
|
90
|
+
# Make sure required properties in consume are required in publish
|
|
91
|
+
consume_required = consume['required'] || []
|
|
92
|
+
publish_required = publish['required'] || []
|
|
93
|
+
missing = (consume_required - publish_required)
|
|
94
|
+
return _e(:ERR_MISSING_REQUIRED, location, missing.to_json) unless missing.empty?
|
|
95
|
+
|
|
96
|
+
# We already know that publish and consume's type are equal
|
|
97
|
+
# but if they're objects, we need to do some recursion
|
|
98
|
+
if consume['type'] == 'object'
|
|
99
|
+
consume['properties'].each do |property, schema|
|
|
100
|
+
return _e(:ERR_MISSING_PROPERTY, location, property) unless publish['properties'][property]
|
|
101
|
+
return false unless schema_contains?(publish['properties'][property], schema, location + [property])
|
|
102
|
+
end
|
|
103
|
+
end
|
|
104
|
+
|
|
105
|
+
if consume['type'] == 'array'
|
|
106
|
+
sorted_publish = publish['items'].sort
|
|
107
|
+
consume['items'].sort.each_with_index do |item, i|
|
|
108
|
+
next if schema_contains?(sorted_publish[i], item)
|
|
109
|
+
return _e(:ERR_ARRAY_ITEM_MISMATCH, location)
|
|
110
|
+
end
|
|
111
|
+
end
|
|
112
|
+
|
|
113
|
+
true
|
|
114
|
+
end
|
|
115
|
+
|
|
116
|
+
def resolve_pointer(pointer, schema)
|
|
117
|
+
type = pointer[/\#\/definitions\/([^\/]+)$/, 1]
|
|
118
|
+
return false unless type
|
|
119
|
+
schema['definitions'][type]
|
|
120
|
+
end
|
|
121
|
+
end
|
|
122
|
+
end
|
|
123
|
+
end
|
|
@@ -0,0 +1,18 @@
|
|
|
1
|
+
require 'lacerda/contract'
|
|
2
|
+
|
|
3
|
+
module Lacerda
|
|
4
|
+
class ConsumeContract < Lacerda::Contract
|
|
5
|
+
def object_description_class
|
|
6
|
+
Lacerda::ConsumedObject
|
|
7
|
+
end
|
|
8
|
+
|
|
9
|
+
def scoped_schema(service)
|
|
10
|
+
# Poor man's deep clone: json 🆗 🆒
|
|
11
|
+
filtered_schema = JSON.parse(schema.to_json)
|
|
12
|
+
filtered_schema['definitions'].select! do |k|
|
|
13
|
+
k.underscore.start_with?(service.name.underscore+Lacerda::SCOPE_SEPARATOR)
|
|
14
|
+
end
|
|
15
|
+
filtered_schema
|
|
16
|
+
end
|
|
17
|
+
end
|
|
18
|
+
end
|
|
@@ -0,0 +1,16 @@
|
|
|
1
|
+
require 'lacerda/object_description'
|
|
2
|
+
|
|
3
|
+
module Lacerda
|
|
4
|
+
class ConsumedObject < Lacerda::ObjectDescription
|
|
5
|
+
|
|
6
|
+
def publisher
|
|
7
|
+
i = @scoped_name.index(Lacerda::SCOPE_SEPARATOR)
|
|
8
|
+
return @defined_in_service unless i
|
|
9
|
+
@defined_in_service.infrastructure.services[@scoped_name[0...i].underscore.to_sym]
|
|
10
|
+
end
|
|
11
|
+
|
|
12
|
+
def consumer
|
|
13
|
+
@defined_in_service
|
|
14
|
+
end
|
|
15
|
+
end
|
|
16
|
+
end
|
|
@@ -0,0 +1,34 @@
|
|
|
1
|
+
require 'active_support/core_ext/hash/indifferent_access'
|
|
2
|
+
require 'lacerda/published_object'
|
|
3
|
+
require 'lacerda/consumed_object'
|
|
4
|
+
|
|
5
|
+
module Lacerda
|
|
6
|
+
class Contract
|
|
7
|
+
attr_reader :service, :schema
|
|
8
|
+
|
|
9
|
+
def initialize(service, schema_or_file)
|
|
10
|
+
@service = service
|
|
11
|
+
load_schema(schema_or_file)
|
|
12
|
+
end
|
|
13
|
+
|
|
14
|
+
def objects
|
|
15
|
+
return [] unless @schema[:definitions]
|
|
16
|
+
@schema[:definitions].map do |scoped_name, schema|
|
|
17
|
+
object_description_class.new(service, scoped_name, schema)
|
|
18
|
+
end
|
|
19
|
+
end
|
|
20
|
+
|
|
21
|
+
private
|
|
22
|
+
|
|
23
|
+
def load_schema(schema_or_file)
|
|
24
|
+
if schema_or_file.is_a?(Hash)
|
|
25
|
+
@schema = schema_or_file
|
|
26
|
+
elsif File.readable?(schema_or_file)
|
|
27
|
+
@schema = JSON.parse(open(schema_or_file).read)
|
|
28
|
+
else
|
|
29
|
+
@schema = {}
|
|
30
|
+
end
|
|
31
|
+
@schema = @schema.with_indifferent_access
|
|
32
|
+
end
|
|
33
|
+
end
|
|
34
|
+
end
|
|
@@ -0,0 +1,132 @@
|
|
|
1
|
+
require 'fileutils'
|
|
2
|
+
require 'open3'
|
|
3
|
+
require 'lacerda/conversion/apiary_to_json_schema'
|
|
4
|
+
require 'lacerda/conversion/error'
|
|
5
|
+
require 'redsnow'
|
|
6
|
+
|
|
7
|
+
module Lacerda
|
|
8
|
+
module Conversion
|
|
9
|
+
def self.mson_to_json_schema(filename:, keep_intermediary_files: false, verbose: false)
|
|
10
|
+
begin
|
|
11
|
+
mson_to_json_schema!(filename: filename, keep_intermediary_files: keep_intermediary_files, verbose: verbose)
|
|
12
|
+
puts "OK ".green + filename if verbose
|
|
13
|
+
true
|
|
14
|
+
rescue
|
|
15
|
+
puts "ERROR ".red + filename if verbose
|
|
16
|
+
false
|
|
17
|
+
end
|
|
18
|
+
end
|
|
19
|
+
|
|
20
|
+
def self.mson_to_json_schema!(filename:, keep_intermediary_files: false, verbose: true)
|
|
21
|
+
|
|
22
|
+
# For now, we'll use the containing directory's name as a scope
|
|
23
|
+
service_scope = File.dirname(filename).split(File::SEPARATOR).last.underscore
|
|
24
|
+
|
|
25
|
+
# Parse MSON to an apiary blueprint AST
|
|
26
|
+
# (see https://github.com/apiaryio/api-blueprint/wiki/API-Blueprint-Map)
|
|
27
|
+
ast_file = mson_to_ast_json(filename)
|
|
28
|
+
|
|
29
|
+
# Pluck out Data structures from it
|
|
30
|
+
data_structures = data_structures_from_blueprint_ast(ast_file)
|
|
31
|
+
|
|
32
|
+
# Generate json schema from each contained data structure
|
|
33
|
+
schema = {
|
|
34
|
+
"$schema" => "http://json-schema.org/draft-04/schema#",
|
|
35
|
+
"title" => service_scope,
|
|
36
|
+
"definitions" => {},
|
|
37
|
+
"type" => "object",
|
|
38
|
+
"properties" => {},
|
|
39
|
+
}
|
|
40
|
+
|
|
41
|
+
# The scope for the data structure is the name of the service
|
|
42
|
+
# publishing the object. So if we're parsing a 'consume' schema,
|
|
43
|
+
# the containing objects are alredy scoped (because a consume
|
|
44
|
+
# schema says 'i consume object X from service Y'.
|
|
45
|
+
basename = File.basename(filename)
|
|
46
|
+
if basename.end_with?("publish.mson")
|
|
47
|
+
data_structure_autoscope = service_scope
|
|
48
|
+
elsif basename.end_with?("consume.mson")
|
|
49
|
+
data_structure_autoscope = nil
|
|
50
|
+
else
|
|
51
|
+
raise Error, "Invalid filename #{basename}, can't tell if it's a publish or consume schema"
|
|
52
|
+
end
|
|
53
|
+
|
|
54
|
+
# The json schema we're constructing contains every known
|
|
55
|
+
# object type in the 'definitions'. So if we have definitions for
|
|
56
|
+
# the objects User, Post and Tag, the schema will look like this:
|
|
57
|
+
#
|
|
58
|
+
# {
|
|
59
|
+
# "$schema": "..."
|
|
60
|
+
#
|
|
61
|
+
# "definitions": {
|
|
62
|
+
# "user": { "type": "object", "properties": { ... }}
|
|
63
|
+
# "post": { "type": "object", "properties": { ... }}
|
|
64
|
+
# "tag": { "type": "object", "properties": { ... }}
|
|
65
|
+
# }
|
|
66
|
+
#
|
|
67
|
+
# "properties": {
|
|
68
|
+
# "user": "#/definitions/user"
|
|
69
|
+
# "post": "#/definitions/post"
|
|
70
|
+
# "tag": "#/definitions/tag"
|
|
71
|
+
# }
|
|
72
|
+
#
|
|
73
|
+
# }
|
|
74
|
+
#
|
|
75
|
+
# So when testing an object of type `user` against this schema,
|
|
76
|
+
# we need to wrap it as:
|
|
77
|
+
#
|
|
78
|
+
# {
|
|
79
|
+
# user: {
|
|
80
|
+
# "your": "actual",
|
|
81
|
+
# "data": "goes here"
|
|
82
|
+
# }
|
|
83
|
+
# }
|
|
84
|
+
#
|
|
85
|
+
data_structures.each do |data|
|
|
86
|
+
id = data['name']['literal']
|
|
87
|
+
json= DataStructure.new(id, data, data_structure_autoscope).to_json
|
|
88
|
+
member = json.delete('title')
|
|
89
|
+
schema['definitions'][member] = json
|
|
90
|
+
schema['properties'][member] = {"$ref" => "#/definitions/#{member}"}
|
|
91
|
+
end
|
|
92
|
+
|
|
93
|
+
# Write it in a file
|
|
94
|
+
outfile = filename.gsub(/\.\w+$/, '.schema.json')
|
|
95
|
+
File.open(outfile, 'w'){ |f| f.puts JSON.pretty_generate(schema) }
|
|
96
|
+
|
|
97
|
+
# Clean up
|
|
98
|
+
FileUtils.rm_f(ast_file) unless keep_intermediary_files
|
|
99
|
+
true
|
|
100
|
+
end
|
|
101
|
+
|
|
102
|
+
def self.data_structures_from_blueprint_ast(filename)
|
|
103
|
+
c = JSON.parse(open(filename).read)['ast']['content'].first
|
|
104
|
+
return [] unless c
|
|
105
|
+
c['content']
|
|
106
|
+
end
|
|
107
|
+
|
|
108
|
+
def self.mson_to_ast_json(filename)
|
|
109
|
+
input = filename
|
|
110
|
+
output = filename.gsub(/\.\w+$/, '.blueprint-ast.json')
|
|
111
|
+
|
|
112
|
+
|
|
113
|
+
parse_result = FFI::MemoryPointer.new :pointer
|
|
114
|
+
RedSnow::Binding.drafter_c_parse(open(input).read, 0, parse_result)
|
|
115
|
+
parse_result = parse_result.get_pointer(0)
|
|
116
|
+
|
|
117
|
+
status = -1
|
|
118
|
+
result = ''
|
|
119
|
+
|
|
120
|
+
unless parse_result.null?
|
|
121
|
+
status = 0
|
|
122
|
+
result = parse_result.read_string
|
|
123
|
+
end
|
|
124
|
+
|
|
125
|
+
File.open(output, 'w'){ |f| f.puts(result) }
|
|
126
|
+
|
|
127
|
+
output
|
|
128
|
+
ensure
|
|
129
|
+
RedSnow::Memory.free(parse_result)
|
|
130
|
+
end
|
|
131
|
+
end
|
|
132
|
+
end
|