fuzzy_match 1.5.0 → 2.0.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +8 -8
- data/.rspec +2 -0
- data/CHANGELOG +14 -0
- data/Gemfile +8 -0
- data/README.markdown +58 -38
- data/Rakefile +0 -9
- data/bin/fuzzy_match +106 -0
- data/fuzzy_match.gemspec +4 -4
- data/groupings-screenshot.png +0 -0
- data/highlevel.graffle +0 -0
- data/highlevel.png +0 -0
- data/lib/fuzzy_match/record.rb +58 -0
- data/lib/fuzzy_match/result.rb +11 -8
- data/lib/fuzzy_match/rule/grouping.rb +70 -12
- data/lib/fuzzy_match/rule/identity.rb +3 -3
- data/lib/fuzzy_match/rule.rb +1 -1
- data/lib/fuzzy_match/score/amatch.rb +0 -4
- data/lib/fuzzy_match/score/pure_ruby.rb +2 -8
- data/lib/fuzzy_match/score.rb +4 -0
- data/lib/fuzzy_match/similarity.rb +10 -32
- data/lib/fuzzy_match/version.rb +1 -1
- data/lib/fuzzy_match.rb +78 -94
- data/{test/test_amatch.rb → spec/amatch_spec.rb} +1 -2
- data/{test/test_cache.rb → spec/cache_spec.rb} +7 -7
- data/spec/foo.rb +9 -0
- data/spec/fuzzy_match_spec.rb +354 -0
- data/spec/grouping_spec.rb +60 -0
- data/spec/identity_spec.rb +29 -0
- data/{test/test_wrapper.rb → spec/record_spec.rb} +3 -7
- data/spec/spec_helper.rb +21 -0
- metadata +56 -50
- data/bin/fuzzy_match_checker +0 -71
- data/examples/bts_aircraft/5-2-A.htm +0 -10305
- data/examples/bts_aircraft/5-2-B.htm +0 -9576
- data/examples/bts_aircraft/5-2-D.htm +0 -7094
- data/examples/bts_aircraft/5-2-E.htm +0 -2349
- data/examples/bts_aircraft/5-2-G.htm +0 -2922
- data/examples/bts_aircraft/groupings.csv +0 -1
- data/examples/bts_aircraft/identities.csv +0 -1
- data/examples/bts_aircraft/negatives.csv +0 -1
- data/examples/bts_aircraft/normalizers.csv +0 -1
- data/examples/bts_aircraft/number_260.csv +0 -334
- data/examples/bts_aircraft/positives.csv +0 -1
- data/examples/bts_aircraft/test_bts_aircraft.rb +0 -116
- data/examples/first_name_matching.rb +0 -15
- data/examples/icao-bts.xls +0 -0
- data/lib/fuzzy_match/rule/normalizer.rb +0 -20
- data/lib/fuzzy_match/rule/stop_word.rb +0 -11
- data/lib/fuzzy_match/wrapper.rb +0 -73
- data/test/helper.rb +0 -12
- data/test/test_fuzzy_match.rb +0 -304
- data/test/test_fuzzy_match_convoluted.rb.disabled +0 -268
- data/test/test_grouping.rb +0 -28
- data/test/test_identity.rb +0 -34
- data/test/test_normalizer.rb +0 -10
checksums.yaml
CHANGED
|
@@ -1,15 +1,15 @@
|
|
|
1
1
|
---
|
|
2
2
|
!binary "U0hBMQ==":
|
|
3
3
|
metadata.gz: !binary |-
|
|
4
|
-
|
|
4
|
+
NDhjZDk1NjAxOTMzMGZkMWU4ODAyNjRmMzA4YzlhNzQwZWIwZGU5MQ==
|
|
5
5
|
data.tar.gz: !binary |-
|
|
6
|
-
|
|
6
|
+
OTk5Yjc2NmY4ZTY3NDkyOTFjOGQwYjlhZDgwYjk2NmViMzI0NGYyMQ==
|
|
7
7
|
!binary "U0hBNTEy":
|
|
8
8
|
metadata.gz: !binary |-
|
|
9
|
-
|
|
10
|
-
|
|
11
|
-
|
|
9
|
+
YmE4MjUxNzg0MmFlN2UyMTYxNGJhNGRiZjZmYThjOGYzNDMwYjRjZmVlNTBk
|
|
10
|
+
MmQzZjE0NWJiN2IzZGY3YzBhZWQzOWVkMTNjZmVhODUwMTk5ODJmMTY0Njk0
|
|
11
|
+
ODEwMjc2MDc0M2M2YjNmZmY5MmViZGNiOTYzNGQ2MjQxODZkZDQ=
|
|
12
12
|
data.tar.gz: !binary |-
|
|
13
|
-
|
|
14
|
-
|
|
15
|
-
|
|
13
|
+
NGIzYTVmNzk0N2E4YjU4ZDc1MTNiNTU4YmRhMDgxNmM5Y2Q0MWM2NzYzZjhj
|
|
14
|
+
NTA3ZDg5NWE2ZWM2MWZkNDRjM2I1NWY2NzA4ODAwM2E4NTIwY2NmYWI4MzBm
|
|
15
|
+
MjliNDZkNzIzMGJhZTVhMzViNThhZjk1MmM1NTViNmQ4ODFjNzM=
|
data/.rspec
ADDED
data/CHANGELOG
CHANGED
|
@@ -1,3 +1,17 @@
|
|
|
1
|
+
2.0.0 / 2013-05-22
|
|
2
|
+
|
|
3
|
+
* Breaking changes
|
|
4
|
+
|
|
5
|
+
* normalizers removed - use groupings instead
|
|
6
|
+
* first_grouping_decides removed
|
|
7
|
+
* FuzzyMatch#free gone
|
|
8
|
+
|
|
9
|
+
* Enhancements
|
|
10
|
+
|
|
11
|
+
* chained groupings!
|
|
12
|
+
* faster and simpler structure
|
|
13
|
+
* FuzzyMatch#find_with_score returns [record, dice_score, lev_score]
|
|
14
|
+
|
|
1
15
|
1.5.0 / 2013-04-03
|
|
2
16
|
|
|
3
17
|
* Breaking changes
|
data/Gemfile
CHANGED
data/README.markdown
CHANGED
|
@@ -4,20 +4,9 @@ Find a needle in a haystack based on string similarity and regular expression ru
|
|
|
4
4
|
|
|
5
5
|
Replaces [`loose_tight_dictionary`](https://github.com/seamusabshere/loose_tight_dictionary) because that was a confusing name.
|
|
6
6
|
|
|
7
|
-
|
|
8
|
-
|
|
9
|
-
<p><a href="http://brighterplanet.com"><img src="https://s3.amazonaws.com/static.brighterplanet.com/assets/logos/flush-left/inline/green/rasterized/brighter_planet-160-transparent.png" alt="Brighter Planet logo"/></a></p>
|
|
10
|
-
|
|
11
|
-
We use `fuzzy_match` for [data science at Brighter Planet](http://brighterplanet.com/research) and in production at
|
|
12
|
-
|
|
13
|
-
* [Brighter Planet's impact estimate web service](http://impact.brighterplanet.com)
|
|
14
|
-
* [Brighter Planet's reference data web service](http://data.brighterplanet.com)
|
|
15
|
-
|
|
16
|
-
We often combine it with [`remote_table`](https://github.com/seamusabshere/remote_table) and [`errata`](https://github.com/seamusabshere/errata):
|
|
7
|
+
Warning! `normalizers` are gone in version 2 and above! See the CHANGELOG and check out enhanced (and hopefully more intuitive) `groupings`.
|
|
17
8
|
|
|
18
|
-
|
|
19
|
-
- correct serious or repeated errors with `errata`
|
|
20
|
-
- `fuzzy_match` the rest
|
|
9
|
+

|
|
21
10
|
|
|
22
11
|
## Quickstart
|
|
23
12
|
|
|
@@ -30,41 +19,62 @@ See also the blog post [Fuzzy match in Ruby](http://numbers.brighterplanet.com/2
|
|
|
30
19
|
|
|
31
20
|
## Default matching (string similarity)
|
|
32
21
|
|
|
33
|
-
At the core, and even if you configure nothing else, string similarity (calculated by "pair distance" aka Dice's) is used to compare records.
|
|
22
|
+
At the core, and even if you configure nothing else, string similarity (calculated by "pair distance" aka Dice's Coefficient) is used to compare records.
|
|
34
23
|
|
|
35
24
|
You can tell `FuzzyMatch` what field or method to use via the `:read` option... for example, let's say you want to match a `Country` object like `#<Country name:"Uruguay" iso_3166_code:"UY">`
|
|
36
25
|
|
|
37
|
-
>>
|
|
26
|
+
>> fz = FuzzyMatch.new(Country.all, :read => :name)
|
|
38
27
|
=> #<FuzzyMatch: [...]>
|
|
39
|
-
>>
|
|
40
|
-
=> #<Country name:"Uruguay" iso_3166_code:"UY">
|
|
28
|
+
>> fz.find('youruguay')
|
|
29
|
+
=> #<Country name:"Uruguay" iso_3166_code:"UY">
|
|
41
30
|
|
|
42
31
|
## Optional rules (regular expressions)
|
|
43
32
|
|
|
44
|
-
You can improve the default matchings with rules. There are
|
|
33
|
+
You can improve the default matchings with rules. There are 3 different kinds of rules. Each rule is a regular expression.
|
|
45
34
|
|
|
46
35
|
We suggest that you **first try without any rules** and only define them to improve matching, prevent false positives, etc.
|
|
47
36
|
|
|
48
|
-
|
|
49
|
-
=> #<FuzzyMatch: [...]>
|
|
50
|
-
>> matcher.find('fordf250')
|
|
51
|
-
=> "Ford F-250"
|
|
52
|
-
>> matcher.find('gmc truck k1500')
|
|
53
|
-
=> "GMC 1500"
|
|
37
|
+
### Groupings
|
|
54
38
|
|
|
55
|
-
|
|
39
|
+
Group records together. The two laws of groupings:
|
|
56
40
|
|
|
57
|
-
|
|
41
|
+
1. If a needle matches a grouping, only compare it with straws in the same grouping; (the "buddies vs buddies" rule)
|
|
42
|
+
2. If a needle doesn't match any grouping, only compare it with straws that also don't match ANY grouping (the "misfits vs misfits" rule)
|
|
43
|
+
|
|
44
|
+
The two laws of chained groupings: (new in v2.0 and rather important)
|
|
45
|
+
|
|
46
|
+
1. Sub-groupings (e.g., `/plaza/i` below) only match if their primary (e.g., `/ramada/i`) does
|
|
47
|
+
2. In final grouping decisions, sub-groupings win over primaries (so "Ramada Inn" is NOT grouped with "Ramada Plaza", but if you removed `/plaza/i` sub-grouping, then they would be grouped together)
|
|
48
|
+
|
|
49
|
+
Hopefully they are rather intuitive once you start using them.
|
|
50
|
+
|
|
51
|
+
[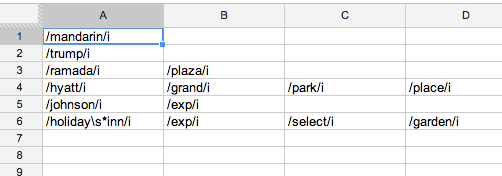](https://docs.google.com/spreadsheet/pub?key=0AkCJNpm9Ks6JdG4xSWhfWFlOV1RsZ2NCeU9seGx6cnc&single=true&gid=0&output=html)
|
|
52
|
+
|
|
53
|
+
That will...
|
|
58
54
|
|
|
59
|
-
|
|
55
|
+
* separate "Orient Express Hotel" and "Ramada Conference Center Mandarin" from real Mandarin Oriental hotels
|
|
56
|
+
* keep "Trump Hotel Collection" away from "Luxury Collection" (another real hotel brand) without messing with the word "Luxury"
|
|
57
|
+
* make sure that "Ramada Plaza" are always grouped with other RPs—and not with plain old Ramadas—and vice versa
|
|
58
|
+
* splits out Hyatts into their different brands
|
|
59
|
+
* and more
|
|
60
60
|
|
|
61
|
-
|
|
61
|
+
You specify chained groupings as arrays of regexps:
|
|
62
|
+
|
|
63
|
+
groupings = [
|
|
64
|
+
/mandarin/i,
|
|
65
|
+
/trump/i,
|
|
66
|
+
[ /ramada/i, /plaza/i ],
|
|
67
|
+
...
|
|
68
|
+
]
|
|
69
|
+
fz = FuzzyMatch.new(haystack, groupings: groupings)
|
|
70
|
+
|
|
71
|
+
This way of specifying groupings is meant to be easy to load from a CSV, like `bin/fuzzy_match` does.
|
|
62
72
|
|
|
63
73
|
Formerly called "blockings," but that was jargon that confused people.
|
|
64
74
|
|
|
65
75
|
### Identities
|
|
66
76
|
|
|
67
|
-
Prevent impossible matches.
|
|
77
|
+
Prevent impossible matches. Can be very confusing—see if you can make things work with groupings first.
|
|
68
78
|
|
|
69
79
|
Adding an identity like `/(f)-?(\d50)/i` ensures that "Ford F-150" and "Ford F-250" never match.
|
|
70
80
|
|
|
@@ -72,29 +82,24 @@ Note that identities do not establish certainty. They just say whether two recor
|
|
|
72
82
|
|
|
73
83
|
### Stop words
|
|
74
84
|
|
|
75
|
-
Ignore common and/or meaningless words
|
|
85
|
+
Ignore common and/or meaningless words when doing string similarity.
|
|
76
86
|
|
|
77
87
|
Adding a stop word like `THE` ensures that it is not taken into account when comparing "THE CAT", "THE DAT", and "THE CATT"
|
|
78
88
|
|
|
79
|
-
|
|
80
|
-
|
|
81
|
-
Strip strings down to the essentials. Applied after stop words.
|
|
82
|
-
|
|
83
|
-
Adding a normalizer like `/(boeing).*(7\d\d)/i` will cause "BOEING COMPANY 747" and "boeing747" to be normalized to "BOEING 747" and "boeing 747", respectively. Since things are generally downcased before they are compared, these would be an exact match.
|
|
89
|
+
Stop words are NOT removed when checking `:must_match_at_least_one_word` and when doing identities and groupings.
|
|
84
90
|
|
|
85
91
|
## Find options
|
|
86
92
|
|
|
87
93
|
* `read`: how to interpret each record in the 'haystack', either a Proc or a symbol
|
|
88
94
|
* `must_match_grouping`: don't return a match unless the needle fits into one of the groupings you specified
|
|
89
95
|
* `must_match_at_least_one_word`: don't return a match unless the needle shares at least one word with the match. Note that "Foo's" is treated like one word (so that it won't match "'s") and "Bolivia," is treated as just "bolivia"
|
|
90
|
-
* `first_grouping_decides`: force records into the first grouping they match, rather than choosing a grouping that will give them a higher score
|
|
91
96
|
* `gather_last_result`: enable `last_result`
|
|
92
97
|
|
|
93
98
|
## Case sensitivity
|
|
94
99
|
|
|
95
100
|
String similarity is case-insensitive. Everything is downcased before scoring. This is a change from previous versions.
|
|
96
101
|
|
|
97
|
-
Be careful
|
|
102
|
+
Be careful with uppercase letters in your rules; in general, things are downcased before comparing.
|
|
98
103
|
|
|
99
104
|
## String similarity algorithm
|
|
100
105
|
|
|
@@ -152,6 +157,21 @@ You can optionally use [`amatch`](http://flori.github.com/amatch/) by [Florian F
|
|
|
152
157
|
|
|
153
158
|
Otherwise, pure ruby versions of the string similarity algorithms derived from the [answer to a StackOverflow question](http://stackoverflow.com/questions/653157/a-better-similarity-ranking-algorithm-for-variable-length-strings) and [the text gem](https://github.com/threedaymonk/text/blob/master/lib/text/levenshtein.rb) are used. Thanks [marzagao](http://stackoverflow.com/users/10997/marzagao) and [threedaymonk](https://github.com/threedaymonk)!
|
|
154
159
|
|
|
160
|
+
## Real-world usage
|
|
161
|
+
|
|
162
|
+
<p><a href="http://brighterplanet.com"><img src="https://s3.amazonaws.com/static.brighterplanet.com/assets/logos/flush-left/inline/green/rasterized/brighter_planet-160-transparent.png" alt="Brighter Planet logo"/></a></p>
|
|
163
|
+
|
|
164
|
+
We use `fuzzy_match` for [data science at Brighter Planet](http://brighterplanet.com/research) and in production at
|
|
165
|
+
|
|
166
|
+
* [Brighter Planet's impact estimate web service](http://impact.brighterplanet.com)
|
|
167
|
+
* [Brighter Planet's reference data web service](http://data.brighterplanet.com)
|
|
168
|
+
|
|
169
|
+
We often combine it with [`remote_table`](https://github.com/seamusabshere/remote_table) and [`errata`](https://github.com/seamusabshere/errata):
|
|
170
|
+
|
|
171
|
+
- download table with `remote_table`
|
|
172
|
+
- correct serious or repeated errors with `errata`
|
|
173
|
+
- `fuzzy_match` the rest
|
|
174
|
+
|
|
155
175
|
## Authors
|
|
156
176
|
|
|
157
177
|
* Seamus Abshere <seamus@abshere.net>
|
|
@@ -160,4 +180,4 @@ Otherwise, pure ruby versions of the string similarity algorithms derived from t
|
|
|
160
180
|
|
|
161
181
|
## Copyright
|
|
162
182
|
|
|
163
|
-
Copyright
|
|
183
|
+
Copyright 2013 Seamus Abshere
|
data/Rakefile
CHANGED
|
@@ -1,14 +1,5 @@
|
|
|
1
1
|
require 'bundler'
|
|
2
2
|
Bundler::GemHelper.install_tasks
|
|
3
3
|
|
|
4
|
-
require 'rake/testtask'
|
|
5
|
-
Rake::TestTask.new(:test) do |test|
|
|
6
|
-
test.libs << 'lib' << 'test'
|
|
7
|
-
test.pattern = 'test/**/test_*.rb'
|
|
8
|
-
test.verbose = true
|
|
9
|
-
end
|
|
10
|
-
|
|
11
|
-
task :default => :test
|
|
12
|
-
|
|
13
4
|
require 'yard'
|
|
14
5
|
YARD::Rake::YardocTask.new
|
data/bin/fuzzy_match
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
1
|
+
#!/usr/bin/env ruby
|
|
2
|
+
|
|
3
|
+
if File.exist?('Gemfile')
|
|
4
|
+
require 'bundler/setup'
|
|
5
|
+
end
|
|
6
|
+
if ENV['PROFILE'] == 'true'
|
|
7
|
+
require 'perftools'
|
|
8
|
+
end
|
|
9
|
+
# PerfTools::CpuProfiler.start("profile_data") do
|
|
10
|
+
require 'fuzzy_match'
|
|
11
|
+
require 'fuzzy_match/version'
|
|
12
|
+
|
|
13
|
+
require 'active_support/core_ext'
|
|
14
|
+
require 'remote_table'
|
|
15
|
+
require 'thor'
|
|
16
|
+
require 'to_regexp'
|
|
17
|
+
|
|
18
|
+
class FuzzyMatch
|
|
19
|
+
class Cli < ::Thor
|
|
20
|
+
desc :match, "Print out matches between A and B, where A is haystack and B is a bunch of needles."
|
|
21
|
+
method_option :csv, default: false, type: :boolean, desc: "CSV output"
|
|
22
|
+
method_option :a_col, default: 0, type: :string, desc: "Column name in A. Defaults to first column."
|
|
23
|
+
method_option :b_col, default: 0, type: :string, desc: "Column name in B. Defaults to first column."
|
|
24
|
+
method_option :downcase, default: true, type: :boolean, desc: "Whether to downcase everything (except regexes, where you have to do /foo/i)"
|
|
25
|
+
method_option :groupings, default: nil, type: :string, desc: "Spreadsheet with groupings - no headers, multi-part groupings on the same row"
|
|
26
|
+
method_option :rules, default: nil, type: :string, desc: "Spreadsheet with headers: stop_words, identities, find_options. Listing a find_option like must_match_grouping makes it true."
|
|
27
|
+
method_option :explain, default: false, type: :boolean
|
|
28
|
+
method_option :grep, default: nil, type: :string
|
|
29
|
+
method_option :limit, default: 1.0/0, type: :numeric
|
|
30
|
+
def match(a_url, b_url)
|
|
31
|
+
puts "Checking matches using fuzzy_match version #{FuzzyMatch::VERSION}..."
|
|
32
|
+
fz = mkfz a_url
|
|
33
|
+
b = load_b b_url
|
|
34
|
+
if ENV['PROFILE'] == 'true'
|
|
35
|
+
require 'perftools'
|
|
36
|
+
PerfTools::CpuProfiler.start("profile.bin") { report(fz, b) }
|
|
37
|
+
system "pprof.rb --text profile.bin"
|
|
38
|
+
`pprof.rb --gif profile.bin > profile.gif`
|
|
39
|
+
else
|
|
40
|
+
report fz, b
|
|
41
|
+
end
|
|
42
|
+
end
|
|
43
|
+
|
|
44
|
+
private
|
|
45
|
+
|
|
46
|
+
def report(fz, b)
|
|
47
|
+
b.each do |b_val|
|
|
48
|
+
if options.explain
|
|
49
|
+
fz.explain
|
|
50
|
+
else
|
|
51
|
+
a_val = fz.find b_val
|
|
52
|
+
if options.csv
|
|
53
|
+
# puts [ b_val.ljust(50), a_val ].join('-> ')
|
|
54
|
+
puts [ b_val, a_val ].to_csv
|
|
55
|
+
else
|
|
56
|
+
puts %{\nB: #{b_val}\nA: #{a_val}}
|
|
57
|
+
end
|
|
58
|
+
end
|
|
59
|
+
end
|
|
60
|
+
end
|
|
61
|
+
|
|
62
|
+
def load_b(b_url)
|
|
63
|
+
b_options = options.b_col.is_a?(String) ? { headers: :first_row } : { headers: false }
|
|
64
|
+
if options[:grep]
|
|
65
|
+
regexp = options[:grep].to_regexp(detect: true)
|
|
66
|
+
b_options[:select] = lambda { |row| regexp =~ row[options.b_col] }
|
|
67
|
+
end
|
|
68
|
+
b = RemoteTable.new(b_url, b_options).to_a
|
|
69
|
+
limit = [options.limit, b.length].min
|
|
70
|
+
b.first(limit).map do |row|
|
|
71
|
+
b_val = row[options.b_col]
|
|
72
|
+
b_val.downcase! if options.downcase
|
|
73
|
+
b_val
|
|
74
|
+
end
|
|
75
|
+
end
|
|
76
|
+
|
|
77
|
+
def mkfz(a_url)
|
|
78
|
+
a_options = options.a_col.is_a?(String) ? { headers: :first_row } : { headers: false }
|
|
79
|
+
a = RemoteTable.new(a_url, a_options).map { |row| row[options.a_col] }
|
|
80
|
+
a.map!(&:downcase) if options.downcase
|
|
81
|
+
FuzzyMatch.new a, fz_options
|
|
82
|
+
end
|
|
83
|
+
|
|
84
|
+
def fz_options
|
|
85
|
+
memo = {}
|
|
86
|
+
if options.groupings
|
|
87
|
+
memo[:groupings] = RemoteTable.new(options.groupings, headers: false).map do |row|
|
|
88
|
+
row.to_a.select(&:present?).map { |v| v.to_regexp(detect: true) }
|
|
89
|
+
end
|
|
90
|
+
end
|
|
91
|
+
if options.rules
|
|
92
|
+
t = RemoteTable.new(options.rules, headers: :first_row)
|
|
93
|
+
find_options = t.rows.map { |row| row['find_options'] }
|
|
94
|
+
memo.merge!(
|
|
95
|
+
identities: t.rows.map { |row| row['identities'] }.select(&:present?).map { |v| v.to_regexp(detect: true) },
|
|
96
|
+
stop_words: t.rows.map { |row| row['stop_words'] }.select(&:present?).map { |v| v.to_regexp(detect: true) },
|
|
97
|
+
must_match_grouping: find_options.include?('must_match_grouping'),
|
|
98
|
+
must_match_at_least_one_word: find_options.include?('must_match_at_least_one_word'),
|
|
99
|
+
)
|
|
100
|
+
end
|
|
101
|
+
memo
|
|
102
|
+
end
|
|
103
|
+
end
|
|
104
|
+
end
|
|
105
|
+
|
|
106
|
+
FuzzyMatch::Cli.start
|
data/fuzzy_match.gemspec
CHANGED
|
@@ -21,14 +21,14 @@ Gem::Specification.new do |s|
|
|
|
21
21
|
s.add_development_dependency 'active_record_inline_schema', '>=0.4.0'
|
|
22
22
|
|
|
23
23
|
# development dependencies
|
|
24
|
-
s.add_development_dependency
|
|
24
|
+
s.add_development_dependency 'pry'
|
|
25
|
+
s.add_development_dependency 'rspec-core'
|
|
26
|
+
s.add_development_dependency 'rspec-expectations'
|
|
27
|
+
s.add_development_dependency 'rspec-mocks'
|
|
25
28
|
s.add_development_dependency 'activerecord', '>=3'
|
|
26
29
|
s.add_development_dependency 'mysql2'
|
|
27
30
|
s.add_development_dependency 'cohort_analysis'
|
|
28
31
|
s.add_development_dependency 'weighted_average'
|
|
29
32
|
s.add_development_dependency 'yard'
|
|
30
33
|
s.add_development_dependency 'amatch'
|
|
31
|
-
if RUBY_VERSION >= '1.9'
|
|
32
|
-
s.add_development_dependency 'minitest-reporters'
|
|
33
|
-
end
|
|
34
34
|
end
|
|
Binary file
|
data/highlevel.graffle
ADDED
|
Binary file
|
data/highlevel.png
ADDED
|
Binary file
|
|
@@ -0,0 +1,58 @@
|
|
|
1
|
+
class FuzzyMatch
|
|
2
|
+
# Records are the tokens that are passed around when doing scoring and optimizing.
|
|
3
|
+
class Record #:nodoc: all
|
|
4
|
+
# "Foo's" is one word
|
|
5
|
+
# "North-west" is just one word
|
|
6
|
+
# "Bolivia," is just Bolivia
|
|
7
|
+
WORD_BOUNDARY = %r{\W*(?:\s+|$)}
|
|
8
|
+
EMPTY = [].freeze
|
|
9
|
+
BLANK = ''.freeze
|
|
10
|
+
|
|
11
|
+
attr_reader :original
|
|
12
|
+
attr_reader :read
|
|
13
|
+
attr_reader :stop_words
|
|
14
|
+
|
|
15
|
+
def initialize(original, options = {})
|
|
16
|
+
@original = original
|
|
17
|
+
@read = options[:read]
|
|
18
|
+
@stop_words = options.fetch(:stop_words, EMPTY)
|
|
19
|
+
end
|
|
20
|
+
|
|
21
|
+
def inspect
|
|
22
|
+
"w(#{clean.inspect})"
|
|
23
|
+
end
|
|
24
|
+
|
|
25
|
+
def clean
|
|
26
|
+
@clean ||= begin
|
|
27
|
+
memo = whole.dup
|
|
28
|
+
stop_words.each do |stop_word|
|
|
29
|
+
memo.gsub! stop_word, BLANK
|
|
30
|
+
end
|
|
31
|
+
memo.strip.freeze
|
|
32
|
+
end
|
|
33
|
+
end
|
|
34
|
+
|
|
35
|
+
def words
|
|
36
|
+
@words ||= clean.downcase.split(WORD_BOUNDARY).freeze
|
|
37
|
+
end
|
|
38
|
+
|
|
39
|
+
def similarity(other)
|
|
40
|
+
Similarity.new self, other
|
|
41
|
+
end
|
|
42
|
+
|
|
43
|
+
def whole
|
|
44
|
+
@whole ||= case read
|
|
45
|
+
when ::NilClass
|
|
46
|
+
original
|
|
47
|
+
when ::Numeric, ::String
|
|
48
|
+
original[read]
|
|
49
|
+
when ::Proc
|
|
50
|
+
read.call original
|
|
51
|
+
when ::Symbol
|
|
52
|
+
original.respond_to?(read) ? original.send(read) : original[read]
|
|
53
|
+
else
|
|
54
|
+
raise "Expected nil, a proc, or a symbol, got #{read.inspect}"
|
|
55
|
+
end.to_s.strip.freeze
|
|
56
|
+
end
|
|
57
|
+
end
|
|
58
|
+
end
|
data/lib/fuzzy_match/result.rb
CHANGED
|
@@ -1,19 +1,23 @@
|
|
|
1
|
+
# encoding: utf-8
|
|
1
2
|
require 'erb'
|
|
3
|
+
require 'pp'
|
|
2
4
|
|
|
3
5
|
class FuzzyMatch
|
|
4
6
|
class Result #:nodoc: all
|
|
5
7
|
EXPLANATION = <<-ERB
|
|
6
|
-
|
|
8
|
+
#####################################################
|
|
9
|
+
# SUMMARY
|
|
10
|
+
#####################################################
|
|
7
11
|
|
|
8
|
-
|
|
12
|
+
Needle: <%= needle.inspect %>
|
|
13
|
+
Match: <%= winner.inspect %>
|
|
9
14
|
|
|
10
|
-
|
|
15
|
+
#####################################################
|
|
16
|
+
# OPTIONS
|
|
17
|
+
#####################################################
|
|
11
18
|
|
|
12
|
-
|
|
19
|
+
<%= PP.pp(options, '') %>
|
|
13
20
|
|
|
14
|
-
The haystack contained <%= haystack.length %> records like <%= haystack[0, 3].map(&:render).map(&:inspect).join(', ') %>
|
|
15
|
-
|
|
16
|
-
# HOW IT WAS MATCHED
|
|
17
21
|
<% timeline.each_with_index do |event, index| %>
|
|
18
22
|
(<%= index+1 %>) <%= event %>
|
|
19
23
|
<% end %>
|
|
@@ -23,7 +27,6 @@ ERB
|
|
|
23
27
|
attr_accessor :read
|
|
24
28
|
attr_accessor :haystack
|
|
25
29
|
attr_accessor :options
|
|
26
|
-
attr_accessor :normalizers
|
|
27
30
|
attr_accessor :groupings
|
|
28
31
|
attr_accessor :identities
|
|
29
32
|
attr_accessor :stop_words
|
|
@@ -1,3 +1,4 @@
|
|
|
1
|
+
# require 'pry'
|
|
1
2
|
class FuzzyMatch
|
|
2
3
|
class Rule
|
|
3
4
|
# "Record linkage typically involves two main steps: grouping and scoring..."
|
|
@@ -8,18 +9,75 @@ class FuzzyMatch
|
|
|
8
9
|
# A grouping (formerly known as a blocking) comes into effect when a str matches.
|
|
9
10
|
# Then the needle must also match the grouping's regexp.
|
|
10
11
|
class Grouping < Rule
|
|
11
|
-
|
|
12
|
-
|
|
13
|
-
|
|
14
|
-
|
|
15
|
-
|
|
16
|
-
|
|
17
|
-
|
|
18
|
-
|
|
19
|
-
|
|
20
|
-
|
|
21
|
-
|
|
22
|
-
|
|
12
|
+
class << self
|
|
13
|
+
def make(regexps)
|
|
14
|
+
case regexps
|
|
15
|
+
when ::Regexp
|
|
16
|
+
new regexps
|
|
17
|
+
when ::Array
|
|
18
|
+
chain = regexps.flatten.map { |regexp| new regexp }
|
|
19
|
+
if chain.length == 1
|
|
20
|
+
chain[0] # not really a chain after all
|
|
21
|
+
else
|
|
22
|
+
chain.each { |grouping| grouping.chain = chain }
|
|
23
|
+
chain
|
|
24
|
+
end
|
|
25
|
+
else
|
|
26
|
+
raise ArgumentError, "[fuzzy_match] Groupings should be specified as single regexps or an array of regexps (got #{regexps.inspect})"
|
|
27
|
+
end
|
|
28
|
+
end
|
|
29
|
+
end
|
|
30
|
+
|
|
31
|
+
attr_accessor :chain
|
|
32
|
+
|
|
33
|
+
def inspect
|
|
34
|
+
memo = []
|
|
35
|
+
memo << "#{regexp.inspect}"
|
|
36
|
+
if chain
|
|
37
|
+
memo << "(#{chain.find_index(self)} of #{chain.length})"
|
|
38
|
+
end
|
|
39
|
+
memo.join ' '
|
|
40
|
+
end
|
|
41
|
+
|
|
42
|
+
def xmatch?(record)
|
|
43
|
+
if primary?
|
|
44
|
+
match?(record) and subs.none? { |sub| sub.match?(record) }
|
|
45
|
+
else
|
|
46
|
+
match?(record) and primary.match?(record)
|
|
47
|
+
end
|
|
48
|
+
end
|
|
49
|
+
|
|
50
|
+
def xjoin?(needle, straw)
|
|
51
|
+
if primary?
|
|
52
|
+
join?(needle, straw) and subs.none? { |sub| sub.match?(straw) } # maybe xmatch here?
|
|
53
|
+
else
|
|
54
|
+
join?(needle, straw) and primary.match?(straw)
|
|
55
|
+
end
|
|
56
|
+
end
|
|
57
|
+
|
|
58
|
+
protected
|
|
59
|
+
|
|
60
|
+
def primary?
|
|
61
|
+
chain ? (primary == self) : true
|
|
62
|
+
# not chain or primary == self
|
|
63
|
+
end
|
|
64
|
+
|
|
65
|
+
def primary
|
|
66
|
+
chain ? chain[0] : self
|
|
67
|
+
end
|
|
68
|
+
|
|
69
|
+
def subs
|
|
70
|
+
chain ? chain[1..-1] : []
|
|
71
|
+
end
|
|
72
|
+
|
|
73
|
+
def match?(record)
|
|
74
|
+
!!(regexp.match(record.whole))
|
|
75
|
+
end
|
|
76
|
+
|
|
77
|
+
def join?(needle, straw)
|
|
78
|
+
if straw_match_data = regexp.match(straw.whole)
|
|
79
|
+
if needle_match_data = regexp.match(needle.whole)
|
|
80
|
+
straw_match_data.captures.join.downcase == needle_match_data.captures.join.downcase
|
|
23
81
|
else
|
|
24
82
|
false
|
|
25
83
|
end
|
|
@@ -7,9 +7,9 @@ class FuzzyMatch
|
|
|
7
7
|
#
|
|
8
8
|
# Only returns true/false if both strings match the regexp.
|
|
9
9
|
# Otherwise returns nil.
|
|
10
|
-
def identical?(
|
|
11
|
-
if str1_match_data = regexp.match(
|
|
12
|
-
str1_match_data.captures.join.downcase ==
|
|
10
|
+
def identical?(record1, record2)
|
|
11
|
+
if str1_match_data = regexp.match(record1.whole) and str2_match_data = regexp.match(record2.whole)
|
|
12
|
+
str1_match_data.captures.join.downcase == str2_match_data.captures.join.downcase
|
|
13
13
|
else
|
|
14
14
|
nil
|
|
15
15
|
end
|
data/lib/fuzzy_match/rule.rb
CHANGED
|
@@ -3,10 +3,6 @@ class FuzzyMatch
|
|
|
3
3
|
# be sure to `require 'amatch'` before you use this class
|
|
4
4
|
class Amatch < Score
|
|
5
5
|
|
|
6
|
-
def inspect
|
|
7
|
-
%{#<FuzzyMatch::Score::Amatch: str1=#{str1.inspect} str2=#{str2.inspect} dices_coefficient_similar=#{dices_coefficient_similar} levenshtein_similar=#{levenshtein_similar}>}
|
|
8
|
-
end
|
|
9
|
-
|
|
10
6
|
def dices_coefficient_similar
|
|
11
7
|
@dices_coefficient_similar ||= if str1 == str2
|
|
12
8
|
1.0
|
|
@@ -4,10 +4,6 @@ class FuzzyMatch
|
|
|
4
4
|
|
|
5
5
|
SPACE = ' '
|
|
6
6
|
|
|
7
|
-
def inspect
|
|
8
|
-
%{#<FuzzyMatch::Score::PureRuby: str1=#{str1.inspect} str2=#{str2.inspect} dices_coefficient_similar=#{dices_coefficient_similar} levenshtein_similar=#{levenshtein_similar}>}
|
|
9
|
-
end
|
|
10
|
-
|
|
11
7
|
# http://stackoverflow.com/questions/653157/a-better-similarity-ranking-algorithm-for-variable-length-strings
|
|
12
8
|
def dices_coefficient_similar
|
|
13
9
|
@dices_coefficient_similar ||= begin
|
|
@@ -90,10 +86,8 @@ class FuzzyMatch
|
|
|
90
86
|
private
|
|
91
87
|
|
|
92
88
|
def utf8?
|
|
93
|
-
return @utf8_query
|
|
94
|
-
utf8_query = (defined?(::Encoding) ? str1.encoding.to_s : $KCODE).downcase.start_with?('u')
|
|
95
|
-
@utf8_query = [utf8_query]
|
|
96
|
-
utf8_query
|
|
89
|
+
return @utf8_query if defined?(@utf8_query)
|
|
90
|
+
@utf8_query = (defined?(::Encoding) ? str1.encoding.to_s : $KCODE).downcase.start_with?('u')
|
|
97
91
|
end
|
|
98
92
|
end
|
|
99
93
|
end
|
data/lib/fuzzy_match/score.rb
CHANGED
|
@@ -13,6 +13,10 @@ class FuzzyMatch
|
|
|
13
13
|
@str2 = str2.downcase
|
|
14
14
|
end
|
|
15
15
|
|
|
16
|
+
def inspect
|
|
17
|
+
%{(dice=#{"%0.5f" % dices_coefficient_similar},lev=#{"%0.5f" % levenshtein_similar})}
|
|
18
|
+
end
|
|
19
|
+
|
|
16
20
|
def <=>(other)
|
|
17
21
|
a = dices_coefficient_similar
|
|
18
22
|
b = other.dices_coefficient_similar
|