creepy-crawler 1.0.0
This diff represents the content of publicly available package versions that have been released to one of the supported registries. The information contained in this diff is provided for informational purposes only and reflects changes between package versions as they appear in their respective public registries.
- checksums.yaml +15 -0
- data/.gitignore +1 -0
- data/.travis.yml +5 -0
- data/DOCKER.md +34 -0
- data/Gemfile +2 -0
- data/Gemfile.lock +53 -0
- data/README.md +97 -0
- data/Rakefile +6 -0
- data/docker/Dockerfile +33 -0
- data/docker/neo4j-server.properties +91 -0
- data/docker/startup.sh +15 -0
- data/examples/crawl.rb +10 -0
- data/examples/output_map.png +0 -0
- data/lib/creepy-crawler.rb +61 -0
- data/lib/creepy-crawler/graph.rb +31 -0
- data/lib/creepy-crawler/page.rb +68 -0
- data/lib/creepy-crawler/site.rb +115 -0
- data/spec/creepy-crawler_spec.rb +17 -0
- data/spec/dummypage_helper.rb +13 -0
- data/spec/graph_spec.rb +67 -0
- data/spec/page_spec.rb +95 -0
- data/spec/site_spec.rb +119 -0
- data/spec/spec_helper.rb +4 -0
- metadata +236 -0
checksums.yaml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
1
|
+
---
|
|
2
|
+
!binary "U0hBMQ==":
|
|
3
|
+
metadata.gz: !binary |-
|
|
4
|
+
MGQ0ZWRlNjU1NjljMGU5MmI3YWQ4YmU3OTJiNTRkOWU2MTE5YTEzYQ==
|
|
5
|
+
data.tar.gz: !binary |-
|
|
6
|
+
MDNkZGI0ZjUxOTliYmY0MzJmNzBkZjgyMzEyMzYzZTVkZDg1MTY3OA==
|
|
7
|
+
SHA512:
|
|
8
|
+
metadata.gz: !binary |-
|
|
9
|
+
MDlmMjk0MDNhMGI4NDg5YzkyOGM4YzQ5YjgyMWE2YjljYTBlZjgyMmI5NDBi
|
|
10
|
+
MTdjOTNjOGZkYzcyMDE2ZmNhOGM5NmVmYWYzYTY4MTI4OTA0YThjMWE5Mjhh
|
|
11
|
+
ZTkxZTNkYzI3MTdhMmYwOTM4MmIzODhkZDA4YmM5ODdjYjZjM2Y=
|
|
12
|
+
data.tar.gz: !binary |-
|
|
13
|
+
ZmEyYzdhYjc3ZjgwNTdjM2EwN2MwOGFjNjFhZGUxZmQyZDhlY2UxNTk1MWNk
|
|
14
|
+
NWZkMmRlMDFhMGRjYjdmOWVlMGEwODgwOTJiMDhjZGM1OTkzMDM5MzRjNTQ5
|
|
15
|
+
ZWY1N2RiMjM1OGU1YjU3YWNmMTUyNzY3ODQ0NDdiMWNhNjc1NmM=
|
data/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
1
|
+
neo4j/
|
data/.travis.yml
ADDED
data/DOCKER.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
1
|
+
creepy-crawler - containerized
|
|
2
|
+
==============
|
|
3
|
+
|
|
4
|
+
I have containerized creepy-crawler using [Docker](http://docker.io) for testing, portability and because Docker is awesome
|
|
5
|
+
|
|
6
|
+
|
|
7
|
+
##Installation
|
|
8
|
+
####Clone
|
|
9
|
+
git clone https://github.com/udryan10/creepy-crawler.git
|
|
10
|
+
####Build docker image
|
|
11
|
+
cd creepy-crawler/docker/ && docker build -t "creepy-crawler:1.0" .
|
|
12
|
+
##Run
|
|
13
|
+
# map neo4j's web interface port 7474 in the container to the host port 7474 for access
|
|
14
|
+
docker run -i -p 7474:7474 creepy-crawler:1.0
|
|
15
|
+
|
|
16
|
+
It takes a bit of time for crawling information to be displayed to stdout when running in docker.
|
|
17
|
+
|
|
18
|
+
##Output
|
|
19
|
+
creepy-crawler uses neo4j graph database to store and display the site map. When the crawl is complete, the docker container is set to loop indefinitley to provide access to the graph data. If we don't do this, the container will shut down and the data will not be accessible
|
|
20
|
+
|
|
21
|
+
### Web interface
|
|
22
|
+
View crawl data, stored in neo4j running inside of the container at: <code>http://\<docker_host\>:7474/webadmin</code>
|
|
23
|
+
|
|
24
|
+
Instructions on how to get to the graph data exist in the [README](https://github.com/udryan10/creepy-crawler#web-interface)
|
|
25
|
+
|
|
26
|
+
###boot2docker
|
|
27
|
+
If you are running docker on a mac using boot2docker, you will have to instruct virtual box to forward the correct port to the docker host:
|
|
28
|
+
|
|
29
|
+
VBoxManage modifyvm "boot2docker-vm" --natpf1 "neo4j,tcp,,7474,,7474"
|
|
30
|
+
|
|
31
|
+
##Stopping
|
|
32
|
+
docker stop <container id>
|
|
33
|
+
|
|
34
|
+
**Plans to add additional documentation for those less familiar with Docker
|
data/Gemfile
ADDED
data/Gemfile.lock
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
1
|
+
PATH
|
|
2
|
+
remote: .
|
|
3
|
+
specs:
|
|
4
|
+
creepy-crawler (1.0.0)
|
|
5
|
+
addressable (~> 2.3, >= 2.3.6)
|
|
6
|
+
neography (~> 1.4, >= 1.4.1)
|
|
7
|
+
nokogiri (~> 1.6, >= 1.6.1)
|
|
8
|
+
open_uri_redirections (= 0.1.4)
|
|
9
|
+
rake (~> 0.8)
|
|
10
|
+
trollop (~> 2.0)
|
|
11
|
+
webrobots (~> 0.1, >= 0.1.1)
|
|
12
|
+
|
|
13
|
+
GEM
|
|
14
|
+
remote: http://rubygems.org/
|
|
15
|
+
specs:
|
|
16
|
+
addressable (2.3.6)
|
|
17
|
+
diff-lcs (1.2.5)
|
|
18
|
+
httpclient (2.3.4.1)
|
|
19
|
+
json (1.8.1)
|
|
20
|
+
mini_portile (0.5.3)
|
|
21
|
+
multi_json (1.9.3)
|
|
22
|
+
neography (1.4.1)
|
|
23
|
+
httpclient (>= 2.3.3)
|
|
24
|
+
json (>= 1.7.7)
|
|
25
|
+
multi_json (>= 1.3.2)
|
|
26
|
+
os (>= 0.9.6)
|
|
27
|
+
rake (>= 0.8.7)
|
|
28
|
+
rubyzip (>= 1.0.0)
|
|
29
|
+
nokogiri (1.6.1)
|
|
30
|
+
mini_portile (~> 0.5.0)
|
|
31
|
+
open_uri_redirections (0.1.4)
|
|
32
|
+
os (0.9.6)
|
|
33
|
+
rake (0.9.2.2)
|
|
34
|
+
rspec (2.14.1)
|
|
35
|
+
rspec-core (~> 2.14.0)
|
|
36
|
+
rspec-expectations (~> 2.14.0)
|
|
37
|
+
rspec-mocks (~> 2.14.0)
|
|
38
|
+
rspec-core (2.14.8)
|
|
39
|
+
rspec-expectations (2.14.5)
|
|
40
|
+
diff-lcs (>= 1.1.3, < 2.0)
|
|
41
|
+
rspec-mocks (2.14.6)
|
|
42
|
+
rubyzip (1.1.3)
|
|
43
|
+
trollop (2.0)
|
|
44
|
+
webrobots (0.1.1)
|
|
45
|
+
|
|
46
|
+
PLATFORMS
|
|
47
|
+
ruby
|
|
48
|
+
|
|
49
|
+
DEPENDENCIES
|
|
50
|
+
bundler (~> 1.5)
|
|
51
|
+
creepy-crawler!
|
|
52
|
+
rspec (~> 2.14)
|
|
53
|
+
rspec-core (~> 2.14)
|
data/README.md
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
1
|
+
creepy-crawler
|
|
2
|
+
==============
|
|
3
|
+
|
|
4
|
+
Ruby web crawler that takes a url as input and produces a sitemap using a neo4j graph database - Nothing creepy about it.
|
|
5
|
+
|
|
6
|
+
[](https://travis-ci.org/udryan10/creepy-crawler)
|
|
7
|
+
|
|
8
|
+
|
|
9
|
+
##Installation
|
|
10
|
+
####Clone
|
|
11
|
+
git clone https://github.com/udryan10/creepy-crawler.git
|
|
12
|
+
####Install Required Gems
|
|
13
|
+
bundle install
|
|
14
|
+
####Install graph database
|
|
15
|
+
rake neo4j:install
|
|
16
|
+
####Start graph database
|
|
17
|
+
rake neo4j:start
|
|
18
|
+
|
|
19
|
+
####Requirements
|
|
20
|
+
1. Gems listed in Gemfile
|
|
21
|
+
2. Ruby 1.9+
|
|
22
|
+
3. neo4j
|
|
23
|
+
3. Oracle jdk7 (for neo4j graphing database)
|
|
24
|
+
4. lsof (for neo4j graphing database)
|
|
25
|
+
|
|
26
|
+
##Usage
|
|
27
|
+
###Code
|
|
28
|
+
####Require
|
|
29
|
+
require './creepy-crawler'
|
|
30
|
+
####Start a crawl
|
|
31
|
+
Creepycrawler.crawl("http://example.com")
|
|
32
|
+
####Limit number of pages to crawl
|
|
33
|
+
Creepycrawler.crawl("http://example.com", :max_page_crawl => 500)
|
|
34
|
+
####Extract some (potentially) useful statistics
|
|
35
|
+
crawler = Creepycrawler.crawl("http://example.com", :max_page_crawl => 500)
|
|
36
|
+
# list of broken links
|
|
37
|
+
puts crawler.broken_links
|
|
38
|
+
# list of sites that were visited
|
|
39
|
+
puts crawler.visited_queue
|
|
40
|
+
# count of crawled pages
|
|
41
|
+
puts crawler.page_crawl_count
|
|
42
|
+
|
|
43
|
+
####Options
|
|
44
|
+
DEFAULT_OPTIONS = {
|
|
45
|
+
# whether to print crawling information
|
|
46
|
+
:verbose => true,
|
|
47
|
+
# whether to obey robots.txt
|
|
48
|
+
:obey_robots => true,
|
|
49
|
+
# maximum number of pages to crawl, value of nil will attempt to crawl all pages
|
|
50
|
+
:max_page_crawl => nil,
|
|
51
|
+
# should pages be written to the database. Likely only used for testing, but may be used if you only wanted to get at the broken_links data
|
|
52
|
+
:graph_to_neo4j => true
|
|
53
|
+
}
|
|
54
|
+
|
|
55
|
+
####Example
|
|
56
|
+
examples located in <code>examples/</code> directory
|
|
57
|
+
|
|
58
|
+
###Command line
|
|
59
|
+
# Crawl site
|
|
60
|
+
ruby creepy-crawler.rb --site "http://google.com"
|
|
61
|
+
# Get command options
|
|
62
|
+
ruby creepy-crawler.rb --help
|
|
63
|
+
|
|
64
|
+
**Note:** If behind a proxy, export your proxy environment variables
|
|
65
|
+
|
|
66
|
+
export http_proxy=<proxy_host>; export https_proxy=<proxy_host>
|
|
67
|
+
|
|
68
|
+
###Docker
|
|
69
|
+
For testing, I have included the ability to run the environment and a crawl inside of a [docker container](https://github.com/udryan10/creepy-crawler/blob/master/DOCKER.md)
|
|
70
|
+
|
|
71
|
+
##Output
|
|
72
|
+
creepy-crawler uses [neo4j](http://www.neo4j.org/) graph database to store and display the site map.
|
|
73
|
+
|
|
74
|
+
### Web interface
|
|
75
|
+
neo4j has a web interface for viewing and interacting with the graph data. When running on local host, visit: [http://localhost:7474/webadmin/](http://localhost:7474/webadmin/)
|
|
76
|
+
|
|
77
|
+
1. Click the Data Browser tab
|
|
78
|
+
2. Enter Query to search for nodes (will search all nodes):
|
|
79
|
+
|
|
80
|
+
<code>
|
|
81
|
+
START root=node(*)
|
|
82
|
+
RETURN root
|
|
83
|
+
</code>
|
|
84
|
+
|
|
85
|
+
3. Click into a node
|
|
86
|
+
4. Click switch view mode at top right to view a graphical map
|
|
87
|
+
|
|
88
|
+
**Note:** to have the map display url names instead of node numbers, you must create a style
|
|
89
|
+
### REST interface
|
|
90
|
+
neo4j also has a full [REST API](http://docs.neo4j.org/chunked/stable/rest-api.html) for programatic access to the data
|
|
91
|
+
|
|
92
|
+
###Example Output Map
|
|
93
|
+
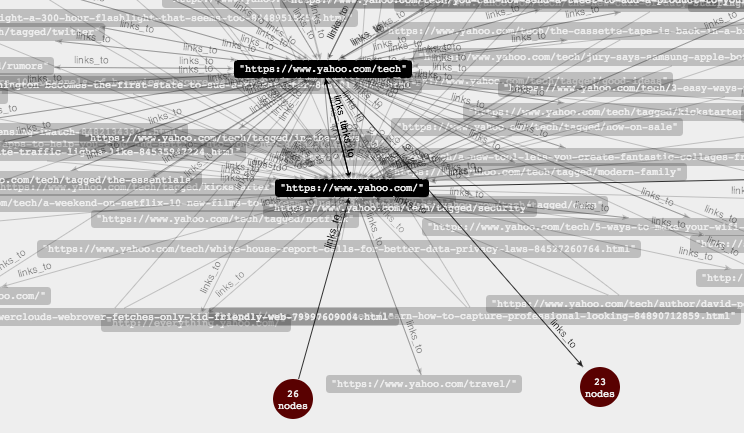
|
|
94
|
+
|
|
95
|
+
##TODO
|
|
96
|
+
1. convert to gem
|
|
97
|
+
2. multi-threaded to increase crawl performance
|
data/Rakefile
ADDED
data/docker/Dockerfile
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
1
|
+
FROM ubuntu:latest
|
|
2
|
+
|
|
3
|
+
MAINTAINER Ryan Grothouse <rgrothouse@gmail.com>
|
|
4
|
+
|
|
5
|
+
ENV DEBIAN_FRONTEND noninteractive
|
|
6
|
+
ENV NOKOGIRI_USE_SYSTEM_LIBRARIES 1
|
|
7
|
+
|
|
8
|
+
RUN apt-get -q update
|
|
9
|
+
RUN apt-get -y upgrade
|
|
10
|
+
|
|
11
|
+
# Nokogiri dependencies
|
|
12
|
+
RUN apt-get install -qy --force-yes git ruby ruby-dev build-essential
|
|
13
|
+
RUN apt-get install -qy libxslt1-dev libxml2-dev libssl-dev libyaml-dev
|
|
14
|
+
RUN apt-get install -qy --no-install-recommends openjdk-7-jdk openjdk-7-jre
|
|
15
|
+
|
|
16
|
+
# Neo4j dependencies
|
|
17
|
+
RUN apt-get install -qy curl lsof
|
|
18
|
+
|
|
19
|
+
RUN gem install bundler
|
|
20
|
+
|
|
21
|
+
RUN git clone https://github.com/udryan10/creepy-crawler /opt/creepy-crawler
|
|
22
|
+
WORKDIR /opt/creepy-crawler
|
|
23
|
+
|
|
24
|
+
RUN bundle install
|
|
25
|
+
RUN rake neo4j:install
|
|
26
|
+
|
|
27
|
+
ADD ./startup.sh /startup.sh
|
|
28
|
+
ADD ./neo4j-server.properties /opt/creepy-crawler/neo4j/conf/neo4j-server.properties
|
|
29
|
+
RUN chmod u+x /startup.sh
|
|
30
|
+
|
|
31
|
+
EXPOSE 7474
|
|
32
|
+
|
|
33
|
+
ENTRYPOINT ["/startup.sh"]
|
|
@@ -0,0 +1,91 @@
|
|
|
1
|
+
################################################################
|
|
2
|
+
# Neo4j configuration
|
|
3
|
+
#
|
|
4
|
+
################################################################
|
|
5
|
+
|
|
6
|
+
#***************************************************************
|
|
7
|
+
# Server configuration
|
|
8
|
+
#***************************************************************
|
|
9
|
+
|
|
10
|
+
# location of the database directory
|
|
11
|
+
org.neo4j.server.database.location=data/graph.db
|
|
12
|
+
|
|
13
|
+
# Let the webserver only listen on the specified IP. Default is localhost (only
|
|
14
|
+
# accept local connections). Uncomment to allow any connection. Please see the
|
|
15
|
+
# security section in the neo4j manual before modifying this.
|
|
16
|
+
org.neo4j.server.webserver.address=0.0.0.0
|
|
17
|
+
|
|
18
|
+
#
|
|
19
|
+
# HTTP Connector
|
|
20
|
+
#
|
|
21
|
+
|
|
22
|
+
# http port (for all data, administrative, and UI access)
|
|
23
|
+
org.neo4j.server.webserver.port=7474
|
|
24
|
+
|
|
25
|
+
#
|
|
26
|
+
# HTTPS Connector
|
|
27
|
+
#
|
|
28
|
+
|
|
29
|
+
# Turn https-support on/off
|
|
30
|
+
org.neo4j.server.webserver.https.enabled=true
|
|
31
|
+
|
|
32
|
+
# https port (for all data, administrative, and UI access)
|
|
33
|
+
org.neo4j.server.webserver.https.port=7473
|
|
34
|
+
|
|
35
|
+
# Certificate location (auto generated if the file does not exist)
|
|
36
|
+
org.neo4j.server.webserver.https.cert.location=conf/ssl/snakeoil.cert
|
|
37
|
+
|
|
38
|
+
# Private key location (auto generated if the file does not exist)
|
|
39
|
+
org.neo4j.server.webserver.https.key.location=conf/ssl/snakeoil.key
|
|
40
|
+
|
|
41
|
+
# Internally generated keystore (don't try to put your own
|
|
42
|
+
# keystore there, it will get deleted when the server starts)
|
|
43
|
+
org.neo4j.server.webserver.https.keystore.location=data/keystore
|
|
44
|
+
|
|
45
|
+
#*****************************************************************
|
|
46
|
+
# Administration client configuration
|
|
47
|
+
#*****************************************************************
|
|
48
|
+
|
|
49
|
+
# location of the servers round-robin database directory. Possible values:
|
|
50
|
+
# - absolute path like /var/rrd
|
|
51
|
+
# - path relative to the server working directory like data/rrd
|
|
52
|
+
# - commented out, will default to the database data directory.
|
|
53
|
+
org.neo4j.server.webadmin.rrdb.location=data/rrd
|
|
54
|
+
|
|
55
|
+
# REST endpoint for the data API
|
|
56
|
+
# Note the / in the end is mandatory
|
|
57
|
+
org.neo4j.server.webadmin.data.uri=/db/data/
|
|
58
|
+
|
|
59
|
+
# REST endpoint of the administration API (used by Webadmin)
|
|
60
|
+
org.neo4j.server.webadmin.management.uri=/db/manage/
|
|
61
|
+
|
|
62
|
+
# Low-level graph engine tuning file
|
|
63
|
+
org.neo4j.server.db.tuning.properties=conf/neo4j.properties
|
|
64
|
+
|
|
65
|
+
# The console services to be enabled
|
|
66
|
+
org.neo4j.server.manage.console_engines=shell
|
|
67
|
+
|
|
68
|
+
|
|
69
|
+
# Comma separated list of JAX-RS packages containing JAX-RS resources, one
|
|
70
|
+
# package name for each mountpoint. The listed package names will be loaded
|
|
71
|
+
# under the mountpoints specified. Uncomment this line to mount the
|
|
72
|
+
# org.neo4j.examples.server.unmanaged.HelloWorldResource.java from
|
|
73
|
+
# neo4j-examples under /examples/unmanaged, resulting in a final URL of
|
|
74
|
+
# http://localhost:7474/examples/unmanaged/helloworld/{nodeId}
|
|
75
|
+
#org.neo4j.server.thirdparty_jaxrs_classes=org.neo4j.examples.server.unmanaged=/examples/unmanaged
|
|
76
|
+
|
|
77
|
+
|
|
78
|
+
#*****************************************************************
|
|
79
|
+
# HTTP logging configuration
|
|
80
|
+
#*****************************************************************
|
|
81
|
+
|
|
82
|
+
# HTTP logging is disabled. HTTP logging can be enabled by setting this
|
|
83
|
+
# property to 'true'.
|
|
84
|
+
org.neo4j.server.http.log.enabled=false
|
|
85
|
+
|
|
86
|
+
# Logging policy file that governs how HTTP log output is presented and
|
|
87
|
+
# archived. Note: changing the rollover and retention policy is sensible, but
|
|
88
|
+
# changing the output format is less so, since it is configured to use the
|
|
89
|
+
# ubiquitous common log format
|
|
90
|
+
org.neo4j.server.http.log.config=conf/neo4j-http-logging.xml
|
|
91
|
+
|
data/docker/startup.sh
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
1
|
+
#!/bin/sh
|
|
2
|
+
|
|
3
|
+
MAX_PAGE_CRAWL=50
|
|
4
|
+
CRAWL_URL="http://www.yahoo.com"
|
|
5
|
+
echo "Crawler is set to crawl ${CRAWL_URL}"
|
|
6
|
+
echo "Crawler is set to crawl ${MAX_PAGE_CRAWL} pages"
|
|
7
|
+
|
|
8
|
+
cd /opt/creepy-crawler && rake neo4j:start
|
|
9
|
+
ruby /opt/creepy-crawler/lib/creepy-crawler.rb --site $CRAWL_URL --max-page-crawl $MAX_PAGE_CRAWL
|
|
10
|
+
echo "==============================================="
|
|
11
|
+
echo "Crawl is complete!"
|
|
12
|
+
echo "To see graph data visit http://<docker_host>:7474/webadmin"
|
|
13
|
+
echo "Sleeping indefinitley to allow graph data to be viewed"
|
|
14
|
+
echo "To stop container execute: docker stop <container id>"
|
|
15
|
+
while true; do sleep 10000; done
|
data/examples/crawl.rb
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
1
|
+
require_relative '../lib/creepy-crawler'
|
|
2
|
+
|
|
3
|
+
crawler = Creepycrawler.crawl("http://yahoo.com", :max_page_crawl => 100)
|
|
4
|
+
puts "=" * 40
|
|
5
|
+
puts "broken link list:"
|
|
6
|
+
puts crawler.broken_links
|
|
7
|
+
puts "=" * 40
|
|
8
|
+
puts "number of visited pages:"
|
|
9
|
+
puts crawler.page_crawl_count
|
|
10
|
+
puts "=" * 40
|
|
Binary file
|
|
@@ -0,0 +1,61 @@
|
|
|
1
|
+
require 'rubygems'
|
|
2
|
+
require 'bundler/setup'
|
|
3
|
+
require 'neography'
|
|
4
|
+
require 'nokogiri'
|
|
5
|
+
require 'open-uri'
|
|
6
|
+
require 'addressable/uri'
|
|
7
|
+
require 'open_uri_redirections'
|
|
8
|
+
require 'webrobots'
|
|
9
|
+
require 'trollop'
|
|
10
|
+
require_relative 'creepy-crawler/site'
|
|
11
|
+
require_relative 'creepy-crawler/page'
|
|
12
|
+
require_relative 'creepy-crawler/graph'
|
|
13
|
+
|
|
14
|
+
module Creepycrawler
|
|
15
|
+
# todo: on my local machine im hitting some openssl bug to where legitimate https sites are not validating the certificate.
|
|
16
|
+
# For now, keeping this to override the verification but need to investigate further and remove this hack.
|
|
17
|
+
OpenSSL::SSL::VERIFY_PEER = OpenSSL::SSL::VERIFY_NONE
|
|
18
|
+
# configure Neography - for now uses all defaults and expects neo4j to be running on localhost
|
|
19
|
+
Neography.configure do |config|
|
|
20
|
+
config.protocol = "http://"
|
|
21
|
+
config.server = "localhost"
|
|
22
|
+
config.port = 7474
|
|
23
|
+
config.directory = "" # prefix this path with '/'
|
|
24
|
+
config.cypher_path = "/cypher"
|
|
25
|
+
config.gremlin_path = "/ext/GremlinPlugin/graphdb/execute_script"
|
|
26
|
+
config.log_file = "neography.log"
|
|
27
|
+
config.log_enabled = false
|
|
28
|
+
config.slow_log_threshold = 0 # time in ms for query logging
|
|
29
|
+
config.max_threads = 20
|
|
30
|
+
config.authentication = nil # 'basic' or 'digest'
|
|
31
|
+
config.username = nil
|
|
32
|
+
config.password = nil
|
|
33
|
+
config.parser = MultiJsonParser
|
|
34
|
+
end
|
|
35
|
+
|
|
36
|
+
# class method to start a crawl
|
|
37
|
+
def Creepycrawler.crawl(url, options = {})
|
|
38
|
+
return Site.new(url, options).crawl
|
|
39
|
+
end
|
|
40
|
+
end
|
|
41
|
+
|
|
42
|
+
|
|
43
|
+
# allow the initiating of a crawl from command line
|
|
44
|
+
if __FILE__==$0
|
|
45
|
+
# setup options
|
|
46
|
+
opts = Trollop::options do
|
|
47
|
+
opt :site, "Url of site to crawl", :type => :string # flag --site
|
|
48
|
+
opt :obey_robots, "Obey robots.txt disallow list" # string --name <s>, default nil
|
|
49
|
+
opt :verbose, "Whether to print crawling information", :default => true
|
|
50
|
+
opt :max_page_crawl, "Maximum number of pages to crawl. Defaults to unlimited", :default => 0
|
|
51
|
+
opt :graph_to_neo4j, "Whether pages should be written to graph database", :default => true
|
|
52
|
+
end
|
|
53
|
+
|
|
54
|
+
Trollop::die :site, "Must specify a site to crawl" unless opts[:site]
|
|
55
|
+
opts[:max_page_crawl] = nil if opts[:max_page_crawl] == 0
|
|
56
|
+
|
|
57
|
+
options_hash = {:obey_robots => opts[:obey_robots], :verbose => opts[:verbose], :max_page_crawl => opts[:max_page_crawl], :graph_to_neo4j => opts[:graph_to_neo4j]}
|
|
58
|
+
|
|
59
|
+
# start crawl
|
|
60
|
+
Creepycrawler.crawl(opts[:site], options_hash)
|
|
61
|
+
end
|
|
@@ -0,0 +1,31 @@
|
|
|
1
|
+
module Creepycrawler
|
|
2
|
+
# Class that takes care of writing to our graph database (neo4j)
|
|
3
|
+
class Graph
|
|
4
|
+
|
|
5
|
+
def initialize
|
|
6
|
+
@neo4j = Neography::Rest.new
|
|
7
|
+
end
|
|
8
|
+
|
|
9
|
+
# add page to graph database
|
|
10
|
+
def add_page(url)
|
|
11
|
+
# if page doesnt exist, add it to neo4j
|
|
12
|
+
begin
|
|
13
|
+
node = @neo4j.get_node_index("page", "url", url)
|
|
14
|
+
rescue Neography::NotFoundException => e
|
|
15
|
+
node = nil
|
|
16
|
+
end
|
|
17
|
+
|
|
18
|
+
# node doesnt exist, create it
|
|
19
|
+
if node.nil?
|
|
20
|
+
node = @neo4j.create_node("url" => url)
|
|
21
|
+
@neo4j.add_node_to_index("page", "url", url, node) unless node.nil?
|
|
22
|
+
end
|
|
23
|
+
|
|
24
|
+
return node
|
|
25
|
+
end
|
|
26
|
+
|
|
27
|
+
def create_relationship(type,from,to)
|
|
28
|
+
@neo4j.create_relationship(type, from, to)
|
|
29
|
+
end
|
|
30
|
+
end
|
|
31
|
+
end
|
|
@@ -0,0 +1,68 @@
|
|
|
1
|
+
module Creepycrawler
|
|
2
|
+
# Represents a webpage and the methods to extract the details we need for our crawler
|
|
3
|
+
class Page
|
|
4
|
+
|
|
5
|
+
# page url
|
|
6
|
+
attr_accessor :url
|
|
7
|
+
# page html
|
|
8
|
+
attr_reader :body
|
|
9
|
+
|
|
10
|
+
def initialize(url)
|
|
11
|
+
@url = Addressable::URI.parse(url).normalize
|
|
12
|
+
@robotstxt = WebRobots.new("CreepyCrawler")
|
|
13
|
+
end
|
|
14
|
+
|
|
15
|
+
def body=(body)
|
|
16
|
+
# convert to Nokogiri object
|
|
17
|
+
@body = Nokogiri::HTML(body)
|
|
18
|
+
end
|
|
19
|
+
|
|
20
|
+
# retrieve page
|
|
21
|
+
def fetch
|
|
22
|
+
@body = Nokogiri::HTML(open(@url, :allow_redirections => :all))
|
|
23
|
+
end
|
|
24
|
+
|
|
25
|
+
# return all links on page
|
|
26
|
+
def links
|
|
27
|
+
# if we haven't fetched the page, get it
|
|
28
|
+
fetch if @body.nil?
|
|
29
|
+
|
|
30
|
+
# using nokogiri, find all anchor elements
|
|
31
|
+
hyperlinks = @body.css('a')
|
|
32
|
+
|
|
33
|
+
# get array of links on page - remove any empty links or links that are invalid
|
|
34
|
+
@links = hyperlinks.map {|link| link.attribute('href').to_s}.uniq.sort.delete_if do |href|
|
|
35
|
+
|
|
36
|
+
# if href is empty, points to an anchor, mailto or ftp delete
|
|
37
|
+
invalid = true if href.empty? or /^#/ =~ href or /^mailto:/ =~ href or /^ftp:/ =~ href or /^javascript:/ =~ href
|
|
38
|
+
|
|
39
|
+
# if Addressable throws an exception, we have an invalid link - delete
|
|
40
|
+
begin
|
|
41
|
+
Addressable::URI.parse(href)
|
|
42
|
+
rescue
|
|
43
|
+
invalid = true
|
|
44
|
+
end
|
|
45
|
+
invalid
|
|
46
|
+
end
|
|
47
|
+
|
|
48
|
+
# map all links to absolute
|
|
49
|
+
@links.map{|link| relative_to_absolute_link(link)}
|
|
50
|
+
end
|
|
51
|
+
|
|
52
|
+
def relative_to_absolute_link(link)
|
|
53
|
+
uri = Addressable::URI.parse(link).normalize
|
|
54
|
+
|
|
55
|
+
# this url was relative, prepend our known domain
|
|
56
|
+
if uri.host.nil?
|
|
57
|
+
return (@url + uri.path).to_s
|
|
58
|
+
else
|
|
59
|
+
# the url was already absolute - leave as is
|
|
60
|
+
return uri.to_s
|
|
61
|
+
end
|
|
62
|
+
end
|
|
63
|
+
|
|
64
|
+
def robots_disallowed?
|
|
65
|
+
return @robotstxt.disallowed?(@url)
|
|
66
|
+
end
|
|
67
|
+
end
|
|
68
|
+
end
|
|
@@ -0,0 +1,115 @@
|
|
|
1
|
+
module Creepycrawler
|
|
2
|
+
# object to handle the discovery of our site through crawling
|
|
3
|
+
class Site
|
|
4
|
+
|
|
5
|
+
# the site domain
|
|
6
|
+
attr_reader :domain
|
|
7
|
+
# url the crawl began with
|
|
8
|
+
attr_reader :url
|
|
9
|
+
# hash of additional options to be passed in
|
|
10
|
+
attr_reader :options
|
|
11
|
+
# queue used to store discovered pages and crawl the site
|
|
12
|
+
attr_reader :crawl_queue
|
|
13
|
+
# queue used to store visited pages
|
|
14
|
+
attr_reader :visited_queue
|
|
15
|
+
# number of pages crawled
|
|
16
|
+
attr_reader :page_crawl_count
|
|
17
|
+
# holds the root node information
|
|
18
|
+
attr_reader :root_node
|
|
19
|
+
# holds dead or broken links
|
|
20
|
+
attr_reader :broken_links
|
|
21
|
+
|
|
22
|
+
DEFAULT_OPTIONS = {
|
|
23
|
+
# whether to print crawling information
|
|
24
|
+
:verbose => true,
|
|
25
|
+
# whether to obey robots.txt
|
|
26
|
+
:obey_robots => true,
|
|
27
|
+
# maximum number of pages to crawl, value of nil will attempt to crawl all pages
|
|
28
|
+
:max_page_crawl => nil,
|
|
29
|
+
# should pages be written to the database. Likely only used for testing, but may be used if you only wanted to get at the broken_links data
|
|
30
|
+
:graph_to_neo4j => true
|
|
31
|
+
}
|
|
32
|
+
|
|
33
|
+
# create setter methods for each default option
|
|
34
|
+
DEFAULT_OPTIONS.keys.each do |option|
|
|
35
|
+
define_method "#{option}=" do |value|
|
|
36
|
+
@options[option.to_sym] = value
|
|
37
|
+
end
|
|
38
|
+
end
|
|
39
|
+
|
|
40
|
+
def initialize(url, options = {})
|
|
41
|
+
response = open(url, :allow_redirections => :all)
|
|
42
|
+
url_parsed = Addressable::URI.parse(response.base_uri)
|
|
43
|
+
@domain = url_parsed.host
|
|
44
|
+
@url = url_parsed.to_s
|
|
45
|
+
@page_crawl_count = 0
|
|
46
|
+
@options = options
|
|
47
|
+
# add the initial url to our crawl queue
|
|
48
|
+
@crawl_queue = [@url]
|
|
49
|
+
@broken_links = []
|
|
50
|
+
@visited_queue = []
|
|
51
|
+
@graph = Creepycrawler::Graph.new
|
|
52
|
+
end
|
|
53
|
+
|
|
54
|
+
def crawl
|
|
55
|
+
# merge default and passed in options into one hash
|
|
56
|
+
@options = DEFAULT_OPTIONS.merge(@options)
|
|
57
|
+
|
|
58
|
+
# begin crawl loop
|
|
59
|
+
loop do
|
|
60
|
+
# break if we have crawled all sites, or reached :max_page_crawl
|
|
61
|
+
break if @crawl_queue.empty? or (!options[:max_page_crawl].nil? and @page_crawl_count >= @options[:max_page_crawl])
|
|
62
|
+
|
|
63
|
+
begin
|
|
64
|
+
# pull next page from crawl_queue and setup page
|
|
65
|
+
page = Page.new(@crawl_queue.shift)
|
|
66
|
+
|
|
67
|
+
# add url to visited queue to keep track of where we have been
|
|
68
|
+
@visited_queue.push(page.url.to_s)
|
|
69
|
+
|
|
70
|
+
# respect robots.txt
|
|
71
|
+
if @options[:obey_robots] and page.robots_disallowed?
|
|
72
|
+
puts "Not crawling #{page.url} per Robots.txt request" if options[:verbose]
|
|
73
|
+
next
|
|
74
|
+
end
|
|
75
|
+
|
|
76
|
+
puts "Crawling and indexing: #{page.url}" if @options[:verbose]
|
|
77
|
+
|
|
78
|
+
# retrieve page
|
|
79
|
+
page.fetch
|
|
80
|
+
|
|
81
|
+
current_page_node = @graph.add_page(page.url) if @options[:graph_to_neo4j]
|
|
82
|
+
#todo: fix this. on first run current_page_node is a hash. subsequent is an array of hashes
|
|
83
|
+
@root_node = current_page_node if @page_crawl_count == 0 and @options[:graph_to_neo4j]
|
|
84
|
+
|
|
85
|
+
# Loop through all links on the current page
|
|
86
|
+
page.links.each do |link|
|
|
87
|
+
|
|
88
|
+
# add to crawl queue - only push local links, links that do not yet exist in the queue and links that haven't been visted
|
|
89
|
+
@crawl_queue.push(link) if local? link and !@crawl_queue.include? link and !@visited_queue.include? link.to_s
|
|
90
|
+
|
|
91
|
+
# add link page to graph
|
|
92
|
+
current_link_node = @graph.add_page(link) if @options[:graph_to_neo4j]
|
|
93
|
+
|
|
94
|
+
# create a links_to relationship from the current page node to link node
|
|
95
|
+
@graph.create_relationship("links_to", current_page_node, current_link_node) if @options[:graph_to_neo4j]
|
|
96
|
+
end
|
|
97
|
+
rescue => e
|
|
98
|
+
puts "Exception thrown: #{e.message} - Skipping Page" if @options[:verbose]
|
|
99
|
+
@broken_links.push(page.url)
|
|
100
|
+
next
|
|
101
|
+
end
|
|
102
|
+
@page_crawl_count += 1
|
|
103
|
+
end # end of loop
|
|
104
|
+
|
|
105
|
+
return self
|
|
106
|
+
end
|
|
107
|
+
|
|
108
|
+
# is link local to site?
|
|
109
|
+
def local?(link)
|
|
110
|
+
uri = Addressable::URI.parse(link)
|
|
111
|
+
return true if uri.host == @domain
|
|
112
|
+
return false
|
|
113
|
+
end
|
|
114
|
+
end
|
|
115
|
+
end
|
|
@@ -0,0 +1,17 @@
|
|
|
1
|
+
require 'spec_helper'
|
|
2
|
+
|
|
3
|
+
module Creepycrawler
|
|
4
|
+
describe Creepycrawler do
|
|
5
|
+
describe "#crawl" do
|
|
6
|
+
it "should have a crawl convenience method to crawl the site and return a Site object" do
|
|
7
|
+
result = Creepycrawler.crawl(RSPEC_URL,:graph_to_neo4j => false, :verbose => false)
|
|
8
|
+
expect(result).to be_an_instance_of Site
|
|
9
|
+
end
|
|
10
|
+
|
|
11
|
+
it "should have a crawl convenience method that accepts options to crawl the site and return a Site object" do
|
|
12
|
+
result = Creepycrawler.crawl(RSPEC_URL, :verbose => false, :graph_to_neo4j => false)
|
|
13
|
+
expect(result).to be_an_instance_of Site
|
|
14
|
+
end
|
|
15
|
+
end
|
|
16
|
+
end
|
|
17
|
+
end
|
data/spec/graph_spec.rb
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
1
|
+
require 'spec_helper'
|
|
2
|
+
|
|
3
|
+
module Creepycrawler
|
|
4
|
+
describe Graph do
|
|
5
|
+
|
|
6
|
+
describe "#new" do
|
|
7
|
+
|
|
8
|
+
it "should return a Graph object" do
|
|
9
|
+
expect(Graph.new).to be_an_instance_of(Creepycrawler::Graph)
|
|
10
|
+
end
|
|
11
|
+
end
|
|
12
|
+
|
|
13
|
+
describe "#add_page" do
|
|
14
|
+
|
|
15
|
+
it "should create a node if the node doesnt exist in the graph (returning nil)" do
|
|
16
|
+
# mock out Neography::Rest object to allow us to return desired data
|
|
17
|
+
neography = double(Neography::Rest, :get_node_index => nil, :create_node => [], :add_node_to_index => {})
|
|
18
|
+
allow(Neography::Rest).to receive(:new) {neography}
|
|
19
|
+
expect(neography).to receive(:get_node_index).with("page","url",RSPEC_URL)
|
|
20
|
+
expect(neography).to receive(:create_node).with({"url" => RSPEC_URL})
|
|
21
|
+
expect(neography).to receive(:add_node_to_index).with("page","url",RSPEC_URL,an_instance_of(Array))
|
|
22
|
+
Graph.new.add_page RSPEC_URL
|
|
23
|
+
end
|
|
24
|
+
|
|
25
|
+
it "should create a node if it doesnt exist in the graph (raising exception Neography::NotFoundException)" do
|
|
26
|
+
# mock out Neography::Rest object to allow us to return desired data
|
|
27
|
+
neography = double(Neography::Rest, :create_node => [], :add_node_to_index => {})
|
|
28
|
+
allow(Neography::Rest).to receive(:new) {neography}
|
|
29
|
+
allow(neography).to receive(:get_node_index).and_raise(Neography::NotFoundException)
|
|
30
|
+
expect(neography).to receive(:get_node_index).with("page","url",RSPEC_URL)
|
|
31
|
+
expect(neography).to receive(:create_node).with({"url" => RSPEC_URL})
|
|
32
|
+
expect(neography).to receive(:add_node_to_index).with("page","url",RSPEC_URL,an_instance_of(Array))
|
|
33
|
+
Graph.new.add_page RSPEC_URL
|
|
34
|
+
end
|
|
35
|
+
|
|
36
|
+
it "should not create the node if the node exists" do
|
|
37
|
+
# mock out Neography::Rest object to allow us to return desired data
|
|
38
|
+
neography = double(Neography::Rest, :get_node_index => [], :create_node => [], :add_node_to_index => {})
|
|
39
|
+
allow(Neography::Rest).to receive(:new) {neography}
|
|
40
|
+
expect(neography).to receive(:get_node_index).with("page","url",RSPEC_URL)
|
|
41
|
+
expect(neography).to receive(:create_node).never
|
|
42
|
+
expect(neography).to receive(:add_node_to_index).never
|
|
43
|
+
Graph.new.add_page RSPEC_URL
|
|
44
|
+
end
|
|
45
|
+
|
|
46
|
+
it "should return the node array when called" do
|
|
47
|
+
# mock out Neography::Rest object to allow us to return desired data
|
|
48
|
+
neography = double(Neography::Rest, :get_node_index => nil, :create_node => [], :add_node_to_index => {})
|
|
49
|
+
allow(Neography::Rest).to receive(:new) {neography}
|
|
50
|
+
expect(neography).to receive(:get_node_index).with("page","url",RSPEC_URL)
|
|
51
|
+
expect(neography).to receive(:create_node).with({"url" => RSPEC_URL})
|
|
52
|
+
expect(neography).to receive(:add_node_to_index).with("page","url",RSPEC_URL,an_instance_of(Array))
|
|
53
|
+
expect(Graph.new.add_page RSPEC_URL).to be_an(Array)
|
|
54
|
+
end
|
|
55
|
+
end
|
|
56
|
+
|
|
57
|
+
describe "#create_relationship" do
|
|
58
|
+
it "should create relationship between nodes" do
|
|
59
|
+
# mock out Neography::Rest object to allow us to return desired data
|
|
60
|
+
neography = double(Neography::Rest, :create_relationship => {})
|
|
61
|
+
allow(Neography::Rest).to receive(:new) {neography}
|
|
62
|
+
expect(neography).to receive(:create_relationship).with("links_to","https://dummy.com",RSPEC_URL)
|
|
63
|
+
Graph.new.create_relationship("links_to", "https://dummy.com", RSPEC_URL)
|
|
64
|
+
end
|
|
65
|
+
end
|
|
66
|
+
end
|
|
67
|
+
end
|
data/spec/page_spec.rb
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
1
|
+
require 'spec_helper'
|
|
2
|
+
|
|
3
|
+
module Creepycrawler
|
|
4
|
+
describe Page do
|
|
5
|
+
before :each do
|
|
6
|
+
@page = Page.new(RSPEC_URL)
|
|
7
|
+
end
|
|
8
|
+
|
|
9
|
+
describe "#new" do
|
|
10
|
+
it "should accept a url and return a page object" do
|
|
11
|
+
expect(@page).to be_an_instance_of Creepycrawler::Page
|
|
12
|
+
end
|
|
13
|
+
|
|
14
|
+
it "should raise error on bad url" do
|
|
15
|
+
expect { Page.new("http://?bad_uri") }.to raise_error
|
|
16
|
+
end
|
|
17
|
+
end
|
|
18
|
+
|
|
19
|
+
describe "#fetch" do
|
|
20
|
+
it "should return a nokogiri object" do
|
|
21
|
+
expect(@page.fetch).to be_a(Nokogiri::HTML::Document)
|
|
22
|
+
end
|
|
23
|
+
end
|
|
24
|
+
|
|
25
|
+
describe "#links" do
|
|
26
|
+
it "should return an array" do
|
|
27
|
+
dummy_page_link_array = [
|
|
28
|
+
"/1",
|
|
29
|
+
"/2",
|
|
30
|
+
"http://remote.com/3"
|
|
31
|
+
]
|
|
32
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
33
|
+
expect(@page.links).to be_an(Array)
|
|
34
|
+
end
|
|
35
|
+
|
|
36
|
+
it "should return three links" do
|
|
37
|
+
dummy_page_link_array = [
|
|
38
|
+
"/1",
|
|
39
|
+
"/2",
|
|
40
|
+
"http://remote.com/3"
|
|
41
|
+
]
|
|
42
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
43
|
+
expect(@page.links.length).to equal(3)
|
|
44
|
+
end
|
|
45
|
+
|
|
46
|
+
it "should not return links to itself or empty links" do
|
|
47
|
+
dummy_page_link_array = [
|
|
48
|
+
"/1",
|
|
49
|
+
"/2",
|
|
50
|
+
"http://remote.com/3",
|
|
51
|
+
"#",
|
|
52
|
+
""
|
|
53
|
+
]
|
|
54
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
55
|
+
expect(@page.links.length).to equal(3)
|
|
56
|
+
end
|
|
57
|
+
|
|
58
|
+
it "should convert relative to absolute links" do
|
|
59
|
+
dummy_page_link_array = [
|
|
60
|
+
"/1",
|
|
61
|
+
"/2",
|
|
62
|
+
"3/4",
|
|
63
|
+
"foo.html",
|
|
64
|
+
"http://remote.com/3"
|
|
65
|
+
]
|
|
66
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
67
|
+
expect(@page.links).to match_array(["#{RSPEC_URL}1", "#{RSPEC_URL}2", "http://remote.com/3", "#{RSPEC_URL}3/4", "#{RSPEC_URL}foo.html"])
|
|
68
|
+
end
|
|
69
|
+
|
|
70
|
+
it "should not pickup mailto links" do
|
|
71
|
+
dummy_page_link_array = [
|
|
72
|
+
"mailto:foo@example.com"
|
|
73
|
+
]
|
|
74
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
75
|
+
expect(@page.links).to be_empty
|
|
76
|
+
end
|
|
77
|
+
|
|
78
|
+
it "should not pickup ftp links" do
|
|
79
|
+
dummy_page_link_array = [
|
|
80
|
+
"ftp://example.com"
|
|
81
|
+
]
|
|
82
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
83
|
+
expect(@page.links).to be_empty
|
|
84
|
+
end
|
|
85
|
+
|
|
86
|
+
it "should not pickup links that execute javascript" do
|
|
87
|
+
dummy_page_link_array = [
|
|
88
|
+
"javascript:void(0)"
|
|
89
|
+
]
|
|
90
|
+
@page.body = Dummypage.new(dummy_page_link_array).body
|
|
91
|
+
expect(@page.links).to be_empty
|
|
92
|
+
end
|
|
93
|
+
end
|
|
94
|
+
end
|
|
95
|
+
end
|
data/spec/site_spec.rb
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
1
|
+
require 'spec_helper'
|
|
2
|
+
|
|
3
|
+
module Creepycrawler
|
|
4
|
+
describe Site do
|
|
5
|
+
before :each do
|
|
6
|
+
@site = Site.new(RSPEC_URL, :verbose => false, :graph_to_neo4j => false)
|
|
7
|
+
end
|
|
8
|
+
|
|
9
|
+
it "should accept options" do
|
|
10
|
+
@site = Site.new(RSPEC_URL, :foo => true)
|
|
11
|
+
expect(@site.options[:foo]).to be true
|
|
12
|
+
end
|
|
13
|
+
|
|
14
|
+
it "should allow the changing of default options" do
|
|
15
|
+
@site = Site.new(RSPEC_URL, :verbose => false)
|
|
16
|
+
expect(@site.options[:verbose]).to be false
|
|
17
|
+
end
|
|
18
|
+
|
|
19
|
+
describe "#new" do
|
|
20
|
+
|
|
21
|
+
it "should accept a url and return a site object" do
|
|
22
|
+
expect(@site).to be_an_instance_of Creepycrawler::Site
|
|
23
|
+
end
|
|
24
|
+
end
|
|
25
|
+
|
|
26
|
+
describe "#local?" do
|
|
27
|
+
|
|
28
|
+
it "should corectly recognize a local url" do
|
|
29
|
+
expect(@site.local?("#{RSPEC_URL}/foo")).to be true
|
|
30
|
+
end
|
|
31
|
+
|
|
32
|
+
it "should correctly recognize a non-local url" do
|
|
33
|
+
expect(@site.local?("http://non-local.com/")).to be false
|
|
34
|
+
end
|
|
35
|
+
end
|
|
36
|
+
|
|
37
|
+
describe "#crawl" do
|
|
38
|
+
|
|
39
|
+
it "should increment page_crawl_count with every indexed page" do
|
|
40
|
+
page = double(Creepycrawler::Page, :url => RSPEC_URL, :robots_disallowed? => false, :fetch => "", :links => [])
|
|
41
|
+
allow(Creepycrawler::Page).to receive(:new) {page}
|
|
42
|
+
expect(@site.crawl.page_crawl_count).to eq(1)
|
|
43
|
+
|
|
44
|
+
end
|
|
45
|
+
|
|
46
|
+
it "should obey robots.txt when not explicity ignored" do
|
|
47
|
+
page = double(Creepycrawler::Page, :url => RSPEC_URL, :robots_disallowed? => true, :fetch => "", :links => [])
|
|
48
|
+
allow(Creepycrawler::Page).to receive(:new) {page}
|
|
49
|
+
expect(@site.crawl.page_crawl_count).to eq(0)
|
|
50
|
+
end
|
|
51
|
+
|
|
52
|
+
it "should add each visited site to visited_queue" do
|
|
53
|
+
page = double(Creepycrawler::Page, :url => RSPEC_URL, :robots_disallowed? => true, :fetch => "", :links => [])
|
|
54
|
+
allow(Creepycrawler::Page).to receive(:new) {page}
|
|
55
|
+
expect(@site.crawl.visited_queue).to match_array([RSPEC_URL])
|
|
56
|
+
end
|
|
57
|
+
|
|
58
|
+
it "should terminate when max_page_crawl is reached" do
|
|
59
|
+
dummy_page_link_array = [
|
|
60
|
+
"/1",
|
|
61
|
+
"/2",
|
|
62
|
+
"/3",
|
|
63
|
+
]
|
|
64
|
+
dummy_page = Page.new(RSPEC_URL)
|
|
65
|
+
dummy_page.body = Dummypage.new(dummy_page_link_array).body
|
|
66
|
+
@site = Site.new(RSPEC_URL, :verbose => false, :max_page_crawl => 2, :graph_to_neo4j => false)
|
|
67
|
+
page = double(Creepycrawler::Page, :url => RSPEC_URL, :robots_disallowed? => false, :fetch => "", :links => dummy_page.links)
|
|
68
|
+
allow(Creepycrawler::Page).to receive(:new) {page}
|
|
69
|
+
expect(@site.crawl.page_crawl_count).to eq(2)
|
|
70
|
+
end
|
|
71
|
+
|
|
72
|
+
it "should not visit the same page twice" do
|
|
73
|
+
dummy_page_link_array = [
|
|
74
|
+
"/1",
|
|
75
|
+
"/2",
|
|
76
|
+
"/2",
|
|
77
|
+
]
|
|
78
|
+
dummy_page = Page.new(RSPEC_URL)
|
|
79
|
+
dummy_page.body = Dummypage.new(dummy_page_link_array).body
|
|
80
|
+
|
|
81
|
+
page = double(Creepycrawler::Page, :robots_disallowed? => false, :fetch => "", :links => dummy_page.links)
|
|
82
|
+
#allow(Creepycrawler::Page).to receive(:links) {["foo", "baz"]}
|
|
83
|
+
allow(Creepycrawler::Page).to receive(:new) do |arg|
|
|
84
|
+
# dynamically stub url to return url passed in initialization
|
|
85
|
+
allow(page).to receive(:url) {arg}
|
|
86
|
+
# return mock
|
|
87
|
+
page
|
|
88
|
+
end
|
|
89
|
+
expect(@site.crawl.page_crawl_count).to eq(3)
|
|
90
|
+
expect(@site.crawl.visited_queue).to match_array([RSPEC_URL, "#{RSPEC_URL}1", "#{RSPEC_URL}2"])
|
|
91
|
+
end
|
|
92
|
+
|
|
93
|
+
it "should not visit remote sites" do
|
|
94
|
+
dummy_page_link_array = [
|
|
95
|
+
"/1",
|
|
96
|
+
"http://remote.com/"
|
|
97
|
+
]
|
|
98
|
+
dummy_page = Page.new(RSPEC_URL)
|
|
99
|
+
dummy_page.body = Dummypage.new(dummy_page_link_array).body
|
|
100
|
+
page = double(Creepycrawler::Page, :robots_disallowed? => false, :fetch => "", :links => dummy_page.links)
|
|
101
|
+
allow(Creepycrawler::Page).to receive(:new) do |url|
|
|
102
|
+
# dynamically stub url to return url passed in initialization
|
|
103
|
+
allow(page).to receive(:url) {url}
|
|
104
|
+
# return mock
|
|
105
|
+
page
|
|
106
|
+
end
|
|
107
|
+
expect(@site.crawl.page_crawl_count).to eq(2)
|
|
108
|
+
expect(@site.crawl.visited_queue).to match_array([RSPEC_URL, "#{RSPEC_URL}1"])
|
|
109
|
+
end
|
|
110
|
+
|
|
111
|
+
it "should add url to broken_links when an exception is thrown" do
|
|
112
|
+
page = double(Creepycrawler::Page, :url => RSPEC_URL, :robots_disallowed? => false, :fetch => "")
|
|
113
|
+
allow(Creepycrawler::Page).to receive(:new) {page}
|
|
114
|
+
allow(page).to receive(:fetch).and_raise('404 site not found')
|
|
115
|
+
expect(@site.crawl.broken_links).to match_array([RSPEC_URL])
|
|
116
|
+
end
|
|
117
|
+
end
|
|
118
|
+
end
|
|
119
|
+
end
|
data/spec/spec_helper.rb
ADDED
metadata
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
1
|
+
--- !ruby/object:Gem::Specification
|
|
2
|
+
name: creepy-crawler
|
|
3
|
+
version: !ruby/object:Gem::Version
|
|
4
|
+
version: 1.0.0
|
|
5
|
+
platform: ruby
|
|
6
|
+
authors:
|
|
7
|
+
- Ryan Grothouse
|
|
8
|
+
autorequire:
|
|
9
|
+
bindir: bin
|
|
10
|
+
cert_chain: []
|
|
11
|
+
date: 2014-05-10 00:00:00.000000000 Z
|
|
12
|
+
dependencies:
|
|
13
|
+
- !ruby/object:Gem::Dependency
|
|
14
|
+
name: bundler
|
|
15
|
+
requirement: !ruby/object:Gem::Requirement
|
|
16
|
+
requirements:
|
|
17
|
+
- - ~>
|
|
18
|
+
- !ruby/object:Gem::Version
|
|
19
|
+
version: '1.5'
|
|
20
|
+
type: :development
|
|
21
|
+
prerelease: false
|
|
22
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
23
|
+
requirements:
|
|
24
|
+
- - ~>
|
|
25
|
+
- !ruby/object:Gem::Version
|
|
26
|
+
version: '1.5'
|
|
27
|
+
- !ruby/object:Gem::Dependency
|
|
28
|
+
name: rspec
|
|
29
|
+
requirement: !ruby/object:Gem::Requirement
|
|
30
|
+
requirements:
|
|
31
|
+
- - ~>
|
|
32
|
+
- !ruby/object:Gem::Version
|
|
33
|
+
version: '2.14'
|
|
34
|
+
type: :development
|
|
35
|
+
prerelease: false
|
|
36
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
37
|
+
requirements:
|
|
38
|
+
- - ~>
|
|
39
|
+
- !ruby/object:Gem::Version
|
|
40
|
+
version: '2.14'
|
|
41
|
+
- !ruby/object:Gem::Dependency
|
|
42
|
+
name: rspec-core
|
|
43
|
+
requirement: !ruby/object:Gem::Requirement
|
|
44
|
+
requirements:
|
|
45
|
+
- - ~>
|
|
46
|
+
- !ruby/object:Gem::Version
|
|
47
|
+
version: '2.14'
|
|
48
|
+
type: :development
|
|
49
|
+
prerelease: false
|
|
50
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
51
|
+
requirements:
|
|
52
|
+
- - ~>
|
|
53
|
+
- !ruby/object:Gem::Version
|
|
54
|
+
version: '2.14'
|
|
55
|
+
- !ruby/object:Gem::Dependency
|
|
56
|
+
name: rake
|
|
57
|
+
requirement: !ruby/object:Gem::Requirement
|
|
58
|
+
requirements:
|
|
59
|
+
- - ~>
|
|
60
|
+
- !ruby/object:Gem::Version
|
|
61
|
+
version: '0.8'
|
|
62
|
+
type: :runtime
|
|
63
|
+
prerelease: false
|
|
64
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
65
|
+
requirements:
|
|
66
|
+
- - ~>
|
|
67
|
+
- !ruby/object:Gem::Version
|
|
68
|
+
version: '0.8'
|
|
69
|
+
- !ruby/object:Gem::Dependency
|
|
70
|
+
name: neography
|
|
71
|
+
requirement: !ruby/object:Gem::Requirement
|
|
72
|
+
requirements:
|
|
73
|
+
- - ~>
|
|
74
|
+
- !ruby/object:Gem::Version
|
|
75
|
+
version: '1.4'
|
|
76
|
+
- - ! '>='
|
|
77
|
+
- !ruby/object:Gem::Version
|
|
78
|
+
version: 1.4.1
|
|
79
|
+
type: :runtime
|
|
80
|
+
prerelease: false
|
|
81
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
82
|
+
requirements:
|
|
83
|
+
- - ~>
|
|
84
|
+
- !ruby/object:Gem::Version
|
|
85
|
+
version: '1.4'
|
|
86
|
+
- - ! '>='
|
|
87
|
+
- !ruby/object:Gem::Version
|
|
88
|
+
version: 1.4.1
|
|
89
|
+
- !ruby/object:Gem::Dependency
|
|
90
|
+
name: nokogiri
|
|
91
|
+
requirement: !ruby/object:Gem::Requirement
|
|
92
|
+
requirements:
|
|
93
|
+
- - ~>
|
|
94
|
+
- !ruby/object:Gem::Version
|
|
95
|
+
version: '1.6'
|
|
96
|
+
- - ! '>='
|
|
97
|
+
- !ruby/object:Gem::Version
|
|
98
|
+
version: 1.6.1
|
|
99
|
+
type: :runtime
|
|
100
|
+
prerelease: false
|
|
101
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
102
|
+
requirements:
|
|
103
|
+
- - ~>
|
|
104
|
+
- !ruby/object:Gem::Version
|
|
105
|
+
version: '1.6'
|
|
106
|
+
- - ! '>='
|
|
107
|
+
- !ruby/object:Gem::Version
|
|
108
|
+
version: 1.6.1
|
|
109
|
+
- !ruby/object:Gem::Dependency
|
|
110
|
+
name: addressable
|
|
111
|
+
requirement: !ruby/object:Gem::Requirement
|
|
112
|
+
requirements:
|
|
113
|
+
- - ~>
|
|
114
|
+
- !ruby/object:Gem::Version
|
|
115
|
+
version: '2.3'
|
|
116
|
+
- - ! '>='
|
|
117
|
+
- !ruby/object:Gem::Version
|
|
118
|
+
version: 2.3.6
|
|
119
|
+
type: :runtime
|
|
120
|
+
prerelease: false
|
|
121
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
122
|
+
requirements:
|
|
123
|
+
- - ~>
|
|
124
|
+
- !ruby/object:Gem::Version
|
|
125
|
+
version: '2.3'
|
|
126
|
+
- - ! '>='
|
|
127
|
+
- !ruby/object:Gem::Version
|
|
128
|
+
version: 2.3.6
|
|
129
|
+
- !ruby/object:Gem::Dependency
|
|
130
|
+
name: open_uri_redirections
|
|
131
|
+
requirement: !ruby/object:Gem::Requirement
|
|
132
|
+
requirements:
|
|
133
|
+
- - '='
|
|
134
|
+
- !ruby/object:Gem::Version
|
|
135
|
+
version: 0.1.4
|
|
136
|
+
type: :runtime
|
|
137
|
+
prerelease: false
|
|
138
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
139
|
+
requirements:
|
|
140
|
+
- - '='
|
|
141
|
+
- !ruby/object:Gem::Version
|
|
142
|
+
version: 0.1.4
|
|
143
|
+
- !ruby/object:Gem::Dependency
|
|
144
|
+
name: webrobots
|
|
145
|
+
requirement: !ruby/object:Gem::Requirement
|
|
146
|
+
requirements:
|
|
147
|
+
- - ~>
|
|
148
|
+
- !ruby/object:Gem::Version
|
|
149
|
+
version: '0.1'
|
|
150
|
+
- - ! '>='
|
|
151
|
+
- !ruby/object:Gem::Version
|
|
152
|
+
version: 0.1.1
|
|
153
|
+
type: :runtime
|
|
154
|
+
prerelease: false
|
|
155
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
156
|
+
requirements:
|
|
157
|
+
- - ~>
|
|
158
|
+
- !ruby/object:Gem::Version
|
|
159
|
+
version: '0.1'
|
|
160
|
+
- - ! '>='
|
|
161
|
+
- !ruby/object:Gem::Version
|
|
162
|
+
version: 0.1.1
|
|
163
|
+
- !ruby/object:Gem::Dependency
|
|
164
|
+
name: trollop
|
|
165
|
+
requirement: !ruby/object:Gem::Requirement
|
|
166
|
+
requirements:
|
|
167
|
+
- - ~>
|
|
168
|
+
- !ruby/object:Gem::Version
|
|
169
|
+
version: '2.0'
|
|
170
|
+
type: :runtime
|
|
171
|
+
prerelease: false
|
|
172
|
+
version_requirements: !ruby/object:Gem::Requirement
|
|
173
|
+
requirements:
|
|
174
|
+
- - ~>
|
|
175
|
+
- !ruby/object:Gem::Version
|
|
176
|
+
version: '2.0'
|
|
177
|
+
description: web crawler that generates a sitemap to a neo4j database. It will also
|
|
178
|
+
store broken_links and total number of pages on site
|
|
179
|
+
email: rgrothouse@gmail.com
|
|
180
|
+
executables: []
|
|
181
|
+
extensions: []
|
|
182
|
+
extra_rdoc_files: []
|
|
183
|
+
files:
|
|
184
|
+
- .gitignore
|
|
185
|
+
- .travis.yml
|
|
186
|
+
- DOCKER.md
|
|
187
|
+
- Gemfile
|
|
188
|
+
- Gemfile.lock
|
|
189
|
+
- README.md
|
|
190
|
+
- Rakefile
|
|
191
|
+
- docker/Dockerfile
|
|
192
|
+
- docker/neo4j-server.properties
|
|
193
|
+
- docker/startup.sh
|
|
194
|
+
- examples/crawl.rb
|
|
195
|
+
- examples/output_map.png
|
|
196
|
+
- lib/creepy-crawler.rb
|
|
197
|
+
- lib/creepy-crawler/graph.rb
|
|
198
|
+
- lib/creepy-crawler/page.rb
|
|
199
|
+
- lib/creepy-crawler/site.rb
|
|
200
|
+
- spec/creepy-crawler_spec.rb
|
|
201
|
+
- spec/dummypage_helper.rb
|
|
202
|
+
- spec/graph_spec.rb
|
|
203
|
+
- spec/page_spec.rb
|
|
204
|
+
- spec/site_spec.rb
|
|
205
|
+
- spec/spec_helper.rb
|
|
206
|
+
homepage: https://github.com/udryan10/creepy-crawler
|
|
207
|
+
licenses:
|
|
208
|
+
- MIT
|
|
209
|
+
metadata: {}
|
|
210
|
+
post_install_message:
|
|
211
|
+
rdoc_options: []
|
|
212
|
+
require_paths:
|
|
213
|
+
- lib
|
|
214
|
+
required_ruby_version: !ruby/object:Gem::Requirement
|
|
215
|
+
requirements:
|
|
216
|
+
- - ! '>='
|
|
217
|
+
- !ruby/object:Gem::Version
|
|
218
|
+
version: 1.9.3
|
|
219
|
+
required_rubygems_version: !ruby/object:Gem::Requirement
|
|
220
|
+
requirements:
|
|
221
|
+
- - ! '>='
|
|
222
|
+
- !ruby/object:Gem::Version
|
|
223
|
+
version: '0'
|
|
224
|
+
requirements: []
|
|
225
|
+
rubyforge_project:
|
|
226
|
+
rubygems_version: 2.2.2
|
|
227
|
+
signing_key:
|
|
228
|
+
specification_version: 4
|
|
229
|
+
summary: web crawler that generates a sitemap
|
|
230
|
+
test_files:
|
|
231
|
+
- spec/creepy-crawler_spec.rb
|
|
232
|
+
- spec/dummypage_helper.rb
|
|
233
|
+
- spec/graph_spec.rb
|
|
234
|
+
- spec/page_spec.rb
|
|
235
|
+
- spec/site_spec.rb
|
|
236
|
+
- spec/spec_helper.rb
|